
How Flash changes the design of database storage engines
High-performing memory throws many traditional decisions overboard

Over the past decade, SSD drives (popularly known as Flash) have radically changed computing at both the consumer level — where USB sticks have effectively replaced CDs for transporting files — and the server level, where it offers a price/performance ratio radically different from both RAM and disk drives. But databases have just started to catch up during the past few years. Most still depend on internal data structures and storage management fine-tuned for spinning disks.
Citing price and performance, one author advised a wide range of database vendors to move to Flash. Certainly, a database administrator can speed up old databases just by swapping out disk drives and inserting Flash, but doing so captures just a sliver of the potential performance improvement promised by Flash. For this article, I asked several database experts — including representatives of Aerospike, Cassandra, FoundationDB, RethinkDB, and Tokutek — how Flash changes the design of storage engines for databases. The various ways these companies have responded to its promise in their database designs are instructive to readers designing applications and looking for the best storage solutions.

Java 8 functional interfaces
Getting to know various out-of-the-box functions such as Consumer, Predicate, Supplier
In the first part of this series, we learned that lambdas are a type of functional interface – an interface with a single abstract method. The Java API has many one-method interfaces such as Runnable, Callable, Comparator, ActionListener and others. They can be implemented and instantiated using anonymous class syntax. For example, take the ITrade functional interface. It has only one abstract method that takes a Trade object and returns a boolean value – perhaps checking the status of the trade or validating the order or some other condition.
@FunctionalInterface
public interface ITrade {
public boolean check(Trade t);
}In order to satisfy our requirement of checking for new trades, we could create a lambda expression, using the above functional interface, as shown here:
ITrade newTradeChecker = (Trade t) -> t.getStatus().equals("NEW");
// Or we could omit the input type setting:
ITrade newTradeChecker = (t) -> t.getStatus().equals("NEW");
Why local state is a fundamental primitive in stream processing
What do you get if you cross a distributed database with a stream processing system?

One of the concepts that has proven the hardest to explain to people when I talk about Samza is the idea of fault-tolerant local state for stream processing. I think people are so used to the idea of keeping all their data in remote databases that any departure from that seems unusual.
So, I wanted to give a little bit more motivation as to why we think local state is a fundamental primitive in stream processing.
What is state and why do you need it?
An easy way to understand state in stream processing is to think about the kinds of operations you might do in SQL. Imagine running SQL queries against a real-time stream of data. If your SQL query contains only filtering and single-row transformations (a simple select and where clause, say), then it is stateless. That is, you can process a single row at a time without needing to remember anything in between rows. However, if your query involves aggregating many rows (a group by) or joining together data from multiple streams, then it must maintain some state in between rows. If you are grouping data by some field and counting, then the state you maintain would be the counts that have accumulated so far in the window you are processing. If you are joining two streams, the state would be the rows in each stream waiting to find a match in the other stream.

How to build and run your first deep learning network
Step-by-step instruction on training your own neural network.

When I first became interested in using deep learning for computer vision I found it hard to get started. There were only a couple of open source projects available, they had little documentation, were very experimental, and relied on a lot of tricky-to-install dependencies. A lot of new projects have appeared since, but they’re still aimed at vision researchers, so you’ll still hit a lot of the same obstacles if you’re approaching them from outside the field.
In this article — and the accompanying webcast — I’m going to show you how to run a pre-built network, and then take you through the steps of training your own. I’ve listed the steps I followed to set up everything toward the end of the article, but because the process is so involved, I recommend you download a Vagrant virtual machine that I’ve pre-loaded with everything you need. This VM lets us skip over all the installation headaches and focus on building and running the neural networks. Read more…
Questioning the Lambda Architecture
The Lambda Architecture has its merits, but alternatives are worth exploring.
Nathan Marz wrote a popular blog post describing an idea he called the Lambda Architecture (“How to beat the CAP theorem“). The Lambda Architecture is an approach to building stream processing applications on top of MapReduce and Storm or similar systems. This has proven to be a surprisingly popular idea, with a dedicated website and an upcoming book. Since I’ve been involved in building out the real-time data processing infrastructure at LinkedIn using Kafka and Samza, I often get asked about the Lambda Architecture. I thought I would describe my thoughts and experiences.
What is a Lambda Architecture and how do I become one?
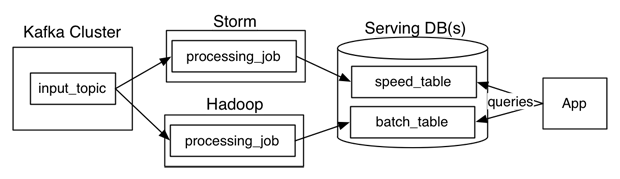
The Lambda Architecture looks something like this:

Simplifying Django
Lightweight Django by example
The following comes to you from Julia Elman and Mark Lavin. Julia is a a hybrid designer/developer who has been working her brand of web skills since 2002; and Mark is the Development Director at Caktus Consulting Group in Carrboro, NC where he builds scalable web applications with Django. Together, they are working on Lightweight Django, a book due out later this year that explores bringing Django into modern web practices.
Despite Django’s popularity and maturity, some developers believe that it is an outdated web framework made primarily for “content-heavy” applications. Since the majority of modern web applications and services tend not to be rich in their content, this reputation leaves Django seeming like a less than optimal choice as a web framework.
Let’s take a moment to look at Django from the ground up and get a better idea of where the framework stands in today’s web development practices.
Plain and Simple Django
A web framework’s primary purpose is to help to generate the core architecture for an application and reuse it on other projects. Django was built on this foundation to rapidly create web applications. At its core, Django is primarily a Web Server Gateway Interface (WSGI) application framework that provides HTTP request utilities for extracting and returning meaningful HTTP responses. It handles various services with these utilities by generating things like URL routing, cookie handling, parsing form data and file uploads.
Also, when it comes to building those responses Django provides a dynamic template engine. Right out of the box, you are provided with a long list of filters and tags to create dynamic and extensible templates for a rich web application building experience.
By only using these specific pieces, you easily see how you can build a plain and simple micro-framework application inside a Django project.
We do know that there are some readers who may enjoy creating or adding their own utilities and libraries. We are not trying to take away from this experience, but show that using something like Django allows for fewer distractions. For example, instead of having to decide between Jinja2, Mako, Genshi, Cheetah, etc, you can simply use the existing template language while you focus on building out other parts. Fewer decisions up front make for a more enjoyable application building process.