- CS 61AS — Berkeley self-directed Structure and Interpretation of Computer Programs course.
- Harbingers of Failure (PDF) — We show that some customers, whom we call ‘Harbingers’ of failure, systematically purchase new products that flop. Their early adoption of a new product is a strong signal that a product will fail – the more they buy, the less likely the product will succeed. Firms can identify these customers either through past purchases of new products that failed, or through past purchases of existing products that few other customers purchase.
- Google Material Design Lite — A library of Material Design components in CSS, JS, and HTML.
- Breakouts — various implementations of the classic game Breakout in numerous different [Javascript] engines.
"javascript" entries

Learning programming at scale
Bringing some of the benefits of face-to-face learning to millions of people without access to an in-person tutor.
Millions of people around the world — from aspiring software engineers to data scientists — now want to learn programming. One of the best ways to learn is by working side-by-side with a personal tutor. A good tutor can watch you as you code, help you debug, explain tricky concepts on demand, and provide encouragement to keep you motivated. However, very few of us are lucky enough to have a tutor by our side. If we take a class, there might be 25 to 50 students for every teacher. If we take a MOOC (Massive Open Online Course), there might be 1,000 to 10,000 students for every professor or TA. And if we’re learning on our own from books or online tutorials, there’s no tutor or even fellow learners in sight. Given this reality, how can computer-based tools potentially bring some of the benefits of face-to-face learning to millions of people around the world who do not have access to an in-person tutor?
I’ve begun to address this question by building open-source tools to help people overcome a fundamental barrier to learning programming: understanding what happens as the computer runs each line of a program’s source code. Without this basic skill, it is impossible to start becoming fluent in any programming language. For example, if you’re learning Python, it might be hard to understand why running the code below produces the following three lines of output:
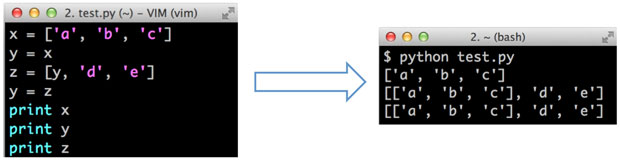
A tutor can explain why this code prints what it does by drawing the variables, data structures, and pointers at each execution step. However, what if you don’t have a personal tutor?

4 things to make your Java 8 code more dynamic
Anytime is a good time to refactor your code.

Java 8 has a few new features which should help you write more dynamic code. Of course one of the big features was the addition of a lambda syntax. But what about some of the other features that were added? Here are a couple of things that I tell people to do in order to make their code more dynamic and more functional.

Four short links: 7 July 2015
SCIP Berkeley Style, Regular Failures, Web Material Design, and Javascript Breakouts
Four short links: 2 July 2015
Mathematical Thinking, Turing on Imitation Game, Retro Gaming in Javascript, and Effective Retros
- How Not to be Wrong: The Power of Mathematical Thinking (Amazon) — Ellenberg chases mathematical threads through a vast range of time and space, from the everyday to the cosmic, encountering, among other things, baseball, Reaganomics, daring lottery schemes, Voltaire, the replicability crisis in psychology, Italian Renaissance painting, artificial languages, the development of non-Euclidean geometry, the coming obesity apocalypse, Antonin Scalia’s views on crime and punishment, the psychology of slime molds, what Facebook can and can’t figure out about you, and the existence of God. (via Pam Fox)
- What Turing Himself Said About the Imitation Game (IEEE) — fascinating history. The second myth is that Turing predicted a machine would pass his test around the beginning of this century. What he actually said on the radio in 1952 was that it would be “at least 100 years” before a machine would stand any chance with (as Newman put it) “no questions barred.”
- Impossible Mission in Javascript — an homage to the original, and beautiful to see. I appear to have lost all my skills in playing it in the intervening 32 years.
- Running Effective Retrospectives — Each change to the team’s workflow is treated as a scientific experiment, whereby a hypothesis is formed, data collected, and expectations compared with actual results.

JavaScript shares its ubiquity
WebAssembly changes the rules of the JavaScript game.

I’ve never seen a technology lay down its primary advantage and prepare to hand over its ubiquity. I’m proud of JavaScript for doing this, and I’m sure that in the long run this will be good for the Web, but in the meantime I’m wondering where WebAssembly will take us.
Brendan Eich’s announcement of the effort makes clear that this builds on the earlier asm.js (and Google’s similar PNaCl), a highly efficient JavaScript subset that compilers of other languages could target. Eich enjoyed using Unreal Engine for demos of the speed asm.js could provide, but compiling to JavaScript, even weird JavaScript, still needed to go through a JavaScript parser. (Other approaches compiled to more comprehensible but less optimized JavaScript.)
WebAssembly – wasm – skips that final step, producing a binary format, technically a compressed AST encoding. Unless you’re going to be building compilers, you can compare wasm to a bytecode system. There is a text format for debugging, but the binary emphasis yields substantial extra speed as it skips parsing and minimizes decompression.
Read more…
Four short links: 29 May 2015
Data Integration, Carousel, Distributed Project Management, and Costs of Premature Build
- Using Logs to Build Solid Data Infrastructure — (Martin Kleppmann) — For lack of a better term, I’m going to call this the problem of ‘data integration.’ With that, I really just mean ‘making sure that the data ends up in all the right places.’ Whenever a piece of data changes in one place, it needs to change correspondingly in all the other places where there is a copy or derivative of that data.
- TremulaJS — sweet carousel, with PHYSICS.
- Project Advice (Daniel Bachhuber) — for leaders of distributed teams. Focus on clearing blockers above all else. Because you’re working on an open source project with contributors across many timezones, average time to feedback will optimistically be six hours. More likely, it will be 24-48 hours. This slow feedback cycle can kill progress on pull requests. As a project maintainer, prioritize giving feedback, clearing blockers, and making decisions.
- YAGNI (Martin Fowler) — cost of build, cost of delay, cost of carry, cost of repair. Every product manager has felt these costs.
Four short links: 25 May 2015
8 (Bits) Is Enough, Second Machine Age, LLVM OpenMP, and Javascript Graphs
- Why Are Eight Bits Enough for Deep Neural Networks? (Pete Warden) — It turns out that neural networks are different. You can run them with eight-bit parameters and intermediate buffers, and suffer no noticeable loss in the final results. This was astonishing to me, but it’s something that’s been re-discovered over and over again.
- The Great Decoupling (HBR) — The Second Machine Age is playing out differently than the First Machine Age, continuing the long-term trend of material abundance but not of ever-greater labor demand.
- OpenMP Support in LLVM — OpenMP enables Clang users to harness full power of modern multi-core processors with vector units. Pragmas from OpenMP 3.1 provide an industry standard way to employ task parallelism, while ‘#pragma omp simd’ is a simple yet flexible way to enable data parallelism (aka vectorization).
- JS Graphs — a visual catalogue (with search) of Javascript graphing libraries.
Four short links: 18 May 2015
Javascript Tools, Elements of Scale, 2FA Adoption, and Empathy
- Tools are the Problem — Tools don’t solve problems any more; they have become the problem. There’s just too many of them, and they all include an incredible number of features that you don’t use on your site –but that users are still required to download and execute.
- Elements of Scale: Composing and Scaling Data Platforms (Ben Stopford) — today’s data platforms range greatly in complexity, from simple caching layers or polyglotic persistence right through to wholly integrated data pipelines. There are many paths. They go to many different places. In some of these places at least, nice things are found. So, the aim for this talk is to explain how and why some of these popular approaches work. We’ll do this by first considering the building blocks from which they are composed. These are the intuitions we’ll need to pull together the bigger stuff later on.
- Estimating Google’s 2FA Adoption — If we project out to the current day (965 days later), that’s a growth of ~25M users (25,586,975). Add that to the ~14M base number of users (13,886,058) exiting the graph and we end up at a grand total of…nearly 40 million users (39,473,033) enrolled in Google’s 2SV. NB there’s a lot on the back of this envelope.
- Empathy and Product Development — None of this means that you shouldn’t A/B test or have other quantitative measure. But all of those will mean very little if you don’t have the qualitative context that only observation and usage can provide. Empathy is central to product development.
Finding new in the Web
Learning from the Fluent Conference.
At Fluent 2015, we brought together a variety of stories about front-end engineering – some technical, some social, some more intricately intertwined.
From the very first day, it was clear that React was the big technical story of the conference, taking the place that Angular (which is still clearly important!) had had the previous year. Tutorials and sessions were busy, and I kept hearing conversation about React. Sometimes it was “what is React supposed to do?” but other times people were talking about exciting corners of React Native or techniques for integrating React with a variety of frameworks.
React makes me happy because it solves the problem a lot of people didn’t quite realize they had. Suddenly they are very enthusiastic about stuff that used to be really annoying. The Document Object Model (DOM) has been the foundation of most of the interactive work on the web since 1998, but it wasn’t very much fun then. As developers really get deeper into these things, the DOM has not exactly been a crowd-pleaser. In some ways React is a wrapper for the DOM, and in many ways it’s a just a better way to interact with the document tree.
The other technical key this year was JavaScript, often specifically ECMAScript 6 (ES6), the latest release. Brendan Eich talked about a world in which compiling to JavaScript has become normal, and how that frees much of the future development of JavaScript and the Web. Even Dart, which many of us saw as an attempt to replace JavaScript, has a home in this world.
Read more…
Four short links: 7 April 2015
JavaScript Numeric Methods, Misunderstood Statistics, Web Speed, and Sentiment Analysis
- NumericJS — numerical methods in JavaScript.
- P Values are not Error Probabilities (PDF) — In particular, we illustrate how this mixing of statistical testing methodologies has resulted in widespread confusion over the interpretation of p values (evidential measures) and α levels (measures of error). We demonstrate that this confusion was a problem between the Fisherian and Neyman–Pearson camps, is not uncommon among statisticians, is prevalent in statistics textbooks, and is well nigh universal in the pages of leading (marketing) journals. This mass confusion, in turn, has rendered applications of classical statistical testing all but meaningless among applied researchers.
-
Breaking the 1000ms Time to Glass Mobile Barrier (YouTube) —
See also slides. Stay under 250 ms to feel “fast.” Stay under 1000 ms to keep users’ attention. - Modern Methods for Sentiment Analysis — Recently, Google developed a method called Word2Vec that captures the context of words, while at the same time reducing the size of the data. Gentle introduction, with code.