"data processing" entries

The world beyond batch: Streaming 101
A high-level tour of modern data-processing concepts.

Editor’s note: This is the first post in a two-part series about the evolution of data processing, with a focus on streaming systems, unbounded data sets, and the future of big data. See part two.
Streaming data processing is a big deal in big data these days, and for good reasons. Amongst them:
- Businesses crave ever more timely data, and switching to streaming is a good way to achieve lower latency.
- The massive, unbounded data sets that are increasingly common in modern business are more easily tamed using a system designed for such never-ending volumes of data.
- Processing data as they arrive spreads workloads out more evenly over time, yielding more consistent and predictable consumption of resources.
Despite this business-driven surge of interest in streaming, the majority of streaming systems in existence remain relatively immature compared to their batch brethren, which has resulted in a lot of exciting, active development in the space recently.
As someone who’s worked on massive-scale streaming systems at Google for the last five+ years (MillWheel, Cloud Dataflow), I’m delighted by this streaming zeitgeist, to say the least. I’m also interested in making sure that folks understand everything that streaming systems are capable of and how they are best put to use, particularly given the semantic gap that remains between most existing batch and streaming systems. To that end, the fine folks at O’Reilly have invited me to contribute a written rendition of my Say Goodbye to Batch talk from Strata + Hadoop World London 2015. Since I have quite a bit to cover, I’ll be splitting this across two separate posts:
- Streaming 101: This first post will cover some basic background information and clarify some terminology before diving into details about time domains and a high-level overview of common approaches to data processing, both batch and streaming.
- The Dataflow Model: The second post will consist primarily of a whirlwind tour of the unified batch + streaming model used by Cloud Dataflow, facilitated by a concrete example applied across a diverse set of use cases. After that, I’ll conclude with a brief semantic comparison of existing batch and streaming systems.
So, long-winded introductions out of the way, let’s get nerdy. Read more…

Prepare distribution patches with gawk
Exploring the power and sophistication of awk.

I maintain GNU Awk. As part of making releases, I have to create a patch script to convert the file tree of the previous release into the current one. This means writing rm commands to remove any files that have been removed. This is fairly straightforward using tools like find, sort, and comm.
However, for the 4.1.2 release, I also changed the permissions (mode) on some files. I want to create chmod commands to update these files’ permission settings as well. This is a little harder, so I decided to write an awk script that will do this for me.
Let’s take a look at some of the sophistication and control you can achieve using awk, such as recursion, the use of arrays of arrays, and extension functions for using operating system facilities.
This script, comptrees.awk, uses the fts() extension function to do the heavy lifting. This function walks file trees, building up a representation of those trees using gawk‘s arrays of arrays.

Questioning the Lambda Architecture
The Lambda Architecture has its merits, but alternatives are worth exploring.
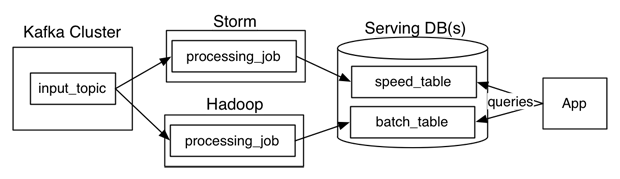
Nathan Marz wrote a popular blog post describing an idea he called the Lambda Architecture (“How to beat the CAP theorem“). The Lambda Architecture is an approach to building stream processing applications on top of MapReduce and Storm or similar systems. This has proven to be a surprisingly popular idea, with a dedicated website and an upcoming book. Since I’ve been involved in building out the real-time data processing infrastructure at LinkedIn using Kafka and Samza, I often get asked about the Lambda Architecture. I thought I would describe my thoughts and experiences.
What is a Lambda Architecture and how do I become one?
The Lambda Architecture looks something like this:

Wearables and the immediacy of communication
Wearables can help bridge the gap between batch and real-time communications.
 I drown in e-mail, which is a common affliction. With meetings during the day, I need to defer e-mail to breaks between meetings or until the evening, which prevents it from being a real-time communications medium.
I drown in e-mail, which is a common affliction. With meetings during the day, I need to defer e-mail to breaks between meetings or until the evening, which prevents it from being a real-time communications medium.
Everybody builds a communication “bubble” around themselves, sometimes by design and sometimes by necessity. Robert Reich’s memoir Locked in the Cabinet describes the process of staffing his office and, ultimately, building that bubble. He resists, but eventually succumbs to the necessity of filtering communications when managing such a large organization.
One of the reasons I’m fascinated by wearable technology is that it is one way of bridging the gap between batch and real-time communications. Wearable technology has smaller screens, and many early products use low-power screen technology that lacks the ability to display vibrant colors. Some may view these qualities as drawbacks, but in return, it is possible to display critical information in an easily viewable — and immediate — way. Read more…

Strata Week: There's money in data sifting
DataSift lands funding, popping the hood on Google Plus, data products for education
In the latest Strata Week: DataSift's access to the Twitter firehose proves compelling for investors, the inner workings of Google Plus are revealed, and contestants crank out apps for education.