"Unified Logging Layer" entries

The log: The lifeblood of your data pipeline
Why every data pipeline should have a Unified Logging Layer.
The value of log data for business is unimpeachable. On every level of the organization, the question, “How are we doing?” is answered, ultimately, by log data. Error logs tell developers what went wrong in their applications. User event logs give product managers insights on usage. If the CEO has a question about the next quarter’s revenue forecast, the answer ultimately comes from payment/CRM logs. In this post, I explore the ideal frameworks for collecting and parsing logs.
Apache Kafka Architect Jay Kreps wrote a wonderfully crisp survey on log data. He begins with the simple question of “What is the log?” and elucidates its key role in thinking about data pipelines. Jay’s piece focuses mostly on storing and processing log data. Here, I focus on the steps before storing and processing.
Changing the way we think about log data
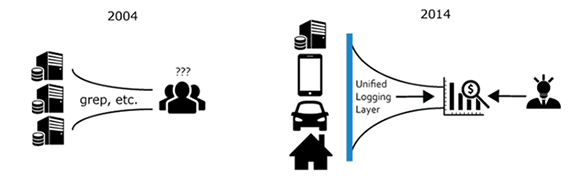
The old paradigm — machines to humans, and the new — machines to machines. Image courtesy of Kiyoto Tamura.
Over the last decade, the primary consumer of log data shifted from humans to machines.
Software engineers still read logs, especially when their software behaves in an unexpected manner. However, in terms of “bytes processed,” humans account for a tiny fraction of the total consumption. Much of today’s “big data” is some form of log data, and businesses run tens of thousands of servers to parse and mine these logs to gain competitive edge. Read more…