
Over the weekend the hacker group Antisec released one million UDID records that they claim to have obtained from an FBI laptop using a Java vulnerability. In reply the FBI stated:
The FBI is aware of published reports alleging that an FBI laptop was compromised and private data regarding Apple UDIDs was exposed. At this time there is no evidence indicating that an FBI laptop was compromised or that the FBI either sought or obtained this data.
Of course that statement leaves a lot of leeway. It could be the agent’s personal laptop, and the data may well have been “property” of an another agency. The wording doesn’t even explicitly rule out the possibility that this was an agency laptop, they just say that right now they don’t have any evidence to suggest that it was.
This limited data release doesn’t have much impact, but the possible release of the full dataset, which is claimed to include names, addresses, phone numbers and other identifying information, is far more worrying.
While there are some almost dismissing the issue out of hand, the real issues here are: Where did the data originate? Which devices did it come from and what kind of users does this data represent? Is this data from a cross-section of the population, or a specifically targeted demographic? Does it originate within the law enforcement community, or from an external developer? What was the purpose of the data, and why was it collected?
With conflicting stories from all sides, the only thing we can believe is the data itself. The 40-character strings in the release at least look like UDID numbers, and anecdotally at least we have a third-party confirmation that this really is valid UDID data. We therefore have to proceed at this point as if this is real data. While there is a possibility that some, most, or all of the data is falsified, that’s looking unlikely from where we’re standing standing at the moment.
With that as the backdrop, the first action I took was to check the released data for my own devices and those of family members. Of the nine iPhones, iPads and iPod Touch devices kicking around my house, none of the UDIDs are in the leaked database. Of course there isn’t anything to say that they aren’t amongst the other 11 million UDIDs that haven’t been released.
With that done, I broke down the distribution of leaked UDID numbers by device type. Interestingly, considering the number of iPhones in circulation compared to the number of iPads, the bulk of the UDIDs were self-identified as originating on an iPad.
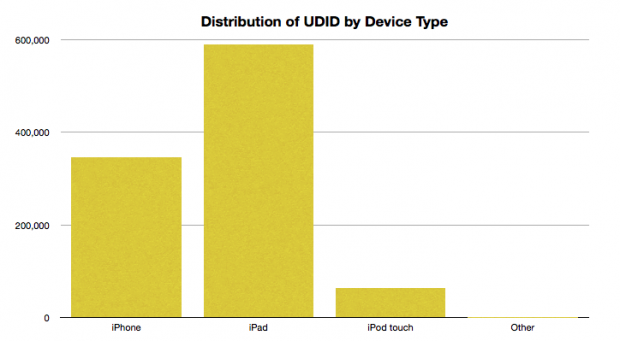
Distribution of UDID by device type
What does that mean? Here’s one theory: If the leak originated from a developer rather than directly from Apple, and assuming that this subset of data is a good cross-section on the total population, and assuming that the leaked data originated with a single application … then the app that harvested the data is likely a Universal application (one that runs on both the iPhone and the iPad) that is mostly used on the iPad rather than on the iPhone.
The very low numbers of iPod Touch users might suggest either demographic information, or that the application is not widely used by younger users who are the target demographic for the iPod Touch, or alternatively perhaps that the application is most useful when a cellular data connection is present.
The next thing to look at, as the only field with unconstrained text, was the Device Name data. That particular field contains a lot of first names, e.g. “Aaron’s iPhone,” so roughly speaking the distribution of first letters in the this field should give a decent clue as to the geographical region of origin of the leaked list of UDIDs. This distribution is of course going to be different depending on the predominant language in the region.
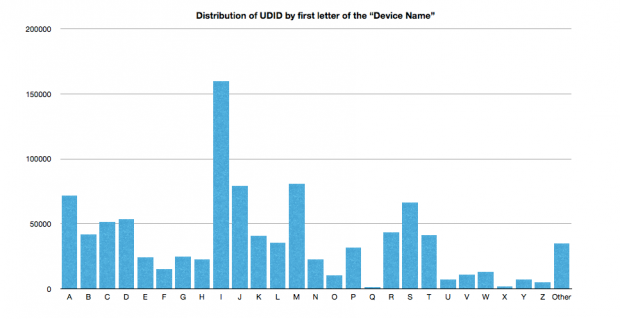
Distribution of UDID by the first letter of the “Device Name” field
The immediate stand out from this distribution is the predominance of device name strings starting with the letter “i.” This can be ascribed to people who don’t have their own name prepended to the Device Name string, and have named their device “iPhone,” “iPad” or “iPod Touch.”
The obvious next step was to compare this distribution with the relative frequency of first letters in words in the English language.

Comparing the distribution of UDID by first letter of the “Device Name” field against the relative frequencies of the first letters of a word in the English language
The spike for the letter “i” dominated the data, so the next step was to do some rough and ready data cleaning.
I dropped all the Device Name strings that started with the string “iP.” That cleaned out all those devices named “iPhone,” “iPad” and “iPod Touch.” Doing that brought the number of device names starting with an “i” down from 159,925 to just 13,337. That’s a bit more reasonable.
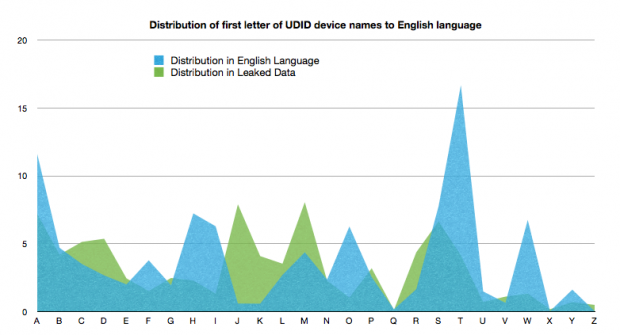
Comparing the distribution of UDID by first letter of the “Device Name” field, ignoring all names that start with the string “iP,” against the relative frequencies of the first letters of a word in the English language
I had a slight over-abundance of “j,” although that might not be statistically significant. However, the stand out was that there was a serious under-abundance of strings starting with the letter “t,” which is interesting. Additionally, with my earlier data cleaning I also had a slight under-abundance of “i,” which suggested I may have been too enthusiastic about cleaning the data.
Looking at the relative frequency of letters in languages other than English it’s notable that amongst them Spanish has a much lower frequency of the use of “t.”
As the de facto second language of the United States, Spanish is the obvious next choice to investigate. If the devices are predominantly Spanish in origin then this could solve the problem introduced by our data cleaning. As Marcos Villacampa noted in a tweet, in Spanish you would say “iPhone de Mark” rather than “Mark’s iPhone.”
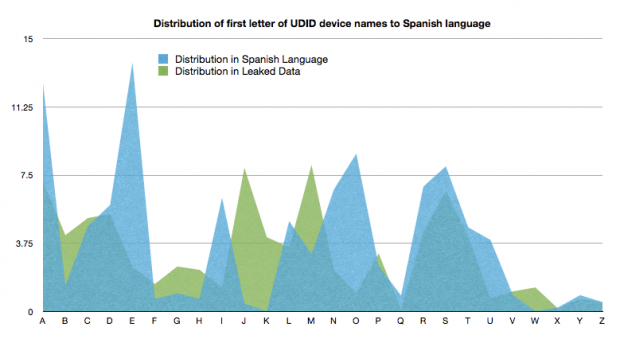
Comparing the distribution of UDID by first letter of the “Device Name” field, ignoring all names that start with the string “iP,” against the relative frequencies of the first letters of a word in the Spanish language
However, that distribution didn’t really fit either. While “t” was much better, I now had an under-abundance of words with an “e.” Although it should be noted that, unlike our English language relative frequencies, the data I was using for Spanish is for letters in the entire word, rather than letters that begin the word. That’s certainly going to introduce biases, perhaps fatal ones.
Not that I can really make the assumption that there is only one language present in the data, or even that one language predominates, unless that language is English.
At this stage it’s obvious that the data is, at least more or less, of the right order of magnitude. The data probably shows devices coming from a Western country. However, we’re a long way from the point where I’d come out and say something like ” … the device names were predominantly in English.” That’s not a conclusion I can make.
I’d be interested in tracking down the relative frequency of letters used in Arabic when the language is transcribed into the Roman alphabet. While I haven’t been able to find that data, I’m sure it exists somewhere. (Please drop a note in the comments if you have a lead.)
The next step for the analysis is to look at the names themselves. While I’m still in the process of mashing up something that will access U.S. census data and try and reverse geo-locate a name to a “most likely” geographical origin, such services do already exist. And I haven’t really pushed the boundaries here, or even started a serious statistical analysis of the subset of data released by Antisec.
This brings us to Pete Warden’s point that you can’t really anonymize your data. The anonymization process for large datasets such as this is simply an illusion. As Pete wrote:
Precisely because there are now so many different public datasets to cross-reference, any set of records with a non-trivial amount of information on someone’s actions has a good chance of matching identifiable public records.
While this release in itself is fairly harmless, a number of “harmless” releases taken together — or cleverly cross-referenced with other public sources such as Twitter, Google+, Facebook and other social media — might well be more damaging. And that’s ignoring the possibility that Antisec really might have names, addresses and telephone numbers to go side-by-side with these UDID records.
The question has to be asked then, where did this data originate? While 12 million records might seem a lot, compared to the number of devices sold it’s not actually that big a number. There are any number of iPhone applications with a 12-million-user installation base, and this sort of backend database could easily have been built up by an independent developer with a successful application who downloaded the device owner’s contact details before Apple started putting limitations on that.
Ignoring conspiracy theories, this dataset might be the result of a single developer. Although how it got into the FBI’s possession and the why of that, if it was ever there in the first place, is another matter entirely.
I’m going to go on hacking away at this data to see if there are any more interesting correlations, and I do wonder whether Antisec would consider a controlled release of the data to some trusted third party?
Much like the reaction to #locationgate, where some people were happy to volunteer their data, if enough users are willing to self-identify, then perhaps we can get to the bottom of where this data originated and why it was collected in the first place.
Thanks to Hilary Mason, Julie Steele, Irene Ros, Gemma Hobson and Marcos Villacampa for ideas, pointers to comparative data sources, and advice on visualisation of the data.
Update
9/6/12
In response to a post about this article on Google+, Josh Hendrix made the suggestion that I should look at word as well as letter frequency. It was a good idea, so I went ahead and wrote a quick script to do just that…
The top two words in the list are “iPad,” which occurs 445,111 times, and “iPhone,” which occurs 252,106 times. The next most frequent word is “iPod,” but that occurs only 36,367 times. This result backs up my earlier result looking at distribution by device type.
Then there are various misspellings and mis-capitalisations of “iPhone,” “iPad,” and “iPod.”
The first real word that isn’t an Apple trademark is “Administrator,” which occurs 10,910 times. Next are “David” (5,822), “John” (5,447), and “Michael” (5,034). This is followed by “Chris” (3,744), “Mike” (3,744), “Mark” (3,66) and “Paul” (3,096).
Looking down the list of real names, as opposed to partial strings and tokens, the first female name doesn’t occur until we’re 30 places down the list — it’s “Lisa” (1,732) with the next most popular female name being “Sarah” (1,499), in 38th place.
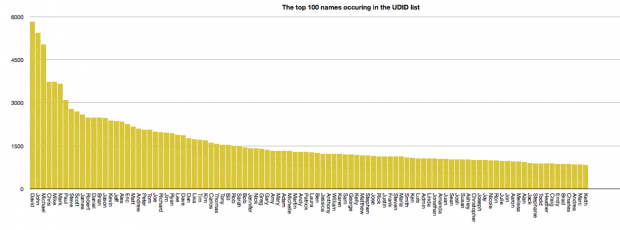
The top 100 names occurring in the UDID list.
The word “Dad” occurs 1,074 times, with “Daddy” occurring 383 times. For comparison the word “Mum” occurs just 58 times, and “Mummy” just 33. “Mom” came in with 150 occurrences, and “mommy” with 30. The number of occurrences for “mum,” “mummy,” “mom,” and “mommy” combined is 271, which is still very small compared to the combined total of 1,457 for “dad” and “daddy.”
[Updated: Greg Yardly wisely pointed out on Twitter that I was being a bit English-centric in only looking for the words “mum” and “mummy,” which is why I expanded the scope to include “mom” and “mommy.”]
There is a definite gender bias here, and I can think of at least a few explanations. The most likely is fairly simplistic: The application where the UDID numbers originated either appeals to, or is used more, by men.
Alternatively, women may be less likely to include their name in the name of their device, perhaps because amongst other things this name is used to advertise the device on wireless networks?
Either way I think this definitively pins it down as a list of devices originating in an Anglo-centric geographic region.
Sometimes the simplest things work better. Instead of being fancy perhaps I should have done this in the first place. However this, combined with my previous results, suggest that we’re looking at an English speaking, mostly male, demographic.
Correlating the top 20 or so names and with the list of most popular baby names (by year) all the way from the mid-’60s up until the mid-’90s (so looking at the most popular names for people between the ages of say 16 and 50) might give a further clue as to the exact demographic involved.
Both Gemma Hobson and Julie Steele directed me toward the U.S. Social Security Administration’s Popular Baby Names By Decade list. A quick and dirty analysis suggests that the UDID data is dominated by names that were most popular in the ’70s and ’80s. This maps well to my previous suggestion that the lack of iPod Touch usage might suggest that the demographic was older.
I’m going to do a year-by-year breakdown and some proper statistics later on, but we’re looking at an application that’s probably used by: English speaking males with an Anglo-American background in their 30s or 40s. It’s most used on the iPad, and although it also works on the iPhone, it’s used far less on that platform.
Thanks to Josh Hendrix, and again to Gemma Hobson and Julie Steele, for ideas and pointers to sources for this part of the analysis.
Update
9/11/12
A really nice analysis from David Schuetz uses the frequency of UDID duplicates and the names of those devices to track down the source of the leak. I really should have thought of that.
Interestingly, however, it does support my own analysis. Yesterday, a Florida publishing company named BlueToad said the UDID data was taken from their systems. BlueToad makes apps for magazine publishers, hence the predominance of of the iPad over the iPhone in my results, as those apps are more often used on the iPad.
Also they seem to mostly market into the U.S., which supports my ethnicity findings, and looking at the list of titles they curate, it does look like my demographics are more-or-less spot on as well. Those look like magazines marketed to men in their 30s and 40s to me.
I’d actually been really confused about what type of app could possibly have that narrow a demographic, and this sort of clears up my confusion. Nice!
Related: