"strata santa clara 2014" entries

How might we …
Human-centered design techniques from an ideation workshop.
By Bo Peng and Aaron Wolf of Datascope Analytics

Bo Peng at a Datascope Analytics Ideation Workshop in Chicago
At Datascope Analytics, our ideation workshop combines elements from human-centered design principles to develop innovative and valuable ideas/solutions/strategies for our clients. From our workshop experience, we’ve developed a few key techniques that have enabled successful communication and collaboration. We complete certain milestones during the workshop: the departure point, the dream view, and curation with gold star voting, among others. These are just a few of the accomplishments that are achieved at various points during the workshop. In addition, we strive to support cultural goals throughout the workshop’s duration: creating an environment that spurs creativity and encourages wild ideas, and maintaining a mediator role. These techniques have thus far proven successful in providing innovative and actionable solutions for our clients.

IPython: A unified environment for interactive data analysis
It has roots in academic scientific computing, but has features that appeal to many data scientists
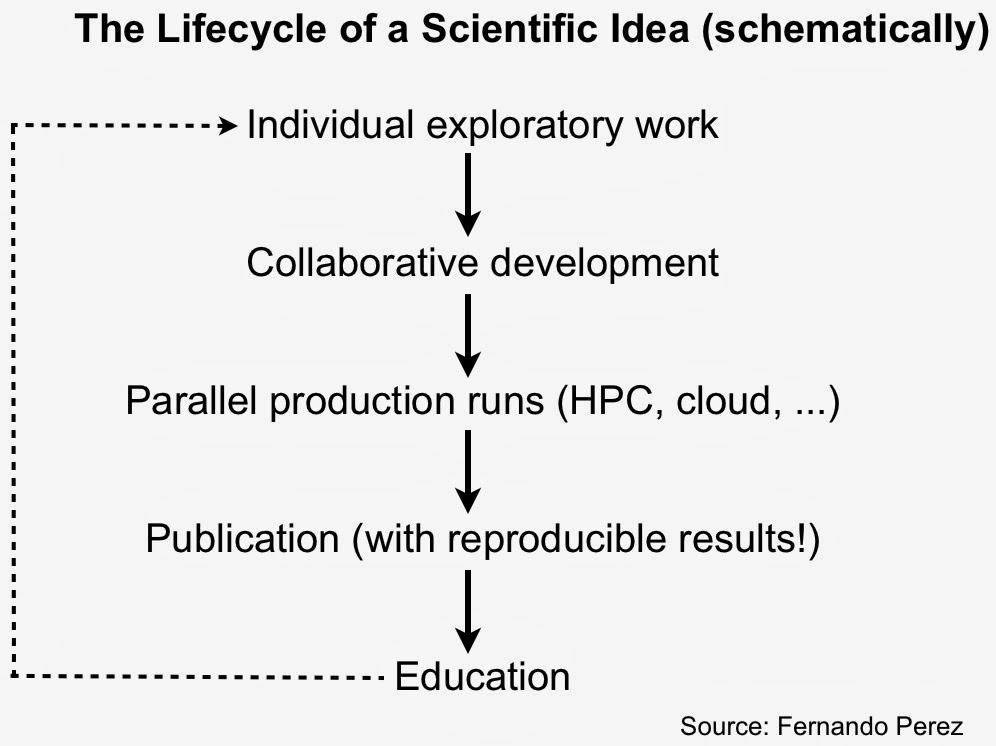
As I noted in a recent post on reproducing data projects, notebooks have become popular tools for maintaining, sharing, and replicating long data science workflows. Much of that is due to the popularity of IPython1. In development since 2001, IPython grew out of the scientific computing community and has slowly added features that appeal to data scientists.
Roots in academic scientific computing
As IPython creator Fernando Perez noted in his “historical retrospective”, exploratory analysis in a scientific setting requires a solid interactive environment. After years of development IPython has become a great tool for interacting with data. IPython also addresses other important pain points for scientists – reproducibility and collaboration – issues that are equally important to data scientists working in industry.
IPython is more than just Python
With an interactive widget architecture that’s 100% language-agnostic, these days IPython is used by many other programming language communities2, including Julia, Haskell, F#, Ruby, Go, and Scala. If you’re a data scientist who likes to mix-and-match languages, you can create, maintain, and share multi-language data projects in IPython:
Why is building custom recommender systems hard? Does it have to be?

Photo Courtesy of Carlos Guestrin
Today, it’s shocking (and honestly exciting) how much of my daily experience is determined by a recommender system. These systems drive amazing experiences everywhere, telling me where to eat, what to listen to, what to watch, what to read, and even who I should be friends with. Furthermore, information overload is making recommender systems indispensable, since I can’t find what I want on the web simply using keyword search tools. Recommenders are behind the success of industry leaders like Netflix, Google, Pandora, eHarmony, Facebook, and Amazon. It’s no surprise companies want to integrate recommender systems with their own online experiences. However, as I talk to team after team of smart industry engineers, it has become clear that building and managing these systems is usually a bit out of reach, especially given all the other demands on the team’s time.

Learning Apache Mesos
In the summer of 2012, Accel Partners hosted an invitation-only Big Data conference at Stanford. Ping Li stood near the exit with a checkbook, ready to invest $1MM in pitches for real-time analytics on clusters. However, real-time means many different things. For MetaScale working on the Sears turnaround, real-time means shrinking a 6 hour window on a mainframe to 6 minutes on Hadoop. For a hedge fund, real-time means compiling Python to run on GPUs where milliseconds matter, or running on FPGA hardware for microsecond response.
With much emphasis on Hadoop circa 2012, one might think that no other clusters existed. Nothing could be further from the truth: Memcached, Ruby on Rails, Cassandra, Anaconda, Redis, Node.js, etc. – all in large-scale production use for mission critical apps, much closer to revenue than the batch jobs. Google emphasizes a related point in their Omega paper: scheduling batch jobs is not difficult, while scheduling services on a cluster is a hard problem, and that translates to lots of money.
Apache Mesos: Open Source Datacenter Computing
Mesos offers reliability, efficiency and faster developer productivity.
Virtual machines (VMs) have enjoyed a long history, from IBM’s CP–40 in the late 1960s on through the rise of VMware in the late 1990s. Widespread VM use nearly became synonymous with “cloud computing” by the late 2000s: public clouds, private clouds, hybrid clouds, etc. One firm, however, bucked the trend: Google.
Google’s datacenter computing leverages isolation in lieu of VMs. Public disclosure is limited, but the Omega paper from EuroSys 2013 provides a good overview. See also two YouTube videos: John Wilkes in 2011 GAFS Omega and Jeff Dean in Taming Latency Variability… For the business case, see an earlier Data blog post, that discusses how multi-tenancy and efficient utilization translates into improved ROI.
One takeaway is Google’s analysis of cluster traces from large Internet firms: while ~80% of the jobs are batch, ~80% of the resources get used for services. Another takeaway is Google’s categorization of cluster scheduling technology: monolithic versus two-level versus shared state. The first category characterizes Borg, which Google has used for several years. The third characterizes their R&D goals, a newer system called Omega.
An Introduction to Hadoop 2.0: Understanding the New Data Operating System
Sneak peek at an upcoming tutorial at Strata Santa Clara 2014
Apache Hadoop 2.0 represents a generational shift in the architecture of Apache Hadoop. With YARN, Apache Hadoop is recast as a significantly more powerful platform – one that takes Hadoop beyond merely batch applications to taking its position as a ‘data operating system’ where HDFS is the file system and YARN is the operating system.
YARN is a re-architecture of Hadoop that allows multiple applications to run on the same platform. With YARN, applications run “in” Hadoop, instead of “on” Hadoop:

Data Transformation
Skills of the Agile Data Wrangler
By Joe Hellerstein and Jeff Heer
As data processing has become more sophisticated, there has been little progress on improving the most time-consuming and tedious parts of the pipeline: Data Transformation tasks including discovery, structuring, and content cleaning . In standard practice, this kind of “data wrangling” requires writing idiosyncratic scripts in programming languages such as Python or R, or extensive manual editing using interactive tools such as Microsoft Excel. The result has two significantly negative outcomes. First, people with highly specialized skills (e.g., statistics, molecular biology, micro-economics) spend far more time in tedious data wrangling tasks than they do in exercising their specialty. Second, less technical users are often unable to wrangle their own data. The result in both cases is that significant data is often left unused due to the hurdle of transforming it into shape. Sadly, when it comes to standard practice in modern data analysis, “the tedium is the message.” In our upcoming tutorial at Strata, we will survey both sources and solutions to the problems of Data Transformation.
Analysts must regularly transform data to make it palatable to databases, statistics packages, and visualization tools. Data sets also regularly contain missing, extreme, duplicate or erroneous values that can undermine the results of analysis. These anomalies come from various sources, including human data entry error, inconsistencies between integrated data sets, and sensor interference. Our own interviews with data analysts have found that these types of transforms constitute the most tedious component of their analytic process. Flawed analyses due to dirty data are estimated to cost billions of dollars each year. Discovering and correcting data quality issues can also be costly: some estimate cleaning dirty data to account for 80 percent of the cost of data warehousing projects.
Six reasons why I recommend scikit-learn
It's an extensive, well-documented, and accessible, curated library of machine-learning models
I use a variety of tools for advanced analytics, most recently I’ve been using Spark (and MLlib), R, scikit-learn, and GraphLab. When I need to get something done quickly, I’ve been turning to scikit-learn for my first pass analysis. For access to high-quality, easy-to-use, implementations1 of popular algorithms, scikit-learn is a great place to start. So much so that I often encourage new and seasoned data scientists to try it whenever they’re faced with analytics projects that have short deadlines.
I recently spent a few hours with one of scikit-learn’s core contributors Olivier Grisel. We had a free flowing discussion were we talked about machine-learning, data science, programming languages, big data, Paris, and … scikit-learn! Along the way, I was reminded by why I’ve come to use (and admire) the scikit-learn project.
Commitment to documentation and usability
One of the reasons I started2 using scikit-learn was because of its nice documentation (which I hold up as an example for other communities and projects to emulate). Contributions to scikit-learn are required to include narrative examples along with sample scripts that run on small data sets. Besides good documentation there are other core tenets that guide the community’s overall commitment to quality and usability: the global API is safeguarded, all public API’s are well documented, and when appropriate contributors are encouraged to expand the coverage of unit tests.
Models are chosen and implemented by a dedicated team of experts
scikit-learn’s stable of contributors includes experts in machine-learning and software development. A few of them (including Olivier) are able to devote a portion of their professional working hours to the project.
Covers most machine-learning tasks
Scan the list of things available in scikit-learn and you quickly realize that it includes tools for many of the standard machine-learning tasks (such as clustering, classification, regression, etc.). And since scikit-learn is developed by a large community of developers and machine-learning experts, promising new techniques tend to be included in fairly short order.
As a curated library, users don’t have to choose from multiple competing implementations of the same algorithm (a problem that R users often face). In order to assist users who struggle to choose between different models, Andreas Muller created a simple flowchart for users: