- Docker Secure Deployment Guidelines — deployment checklist for securely deploying Docker.
- The Devops Identity Crisis (Baron Schwartz) — I saw one framework-retailing bozo saying that devops was the art of ensuring there were no flaws in software. I didn’t know whether to cry or keep firing until the gun clicked.
- Apache Giraph — an iterative graph processing system built for high scalability. For example, it is currently used at Facebook to analyze the social graph formed by users and their connections.
- Apache Flink — a data processing system and an alternative to Hadoop’s MapReduce component. It comes with its own runtime, rather than building on top of MapReduce. As such, it can work completely independently of the Hadoop ecosystem. However, Flink can also access Hadoop’s distributed file system (HDFS) to read and write data, and Hadoop’s next-generation resource manager (YARN) to provision cluster resources. Since most Flink users are using Hadoop HDFS to store their data, we ship already the required libraries to access HDFS.
"Hadoop" entries

Four short links: 15 January 2015
Secure Docker Deployment, Devops Identity, Graph Processing, and Hadoop Alternative

The data lake model is a powerhouse for invention
In this O'Reilly Radar Podcast: Edd Dumbill on the data lake, and Rajiv Maheswaran on the science of moving dots.
In a recent blog post, Edd Dumbill, VP of strategy at Silicon Valley Data Science, wrote about the phrase “data lake.” Likening it to a dream, he described a data lake as “a place with data-centered architecture, where silos are minimized, and processing happens with little friction in a scalable, distributed environment…Data itself is no longer restrained by initial schema decisions, and can be exploited more freely by the enterprise.” He explained that he called it a “dream” because “we’ve a way to go to make the vision come true” — but noted he’s optimistic the dream can be realized.
Subscribe to the O’Reilly Radar Podcast
In this Radar Podcast epidsode, O’Reilly’s Mac Slocum sits down with Dumbill to talk about the data lake, the opportunities the model presents, and the driving forces behind the concept. Read more…

Signals from Strata + Hadoop World New York 2014
From unique data applications to factories of the future, here are key insights from Strata + Hadoop World New York 2014.
Experts from across the data world came together in New York City for Strata + Hadoop World New York 2014. Below we’ve assembled notable keynotes, interviews, and insights from the event.
Unusual data applications and the correct way to say “Hadoop”
Hadoop creator and Cloudera chief architect Doug Cutting discusses surprising data applications — from dating sites to premature babies — and he reveals the proper (but in no way required) pronunciation of “Hadoop.”
The human side of Hadoop
Doug Cutting on applications of Hadoop, where "Hadoop" comes from, and the new partnership between Cloudera and O'Reilly.
Roger Magoulas, director of market research at O’Reilly and Strata co-chair, recently sat down with Doug Cutting, chief architect at Cloudera, to talk about the new partnership between Cloudera and O’Reilly, and the state of the Hadoop landscape.
Cutting shares interesting applications of Hadoop, several of which had touching human elements. For instance, he tells a story about visiting Children’s Healthcare of Atlanta and discovering the staff using Hadoop to reduce stress in babies. Read more…
Four short links: 5 August 2014
Discussion Graph Tool, Superlinear Productivity, Go Concurrency, and R Map/Reduce Tools
- Discussion Graph Tool (Microsoft Research) — simplifies social media analysis by making it easy to extract high-level features and co-occurrence relationships from raw data.
- Superlinear Productivity in Collective Group Actions (PLoS ONE) — study of open source projects shows small groups exhibit non-linear productivity increases by size, which drop off at larger sizes. we document a size effect in the strength and variability of the superlinear effect, with smaller groups exhibiting widely distributed superlinear exponents, some of them characterizing highly productive teams. In contrast, large groups tend to have a smaller superlinearity and less variability.
- coop — cheat sheet of the most common concurrency program flows in Go.
- Tessera — set of open source tools around Hadoop, R, and visualization.
Four short links: 23 May 2014
Educate Users, Hardware by the Numbers, Humans Beating Computers, Hadoop's Uncomfortable Fit
- How to Educate Users (Luke Wroblewski) — help new users in your app, not in a video.
- Hardware By The Numbers (Renee DiResta) — slides from her keynote at the Solid conference. The mean success rate across all sectors is 19.8%. On average, only 10% of hardware startups raise a second round.
- Humans Beating Computers (Wired) — Newman assembled a small team that became known as the “Air Divers”–the people who would dive deep into the individual complaints and surface with answers. Each was given a couple hundred support tickets connected to a specific issue that the data had identified as a hot-button topic. They would go off and read through each one, then come back and propose a fix. And in the end, this is what turned the situation around. Sometimes it’s easier to put people on the job than try to code the data analysis.
- Hadoop’s Uncomfortable Fit in HPC — Hadoop is being taken seriously only at a subset of supercomputing facilities in the US, and at a finer granularity, only by a subset of professionals within the HPC community.

Big Data systems are making a difference in the fight against cancer
Open source, distributed computing tools speedup an important processing pipeline for genomics data
As open source, big data tools enter the early stages of maturation, data engineers and data scientists will have many opportunities to use them to “work on stuff that matters”. Along those lines, computational biology and medicine are areas where skilled data professionals are already beginning to make an impact. I recently came across a compelling open source project from UC Berkeley’s AMPLab: ADAM is a processing engine and set of formats for genomics data.
Second-generation sequencing machines produce more detailed and thus much larger files for analysis (250+ GB file for each person). Existing data formats and tools are optimized for single-server processing and do not easily scale out. ADAM uses distributed computing tools and techniques to speedup key stages of the variant processing pipeline (including sorting and deduping):
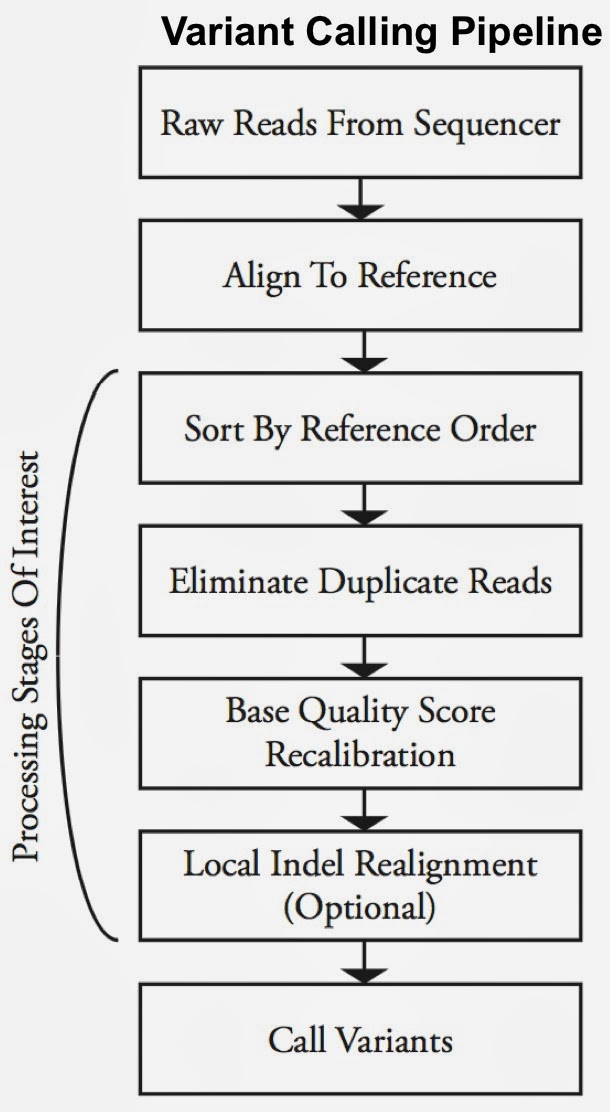
Very early on the designers of ADAM realized that a well-designed data schema (that specifies the representation of data when it is accessed) was key to having a system that could leverage existing big data tools. The ADAM format uses the Apache Avro data serialization system and comes with a human-readable schema that can be accessed using many programming languages (including C/C++/C#, Java/Scala, php, Python, Ruby). ADAM also includes a data format/access API implemented on top of Apache Avro and Parquet, and a data transformation API implemented on top of Apache Spark. Because it’s built with widely adopted tools, ADAM users can leverage components of the Hadoop (Impala, Hive, MapReduce) and BDAS (Shark, Spark, GraphX, MLbase) stacks for interactive and advanced analytics.

An Introduction to Hadoop 2.0: Understanding the New Data Operating System
Sneak peek at an upcoming tutorial at Strata Santa Clara 2014
Apache Hadoop 2.0 represents a generational shift in the architecture of Apache Hadoop. With YARN, Apache Hadoop is recast as a significantly more powerful platform – one that takes Hadoop beyond merely batch applications to taking its position as a ‘data operating system’ where HDFS is the file system and YARN is the operating system.
YARN is a re-architecture of Hadoop that allows multiple applications to run on the same platform. With YARN, applications run “in” Hadoop, instead of “on” Hadoop:


How to analyze 100 million images for $624
There's a lot of new ground to be explored in large-scale image processing.
Jetpac is building a modern version of Yelp, using big data rather than user reviews. People are taking more than a billion photos every single day, and many of these are shared publicly on social networks. We analyze these pictures to discover what they can tell us about bars, restaurants, hotels, and other venues around the world — spotting hipster favorites by the number of mustaches, for example.

Treating large numbers of photos as data, rather than just content to display to the user, is a pretty new idea. Traditionally it’s been prohibitively expensive to store and process image data, and not many developers are familiar with both modern big data techniques and computer vision. That meant we had to cut a path through some thick underbrush to get a system working, but the good news is that the free-falling price of commodity servers makes running it incredibly cheap. Read more…

Dealing with Data in the Hadoop Ecosystem
Hadoop, Sqoop, and ZooKeeper
Kathleen Ting (@kate_ting), Technical Account Manager at Cloudera, and our own Andy Oram (@praxagora) sat down to discuss how to work with structured and unstructured data as well as how to keep a system up and running that is crunching that data.
Key highlights include:
- Misconfigurations consist of almost half of the support issues that the team at Cloudera is seeing [Discussed at 0:22]
- ZooKeeper, the canary in the Hadoop coal mine [Discussed at 1:10]
- Leaky clients are often a problem ZooKeeper detects [Discussed at 2:10]
- Sqoop is a bulk data transfer tool [Discussed at 2:47]
- Sqoop helps to bring together structured and unstructured data [Discussed at 3:50]
- ZooKeep is not for storage, but coordination, reliability, availability [Discussed at 4:44]
You can view the full interview here: