- Privacy-Preserving Inference of Social Relationships from Location Data (PDF) — utilizes an untrusted server and computes the building blocks to support various social relationship studies, without disclosing location information to the server and other untrusted parties. (via CCC Blog)
- Jepson takes on Rethink — the glowingest review I’ve seen from Aphyr. As far as I can ascertain, RethinkDB’s safety claims are accurate.
- T-Mobile’s BingeOn `Optimization’ Is Just Throttling (EFF) — T-Mobile has claimed that this practice isn’t really “throttling,” but we disagree. It’s clearly not “optimization,” since T-Mobile doesn’t alter the actual content of the video streams in any way.
- qminer — BSD-licensed data analytics platform for processing large-scale, real-time streams containing structured and unstructured data.
"real time" entries

Four short links: 5 January 2016
Inference with Privacy, RethinkDB Reliability, T-Mobile Choking Video, and Real-Time Streams
Four short links: 6 October 2015
System Intuition, Magic is Power, Predicting Behaviour, Payment Required
- Flux: New Approach to System Intuition (LinkedIn) — In general, we assume that if anything is best represented numerically, then we don’t need to visualize it. If the best representation is a numerical one, then a visualization could only obscure a quantifiable piece of information that can be measured, compared, and acted upon. Anything that we can wrap in alerts or some threshold boundary should kick off some automated process. No point in ruining a perfectly good system by introducing a human into the mix. Instead of numerical information, we want a tool that surfaces relevant information to a human, for situations that would be too onerous to create a heuristic. These situations require an intuition that we can’t codify.
- Jumping to the End: Practical Design Fiction (Vimeo) — “Magic is a power relationship” — Matt Jones on the flipside of hiding complex behaviours from users and making stuff “work like magic.” (via Richard Pope)
- Predicting Daily Activities from Egocentric Images Using Deep Learning — aka “people wear cameras and we can figure out what they’re going to do next.”
- 402: Payment Required (David Humphrey) — The ad blocking discussion highlights our total lack of imagination, where a browser’s role is reduced to “render” or “don’t render.” There are a whole world of options in between that we should be exploring.
Four short links: 3 June 2015
Filter Design, Real-Time Analytics, Neural Turing Machines, and Evaluating Subjective Opinions
- How to Design Applied Filters — The most frequently observed issue during usability testing were filtering values changing placement when the user applied them – either to another position in the list of filtering values (typically the top) or to an “Applied filters” summary overview. During testing, the subjects were often confounded as they noticed that the filtering value they just clicked was suddenly “no longer there.”
- Twitter Heron — a real-time analytics platform that is fully API-compatible with Storm […] At Twitter, Heron is used as our primary streaming system, running hundreds of development and production topologies. Since Heron is efficient in terms of resource usage, after migrating all Twitter’s topologies to it we’ve seen an overall 3x reduction in hardware, causing a significant improvement in our infrastructure efficiency.
- ntm — an implementation of neural Turing machines. (via @fastml_extra)
- Bayesian Truth Serum — a scoring system for eliciting and evaluating subjective opinions from a group of respondents, in situations where the user of the method has no independent means of evaluating respondents’ honesty or their ability. It leverages respondents’ predictions about how other respondents will answer the same questions. Through these predictions, respondents reveal their meta-knowledge, which is knowledge of what other people know.

21st century communication with WebRTC
Engaging in-depth on the web with peer-to-peer connections.
As the web platform continues to evolve, tools have emerged for connecting people and computers in new and interesting ways. Web Real-Time Communication (WebRTC) stands out as one of the most significant and disruptive of these emerging technologies, allowing developers to embed peer-to-peer real-time communication in the browser without proprietary plugins, while breaking away from the traditional client-server paradigm.
Since Google released and open-sourced the WebRTC project in early 2011, the Internet Engineering Task Force (IETF) and the World Wide Web Consortium (W3C) have been working together to formalize the WebRTC standard and 1.0 stable release. Companies like Twilio and Vidyo have adopted WebRTC as a protocol for video chat in the browser, and established telco and VoIP players such as Cisco, Ericsson, and Telefónica have also lent support to the project.
At the most recent meeting of the IETF, Simon Pietro Romano, author of Real-Time Communication with WebRTC, hosted a panel to discuss developments in the WebRTC community and the road ahead. The panel, who are driving forces behind ongoing standardization and implementation, included:
- Justin Uberti, tech lead for the WebRTC team at Google
- Eric Rescorla of Mozilla
- Dan Burnett, editor of the PeerConnection and getUserMedia W3C WEBRTC specification
- Cullen Jennings, Cisco Fellow and Co-Chair of the IETF RTCWeb
I’d encourage you to listen to the whole conversation, but to get started, you might explore these highlights.
Four short links: 27 June 2014
Google MillWheel, 20yo Bug, Fast Real-Time Visualizations, and Google's Speed King
- MillWheel: Fault-Tolerant Stream Processing at Internet Scale — Google Research paper on the tech underlying the new cloud DataFlow tool. Watch the video. Yow.
- The Integer Overflow Bug That Went to Mars — long-standing (20 year old!) bug in a compression library prompts a wave of new releases. No word yet on whether NASA will upgrade the rover to avoid being pwned by Martian script kiddies. (update: I fell for a self-promoter. The Martians will need to find another attack vector. Huzzah!)
- epoch (github) — Fastly-produced open source general purpose real-time charting library for building beautiful, smooth, and high performance visualizations.
- Achieving Rapid Response Times in Large Online Services (YouTube) — Jeff Dean‘s keynote at Velocity. He wrote … a lot of things for this. And now he’s into deep learning ….

Stream Processing and Mining just got more interesting
A general purpose stream processing framework from the team behind Kafka and new techniques for computing approximate quantiles
Largely unknown outside data engineering circles, Apache Kafka is one of the more popular open source, distributed computing projects. Many data engineers I speak with either already use it or are planning to do so. It is a distributed message broker used to store1 and send data streams. Kafka was developed by Linkedin were it remains a vital component of their Big Data ecosystem: many critical online and offline data flows rely on feeds supplied by Kafka servers.
Apache Samza: a distributed stream processing framework
Behind Kafka’s success as an open source project is a team of savvy engineers who have spent2 the last three years making it a rock solid system. The developers behind Kafka realized early on that it was best to place the bulk of data processing (i.e., stream processing) in another system. Armed with specific use cases, work on Samza proceeded in earnest about a year ago. So while they examined existing streaming frameworks (such as Storm, S4, Spark Streaming), Linkedin engineers wanted a system that better fit their needs3 and requirements:
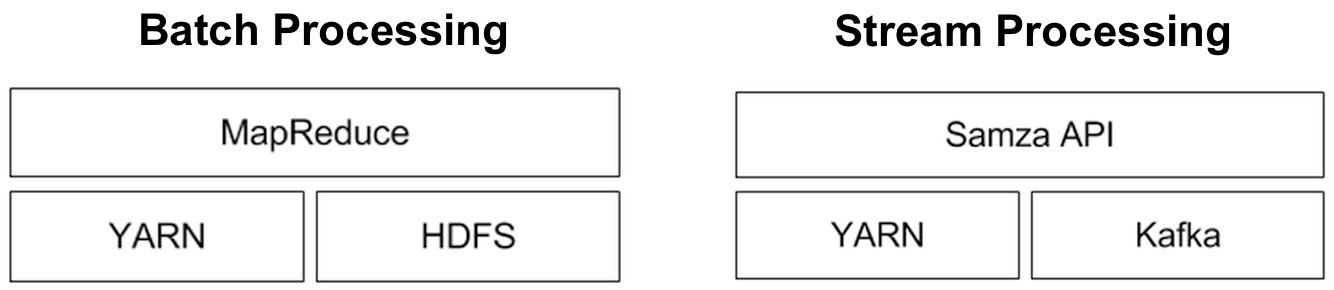
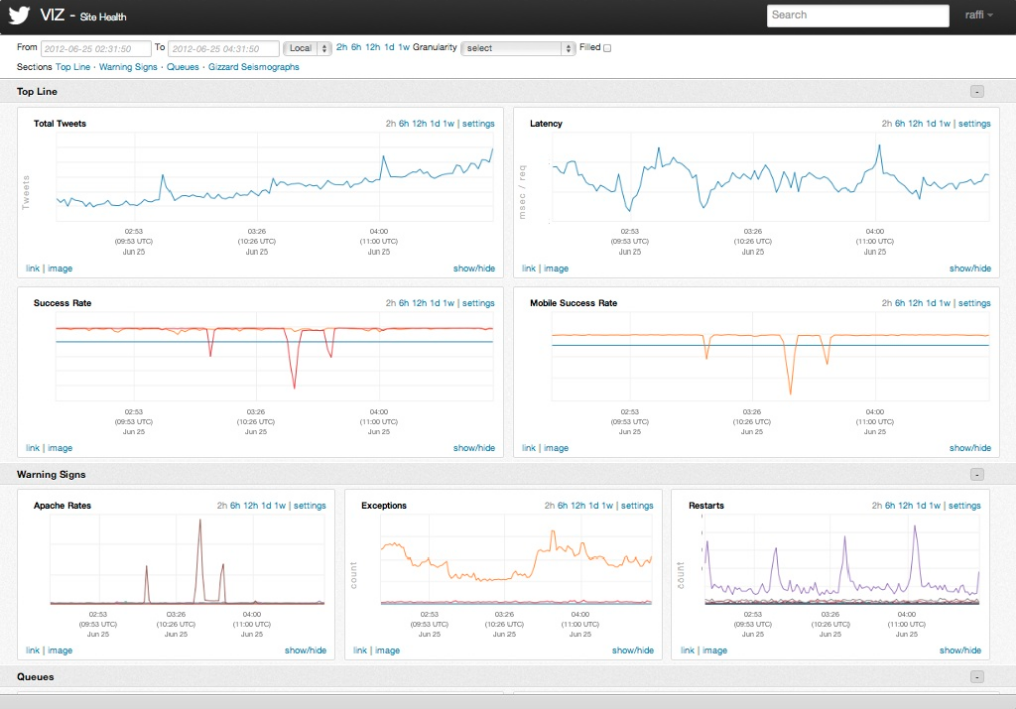
How Twitter monitors millions of time-series
A distributed, near real-time system simplifies the collection, storage, and mining of massive amounts of event data
One of the keys to Twitter’s ability to process 500 millions tweets daily is a software development process that values monitoring and measurement. A recent post from the company’s Observability team detailed the software stack for monitoring the performance characteristics of software services, and alert teams when problems occur. The Observability stack collects 170 million individual metrics (time-series) every minute and serves up 200 million queries per day. Simple query tools are used to populate charts and dashboards (a typical user monitors about 47 charts).
The stack is about three years old1 and consists of instrumentation2 (data collection primarily via Finagle), storage (Apache Cassandra), a query language and execution engine3, visualization4, and basic analytics. Four distinct Cassandra clusters are used to serve different requirements (real-time, historical, aggregate, index). A lot of engineering work went into making these tools as simple to use as possible. The end result is that these different pieces provide a flexible and interactive framework for developers: insert a few lines of (instrumentation) code and start viewing charts within minutes5.
Running batch and long-running, highly available service jobs on the same cluster
Moving different workloads and frameworks onto the same collection of machines increases efficiency and ROI
As organizations increasingly rely on large computing clusters, tools for leveraging and efficiently managing compute resources become critical. Specifically, tools that allow multiple services and frameworks run on the same cluster can significantly increase utilization and efficiency. Schedulers1 take into account policies and workloads to match jobs with appropriate resources (e.g., memory, storage, processing power) in a large compute cluster. With the help of schedulers, end users begin thinking of a large cluster as a single resource (like “a laptop”) that can be used to run different frameworks (e.g., Spark, Storm, Ruby on Rails, etc.).
Multi-tenancy and efficient utilization translates into improved ROI. Google’s scheduler, Borg, has been in production for many years and has led to substantial savings2. The company’s clusters handle a variety of workloads that can be roughly grouped into batch (compute something, then finish) and services (web or infrastructure services like BigTable). Researchers recently examined traces from several Google clusters and observed that while “batch jobs” accounted for 80% of all jobs, “long service jobs” utilize 55-60% of resources.
There are other benefits of multi-tenancy. Being able to run analytics (batch, streaming) and long running services (e.g., web applications) on the same cluster significantly lowers latency3, opening up the possibility for real-time, analytic applications. Bake-offs can be done more effectively as competing tools, versions, and frameworks can be deployed on the same cluster. Data scientists and production engineers leverage the same compute resources, making it easier for teams to work together across the analytic lifecycle. An additional benefit is that data science teams learn to build products and services that factor in efficient utilization and availability.
Mesos, Chronos, and Marathon
Apache Mesos is a popular open source scheduler that originated from UC Berkeley’s AMPlab. Mesos is based on features in modern kernels for resource isolation (cgroups in Linux). It has been in production for a few years at Twitter4, airbnb5, and many other companies – AMPlab simulations showed Mesos comfortably handling clusters with 30K servers.
Near realtime, streaming, and perpetual analytics
Hadoop moves from batch to near realtime: next up, placing streaming data in context
Simple example of a near realtime app built with Hadoop and HBase
Over the past year Hadoop emerged from its batch processing roots and began to take on interactive and near realtime applications. There are numerous examples that fall under these categories, but one that caught my eye recently is a system jointly developed by China Mobile Guangdong (CMG) and Intel1. It’s an online system that lets CMG’s over 100 million subscribers2 access and pay their bills, and examine their CDR’s (call detail records) in near realtime.
A service for providing detailed billing information is an important customer touch point. Repeated/extended downtimes and data errors could seriously tarnish CMG’s image. CMG needed a system that could scale to their current (and future) data volumes, while providing the low-latency responses consumers have come to expect from online services. Scalability, price and open source3 were important criteria in persuading the company to choose a Hadoop-based solution over4 MPP data warehouses.
In the system it co-developed with Intel, CMG stores detailed subscriber billing records in HBase. This amounts to roughly 30 TB/month, but since the service lets users browse up to six months of billing data it provides near realtime query results on much larger amounts of data. There are other near realtime applications built from Hadoop components (notably the continuous compute system at Yahoo!), that handle much larger data sets. But what I like about the CMG example is that it’s an application that most people understand right away (a detailed billing lookup system), and it illustrates that the Hadoop ecosystem has grown beyond batch processing.
Besides powering their online billing lookup service, CMG uses its Hadoop platform for analytics. Data from multiple sources (including phone device preferences, usage patterns, and cell tower performance) are used to compute customer segments and targeted promotions. Over time, Hadoop’s ability to handle large amounts of unstructured data opens up other data sources that can potentially improve CMG’s current analytic models.
Contextualize: Streaming and Perpetual Analytics
This leads me to something “realtime” systems are beginning to do: placing streaming data in context. Streaming analytics operates over fixed time windows and is used to identify “top k” trending items, heavy-hitters, and distinct items. Perpetual analytics takes what you’re observing now and places it in the context of what you already know. As much as companies appreciate metrics produced by streaming engines, they also want to understand how “realtime observations” affect their existing knowledge base.
Moving from Batch to Continuous Computing at Yahoo!
Spark, Storm, HBase, and YARN power large-scale, real-time models.
My favorite session at the recent Hadoop Summit was a keynote by Bruno Fernandez-Ruiz, Senior Fellow & VP Platforms at Yahoo! He gave a nice overview of their analytic and data processing stack, and shared some interesting factoids about the scale of their big data systems. Notably many of their production systems now run on MapReduce 2.0 (MRv2) or YARN – a resource manager that lets multiple frameworks share the same cluster.
Yahoo! was the first company to embrace Hadoop in a big way, and it remains a trendsetter within the Hadoop ecosystem. In the early days the company used Hadoop for large-scale batch processing (the key example being, computing their web index for search). More recently, many of its big data models require low latency alternatives to Hadoop MapReduce. In particular, Yahoo! leverages user and event data to power its targeting, personalization, and other “real-time” analytic systems. Continuous Computing is a term Yahoo! uses to refer to systems that perform computations over small batches of data (over short time windows), in between traditional batch computations that still use Hadoop MapReduce. The goal is to be able to quickly move from raw data, to information, to knowledge:

On a side note: many organizations are beginning to use cluster managers that let multiple frameworks share the same cluster. In particular I’m seeing many companies – notably Twitter – use Mesos1 (instead of YARN) to run similar services (Storm, Spark, Hadoop MapReduce, HBase) on the same cluster.
Going back to Bruno’s presentation, here are some interesting bits – current big data systems at Yahoo! by the numbers: