"data platform" entries

Why local state is a fundamental primitive in stream processing
What do you get if you cross a distributed database with a stream processing system?

One of the concepts that has proven the hardest to explain to people when I talk about Samza is the idea of fault-tolerant local state for stream processing. I think people are so used to the idea of keeping all their data in remote databases that any departure from that seems unusual.
So, I wanted to give a little bit more motivation as to why we think local state is a fundamental primitive in stream processing.
What is state and why do you need it?
An easy way to understand state in stream processing is to think about the kinds of operations you might do in SQL. Imagine running SQL queries against a real-time stream of data. If your SQL query contains only filtering and single-row transformations (a simple select and where clause, say), then it is stateless. That is, you can process a single row at a time without needing to remember anything in between rows. However, if your query involves aggregating many rows (a group by) or joining together data from multiple streams, then it must maintain some state in between rows. If you are grouping data by some field and counting, then the state you maintain would be the counts that have accumulated so far in the window you are processing. If you are joining two streams, the state would be the rows in each stream waiting to find a match in the other stream.
Questioning the Lambda Architecture
The Lambda Architecture has its merits, but alternatives are worth exploring.
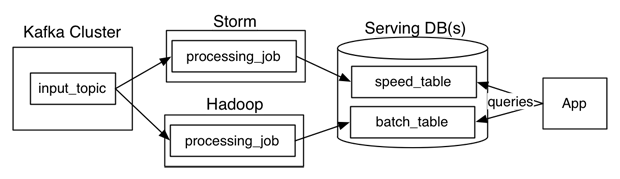
Nathan Marz wrote a popular blog post describing an idea he called the Lambda Architecture (“How to beat the CAP theorem“). The Lambda Architecture is an approach to building stream processing applications on top of MapReduce and Storm or similar systems. This has proven to be a surprisingly popular idea, with a dedicated website and an upcoming book. Since I’ve been involved in building out the real-time data processing infrastructure at LinkedIn using Kafka and Samza, I often get asked about the Lambda Architecture. I thought I would describe my thoughts and experiences.
What is a Lambda Architecture and how do I become one?
The Lambda Architecture looks something like this:

Strata Week: New life for an old census
The 1940 census makes its data debut, and the White House shows off its data initiative.
In this week's data news, the National Archives releases the data from the 1940 Census, the federal government outlines its big data plans, and an app uproar leads to good thinking on privacy and sharing.

Profile of the Data Journalist: The Homicide Watch
Chris Amico and Laura Norton Amico's project started as a spreadsheet. Now it's a community news platform.
To learn more about the people who are redefining the practice computer-assisted reporting, in some cases, building the newsroom stack for the 21st century, Radar conducted a series of email interviews with data journalists during the 2012 NICAR Conference. "It’s not just about the data, and it’s not just about the journalism, but it’s about meeting a community need in an innovative way," said Laura Norton Amico.

Data markets compared
A look at data market offerings from four providers.
Strata chair Edd Dumbill provides an overview of the most mature data markets (Infochimps, Factual, Windows Azure Data Marketplace, DataMarket), and contrasts their different approaches and facilities.

Top stories: February 20-24, 2012
Data for the public good, the coming health IT revolution, big data in the cloud.
This week on O'Reilly: Alex Howard examined data's civic role, Dr. Farzad Mostashari discussed health IT and patient empowerment, and Edd Dumbill surveyed big data cloud offerings.
The year in big data and data science
Hadoop, security and open data defined the data world in 2011.
From wide adoption of Hadoop to personal data empowerment, Radar data correspondent Audrey Watters looks back on the data trends that shaped 2011.

What is data science?
The future belongs to the companies and people that turn data into products.
This report takes a detailed look at the promise of data science and the technologies and unique skill sets at the heart of this growing discipline.