"bdas" entries

Seven reasons why I like Spark
Spark is becoming a key part of a big data toolkit.
A large portion of this week’s Amp Camp at UC Berkeley, is devoted to an introduction to Spark – an open source, in-memory, cluster computing framework. After playing with Spark over the last month, I’ve come to consider it a key part of my big data toolkit. Here’s why:
Hadoop integration: Spark can work with files stored in HDFS, an important feature given the amount of investment in the Hadoop Ecosystem. Getting Spark to work with MapR is straightforward.
The Spark interactive Shell: Spark is written in Scala, and has it’s own version of the Scala interpreter. I find this extremely convenient for testing short snippets of code.
The Spark Analytic Suite:
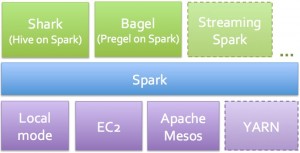
(Figure courtesy of Matei Zaharia)
Spark comes with tools for interactive query analysis (Shark), large-scale graph processing and analysis (Bagel), and real-time analysis (Spark Streaming). Rather than having to mix and match a set of tools (e.g., Hive, Hadoop, Mahout, S4/Storm), you only have to learn one programming paradigm. For SQL enthusiasts, the added bonus is that Shark tends to run faster than Hive. If you want to run Spark in the cloud, there are a set of EC2 scripts available.