- The Benefits of Poetry for Professionals (HBR) — Harman Industries founder Sidney Harman once told The New York Times, “I used to tell my senior staff to get me poets as managers. Poets are our original systems thinkers. They look at our most complex environments and they reduce the complexity to something they begin to understand.”
- First Few Milliseconds of an HTTPS Connection — far more than you ever wanted to know about how HTTPS connections are initiated.
- Google Earth Engine — Develop, access and run algorithms on the full Earth Engine data archive, all using Google’s parallel processing platform. (via Nelson Minar)
- 3D Printing Popup Store Opens in NYC (Makezine Blog) — MAKE has partnered with 3DEA, a pop up 3D printing emporium in New York City’s fashion district. The store will sell printers and 3D printed objects as well as offer a lineup of classes, workshops, and presentations from the likes of jewelry maker Kevin Wei, 3D printing artist Josh Harker, and Shapeways’ Duann Scott. This. is. awesome!
"data mining" entries

Strata Week: Big data’s big future
Big data in 2013, and beyond; the Sunlight Foundation's new data mining app; and the growth of our planet's central nervous system.
Here are a few stories from the data space that caught my attention this week.
Big data will continue to be a big deal
 “Big data” became something of a buzz phrase in 2012, with its role in the US Presidential election, and businesses large and small starting to realize the benefits and challenges of mountains upon zettabytes of data — so much so that NPR’s linguist contributor Geoff Nunberg thinks it should have been the phrase of the year.
“Big data” became something of a buzz phrase in 2012, with its role in the US Presidential election, and businesses large and small starting to realize the benefits and challenges of mountains upon zettabytes of data — so much so that NPR’s linguist contributor Geoff Nunberg thinks it should have been the phrase of the year.
Nunberg says that though “it didn’t get the wide public exposure given to items like ‘frankenstorm,’ ‘fiscal cliff‘ and YOLO,” and might not have been “as familiar to many people as ‘Etch A Sketch’ and ’47 percent'” were during the election, big data has become a phenomenon affecting our lives: “It’s responsible for a lot of our anxieties about intrusions on our privacy, whether from the government’s anti-terrorist data sweeps or the ads that track us as we wander around the Web.” He also notes that big data has transformed statistics into “a sexy major” and predicts the term will long outlast “Gangnam Style.” (You can read Nunberg’s full case for big data at NPR.)

Four short links: 5 December 2012
Poetry for Professionals, HTTPS Setup, Geodata Mining, and 3D Popup Print Shops
Strata Week: Big data’s daily influence
Big data's broad effect on our world, myriad uses for traffic data, and Obama's big data practice vs. policy.
Here are a few stories from the data space that caught my attention this week.
How big data is transforming just about everything
 Professor John Naughton took a look this week at how big data is transforming various industries that affect our daily lives.
Professor John Naughton took a look this week at how big data is transforming various industries that affect our daily lives.
He highlights finance, of course, which he says has been “pathologically mathematised;” marketing, for which there is more data about human behavior than we’ve ever had; and the very broad category of science. Naughton notes that researchers used to conjure up theories and look to data to support or refute; now, researchers turn to data to find patterns and connections that might inspire new theories. Naughton also looks at medicine, which is just on the brink of delving into the big data realm. He writes:
“Last week’s news about how Cambridge researchers stopped an MRSA outbreak affecting 12 babies in the Rosie Hospital by rapidly sequencing the genome of the bacteria illustrates how medicine has become a data-intensive field. Even a few years ago, the resources required to achieve this would have involved a roomful of computers and upwards of a week.”
Naughton addresses the use of big data in sports as well, speculating that baseball has been the sport most transformed by data. He’ll likely find agreement there. Barry Eggers goes into depth on the dramatic effect big data is having on baseball over at TechCrunch. He notes that simple data analysis of statistics, which baseball has embraced since its beginnings, has evolved into gathering mountains of unstructured data and employing Hadoop to gain new and better insights from data that isn’t part of the structured game information. Eggers writes:
“By having his data scientist run a Hadoop job before every game, [San Francisco Giants manager] Bruce Bochy can not only make an informed decision about where to locate a 3-1 Matt Cain pitch to Prince Fielder, but he can also predict how and where the ball might be hit, how much ground his infielders and outfielders can cover on such a hit, and thus determine where to shift his defense. Taken one step further, it’s not hard to imagine a day where managers like Bochy have their locker room data scientist run real-time, in-game analytics using technologies like Cassandra, Hbase, Drill, and Impala.”
Strata Week: Data mining for votes
Candidates are data mining behind the scenes, data mining gets a PR campaign, Google faces privacy policy issues, and Hadoop and BI.
Here are a few stories from the data space that caught my attention this week.
Presidential candidates are mining your data
Data is playing an unprecedented role in the US presidential election this year. The two presidential campaigns have access to personal voter data “at a scale never before imagined,” reports Charles Duhigg at the New York Times. The candidate camps are using personal data in polling calls, accessing such details as “whether voters may have visited pornography Web sites, have homes in foreclosure, are more prone to drink Michelob Ultra than Corona or have gay friends or enjoy expensive vacations,” Duhigg writes. He reports that both campaigns emphasized they were committed to protecting voter privacy, but notes:
“Officials for both campaigns acknowledge that many of their consultants and vendors draw data from an array of sources — including some the campaigns themselves have not fully scrutinized.”
A Romney campaign official told Duhigg: “You don’t want your analytical efforts to be obvious because voters get creeped out. A lot of what we’re doing is behind the scenes.”
The “behind the scenes” may be enough in itself to creep people out. These sorts of situations are starting to tarnish the image of the consumer data-mining industry, and a Manhattan trade group, the Direct Marketing Association, is launching a public relations campaign — the “Data-Driven Marketing Institute” — to smooth things over before government regulators get involved. Natasha Singer reports at the New York Times:
“According to a statement, the trade group intends to promote such targeted marketing to lawmakers and the public ‘with the goal of preventing needless regulation or enforcement that could severely hamper consumer marketing and stifle innovation’ as well as ‘tamping down unfavorable media attention.’ As part of the campaign, the group plans to finance academic research into the industry’s economic impact, said Linda A. Woolley, the acting chief executive of the Direct Marketing Association.”
One of the biggest issues, Singer notes, is that people want control over their data. Chuck Teller, founder of Catalog Choice, told Singer that in a recent survey conducted by his company, 67% of people responded that they wanted to see the data collected about them by data brokers and 78% said they wanted the ability to opt out of the sale and distribution of that data.
Four short links: 4 October 2012
Vannevar Bush, Topic Transparency, Ancient Maps, and Concussion Sensors
- As We May Think (Vannevar Bush) — incredibly prescient piece he wrote for The Atlantic in 1945.
- Transparency and Topic Models (YouTube) — a talk from DataGotham 2012, by Hanna Wallach. She uses latent Dirichlet allocation topic models to mine text data in declassified documents where the metadata are useless. She’s working on predicting classification durations (AWESOME!). (via Matt Biddulph)
- Slippy Map of the Ancient World — this. is. so. cool!
- Technology in the NFL — X2IMPACT’s Concussion Management System (CMS) is a great example of this trend. CMS, when combined with a digital mouth guard, also made by X2, enables coaches to see head impact data in real-time and asses concussions through monitoring the accelerometers in a players mouth guard. That data helps teams to decide whether to keep a player on the field or take them off for their own safety. Insert referee joke here.
Four short links: 30 August 2012
Decoding ToS, Impact Factors are Nonsense, Crappy Open Source Code, and Data Mining History
- TOS;DR — terms of service rendered comprehensible. “Make the hard stuff easy” is a great template for good ideas, and this just nails it.
- Sick of Impact Factors — typically only 15% of the papers in a journal account for half the total citations. Therefore only this minority of the articles has more than the average number of citations denoted by the journal impact factor. Take a moment to think about what that means: the vast majority of the journal’s papers — fully 85% — have fewer citations than the average. The impact factor is a statistically indefensible indicator of journal performance; it flatters to deceive, distributing credit that has been earned by only a small fraction of its published papers. (via Sci Blogs)
- A Generation Lost in the Bazaar (ACM) — Today’s Unix/Posix-like operating systems, even including IBM’s z/OS mainframe version, as seen with 1980 eyes are identical; yet the 31,085 lines of configure for libtool still check if and exist, even though the Unixen, which lacked them, had neither sufficient memory to execute libtool nor disks big enough for its 16-MB source code. […] That is the sorry reality of the bazaar Raymond praised in his book: a pile of old festering hacks, endlessly copied and pasted by a clueless generation of IT “professionals” who wouldn’t recognize sound IT architecture if you hit them over the head with it. It is hard to believe today, but under this embarrassing mess lies the ruins of the beautiful cathedral of Unix, deservedly famous for its simplicity of design, its economy of features, and its elegance of execution. (Sic transit gloria mundi, etc.)
- History as Science (Nature) — Turchin and his allies contend that the time is ripe to revisit general laws, thanks to tools such as nonlinear mathematics, simulations that can model the interactions of thousands or millions of individuals at once, and informatics technologies for gathering and analysing huge databases of historical information.
Four short links: 23 August 2012
Computational Social Science, Infrastructure Drives Design, Narcodrones Imminent, and Muscle Memory
- Computational Social Science (Nature) — Facebook and Twitter data drives social science analysis. (via Vaughan Bell)
- The Single Most Important Object in the Global Economy (Slate) — Companies like Ikea have literally designed products around pallets: Its “Bang” mug, notes Colin White in his book Strategic Management, has had three redesigns, each done not for aesthetics but to ensure that more mugs would fit on a pallet (not to mention in a customer’s cupboard). (via Boing Boing)
- Narco Ultralights (Wired) — it’s just a matter of time until there are no humans on the ultralights. Remote-controlled narcodrones can’t be far away.
- Shortcut Foo — a typing tutor for editors, photoshop, and the commandline, to build muscle memory of frequently-used keystrokes. Brilliant! (via Irene Ros)

Mining the astronomical literature
A clever data project shows the promise of open and freely accessible academic literature.
There is a huge debate right now about making academic literature freely accessible and moving toward open access. But what would be possible if people stopped talking about it and just dug in and got on with it?
NASA’s Astrophysics Data System (ADS), hosted by the Smithsonian Astrophysical Observatory (SAO), has quietly been working away since the mid-’90s. Without much, if any, fanfare amongst the other disciplines, it has moved astronomers into a world where access to the literature is just a given. It’s something they don’t have to think about all that much.
The ADS service provides access to abstracts for virtually all of the astronomical literature. But it also provides access to the full text of more than half a million papers, going right back to the start of peer-reviewed journals in the 1800s. The service has links to online data archives, along with reference and citation information for each of the papers, and it’s all searchable and downloadable.
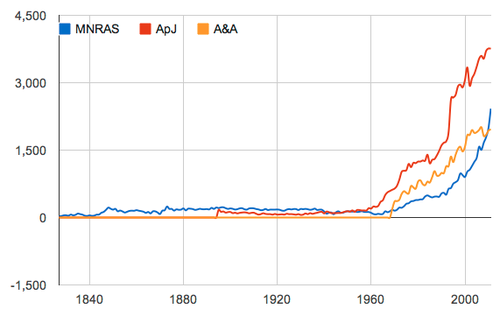
Number of papers published in the three main astronomy journals each year. CREDIT: Robert Simpson
The existence of the ADS, along with the arXiv pre-print server, has meant that most astronomers haven’t seen the inside of a brick-built library since the late 1990s.
It also makes astronomy almost uniquely well placed for interesting data mining experiments, experiments that hint at what the rest of academia could do if they followed astronomy’s lead. The fact that the discipline’s literature has been scanned, archived, indexed and catalogued, and placed behind a RESTful API makes it a treasure trove, both for hypothesis generation and sociological research.
Four short links: 24 May 2012
Maker Tribe, Concept Mapping, Magic Wand, and Site Performance Matters
- Last Saturday My Son Found His People at the Maker Faire — aww to the power of INFINITY.
- Dictionaries Linking Words to Concepts (Google Research) — Wikipedia entries for concepts, text strings from searches and the oppressed workers down the Text Mines, and a count indicating how often the two were related.
- Magic Wand (Kickstarter) — I don’t want the game, I want a Bluetooth magic wand. I don’t want to click the OK button, I want to wave a wand and make it so! (via Pete Warden)
- E-Commerce Performance (Luke Wroblewski) — If a page load takes more than two seconds, 40% are likely to abandon that site. This is why you should follow Steve Souders like a hawk: if your site is slower than it could be, you’re leaving money on the table.
Four short links: 8 February 2012
Text Mining, Unstoppable Sociality, Unicode Fun, and Scholarly Publishing
- Mavuno — an open source, modular, scalable text mining toolkit built upon Hadoop. (Apache-licensed)
- Cow Clicker — Wired profile of Cowclicker creator Ian Bogost. I was impressed by Cow Clickers […] have turned what was intended to be a vapid experience into a source of camaraderie and creativity. People create communities around social activities, even when they are antisocial. (via BoingBoing)
- Unicode Has a Pile of Poo Character (BoingBoing) — this is perfect.
- The Research Works Act and the Breakdown of Mutual Incomprehension (Cameron Neylon) — an excellent summary of how researchers and publishers view each other and their place in the world.