"stratablog" entries

Sequencing, cloud computing, and analytics meet around genetics and pharma
Bio-IT World shows what is possible and what is being accomplished
If your data consists of one million samples, but only 100 have the characteristics you’re looking for, and if each of the million samples contains 250,000 attributes, each of which is built of thousands of basic elements, you have a big data problem. This is kind of challenge faced by the 2,700 Bio-IT World attendees, who discover genetic interactions and create drugs for the rest of us.
Often they are looking for rare (orphan) diseases, or for cohorts who share a rare combination of genetic factors that require a unique treatment. The data sets get huge, particularly when the researchers start studying proteomics (the proteins active in the patients’ bodies).
So last week I took the subway downtown and crossed the two wind- and rain-whipped bridges that the city of Boston built to connect to the World Trade Center. I mingled for a day with attendees and exhibitors to find what data-related challenges they’re facing and what the latest solutions are. Here are some of the major themes I turned up.

Citizens as partners in the use of clinical data
A Knowledge Currency Exchange for health and wellness
This article was written together with Mike Kellen, Director of Technology at Sage Bionetworks, and Christine Suver, Senior Scientist at Sage Bionetworks.
The current push towards patient engagement, when clinical researchers trace the outcomes of using pharmaceuticals or other treatments, is a crucial first step towards rewiring the medical-industrial complex with the citizen at the center. For far too long, clinicians, investigators, the government, and private funders have been the key decision makers. The citizen has been at best a research “subject,”and far too often simply a resource from which data and samples can be extracted. The average participant in clinical study never receives the outcomes of the study, never has contact with those analyzing the data, never knows where her samples flow over time (witness the famous story of Henrietta Lacks), and until the past year didn’t even have access to the published research without paying a hefty rental fee.
This is changing. The recent grants by the Patient-Centered Outcomes Research Institute (PCORI) are the most visible evidence of change, but throughout the medical system one finds green shoots of direct patient engagement. Read more…

Culture’s impact on social media adoption
Commerce and censorship in in cross-cultural social media.
Culture has a huge impact on social media adoption and usage. In Measuring Culture, I talked about specific cultural traits and attitudes, and I described how those things are being measured on social media. For this article, I’ll outline broader patterns in cross-cultural social media, specifically regarding commerce and censorship.
Commerce finds a way
Commerce always finds a way. Whether restricted by red tape or blocked by citizens’ mutual distrust, money flows around obstacles. Most examples don’t have much cultural data-crunching associated with them yet, but there are intriguing gestures in that direction. For instance, a recent survey from the European Commission reported that 62% of European Internet users say they use non-native language sites to communicate with friends online, but only 18% would use a non-native language site to buy something. Read more…

Network Science dashboards
Networks graphs can be used as primary visual objects with conventional charts used to supply detailed views
With Network Science well on its way to being an established academic discipline, we’re beginning to see tools that leverage it. Applications that draw heavily from this discipline make heavy use of visual representations and come with interfaces aimed at business users. For business analysts used to consuming bar and line charts, network visualizations take some getting used. But with enough practice, and for the right set of problems, they are an effective visualization model.
In many domains, networks graphs can be the primary visual objects with conventional charts used to supply detailed views. I recently got a preview of some dashboards built using Financial Network Analytics (FNA). Read more…
Measuring culture
Digital media influences culture -- and it's influenced by culture in turn
Digital media influences culture — and it’s influenced by culture in turn. Culture matters in business: Facebook just spent an astonishing $19 billion to acquire WhatsApp because of WhatsApp’s international presence. Culture also matters politically: Turkey’s leader recently made it the latest country to try blocking Twitter. How can we use data to understand culture’s impact on digital media adoption and usage? How can we even measure culture in the first place?
Dimensions of Culture, And How They’re Being Measured
Language
Some cross-cultural elements are easy to see. For example, when a brand or platform expands into a new country, their stuff should obviously be translated. Sometimes marketers use basic analytical tools to cut words that are controversial in a given culture, like the Chinese localization service Kawo, which screens English tweets for words that would be sensitive in China before any actual translation is done.

Solving mysteries using predictive analytics
In-depth Strata community profile on Kira Radinsky
Kira Radinsky started coding at the age of four, when her mother and aunt encouraged her to excel at one of her favorite computer games by writing a few simple lines of code. Since then, she’s been a firecracker in the field of predictive analytics, building algorithms to improve business interactions, and create a data-driven economy, and in the past, building systems to detect outbreaks of disease and social unrest around the world. She also gave a predictive analytics talk at the last Strata.
I had a conversation with Kira last month about her entry into the field and her most exciting moments thus far.
When did you first become interested in science?

Photo provided courtesy of Kira Radinsky
Kira Radinsky: When I was four or five, my mom bought me a computer game. In order to go to the next level, you had solve simple math problems, which became increasingly harder with time. At one point I couldn’t solve one of the problems. Then I asked my aunt for help because she was a software engineer. She showed me how to write some very simple code in order to proceed to the next level in the game. This was my first time to actually code something.
In the army, I was a software engineer. I built big systems. I felt that I was contributing to my country and it was amazing for me. When I finished my service, I was accepted to the excellence program at the Technion [Israel Institute of Technology] because I had already started studying there when I was 15. I just continued on to a graduate degree.
I knew I wanted to do something in the field of artificial intelligence, because I really wanted to pursue the idea of using computers to make a global impact. I was really into that. I realized that the vast data amounts that we produce could be used to solve important problems.
In 2011, thousands of birds fell out of the sky on New Years Eve. People were writing “we don’t know what’s going on”. It was a conundrum. A few days later, a hundred thousand fish washed up dead on the shore. Many people were saying that it was the end of the world because it was the end of the Mayan calendar!

Changes in the health care system driven by self-service and DIY health
Apps reflect the public's pressing health concerns
Health care is migrating from the bricks-and-mortar doctor’s office or care clinic to the person him or herself at home and on-the-go–where people live, work, play, and pray. As people take on more do-it-yourself (DIY) approaches to everyday life–investing money on financial services websites, booking airline tickets and hotel rooms online, and securing dinner reservations via OpenTable–many also ask why they can’t have more convenient access to health care, like emailing doctors and looking into lab test results in digital personal health records.
The public clamor for digital outreach by health providers
85% of U.S. health consumers say that email, text messages, and voicemail are at least as helpful as in-person or phone conversations with health providers, according to the Healthy World study, Technology Beyond the Exam Room by TeleVox. Furthermore, one in three consumers admits to being more honest when talking about medical needs via automated voice response systems, emails, or texts than face-to-face with a health provider.
And three in ten consumers believe that receiving digital health care communications from providers—such as texts, voicemail, or email—would build trust with their providers. Half of people also say they’d feel more valued as a patient via digital health communications. When people look to engage in health with an organization, the most important enabling factors are trust and authenticity.

Ag+Data
"Do you want to become a farmer?!” In a sense, yes.
Two years ago an informal group met for drinks in downtown Palo Alto: a mix of grad students, investors, and data science experts in Silicon Valley. In the back and forth of our conversation, we took turns describing planned projects. At the time, prominent VC firms were racing headlong into health care ventures. Much of our group seemed pointed in that direction.
In my turn, I mentioned one word: Agriculture.
That drew laughter, “You want to become a farmer?!”
In a sense, yes.
Impact of data science beyond silicon valley
Practices involving large-scale data, machine learning, cluster computing, etc., toppled entire sectors over the past decade. Retail (Amazon) went first, followed closely by Advertising (Google). Automotive (Tesla) may be next. Clearly, the impact of data science has moved beyond Silicon Valley, with mainstream industries leveraging data that matters… not simply to improve marketing funnels, rather to overhaul their supply chains, manufacturing, global deployments, etc. Advances in remote sensing and “Industrial Internet” accelerate that process, with IoT data rates growing orders of magnitude beyond what social networks have experienced, compelling new technologies.
Sometimes when a group of insiders starts guffawing, there is perhaps a subtle point being missed. Consider that Silicon Valley has spent the past decade extracting billions from e-commerce, ad-tech, social networks, anti-fraud, etc. Extracting is the quintessential word there. I wondered: among the industries outside of Silicon Valley undergoing disruptions due to large-scale data, where did Agriculture fit? Why did it seem laughable to experts as a data science opportunity?
Verticalized Big Data solutions
General-purpose platforms can come across as hammers in search of nails
As much as I love talking about general-purpose big data platforms and data science frameworks, I’m the first to admit that many of the interesting startups I talk to are focused on specific verticals. At their core big data applications merge large amounts of real-time and static data to improve decision-making:
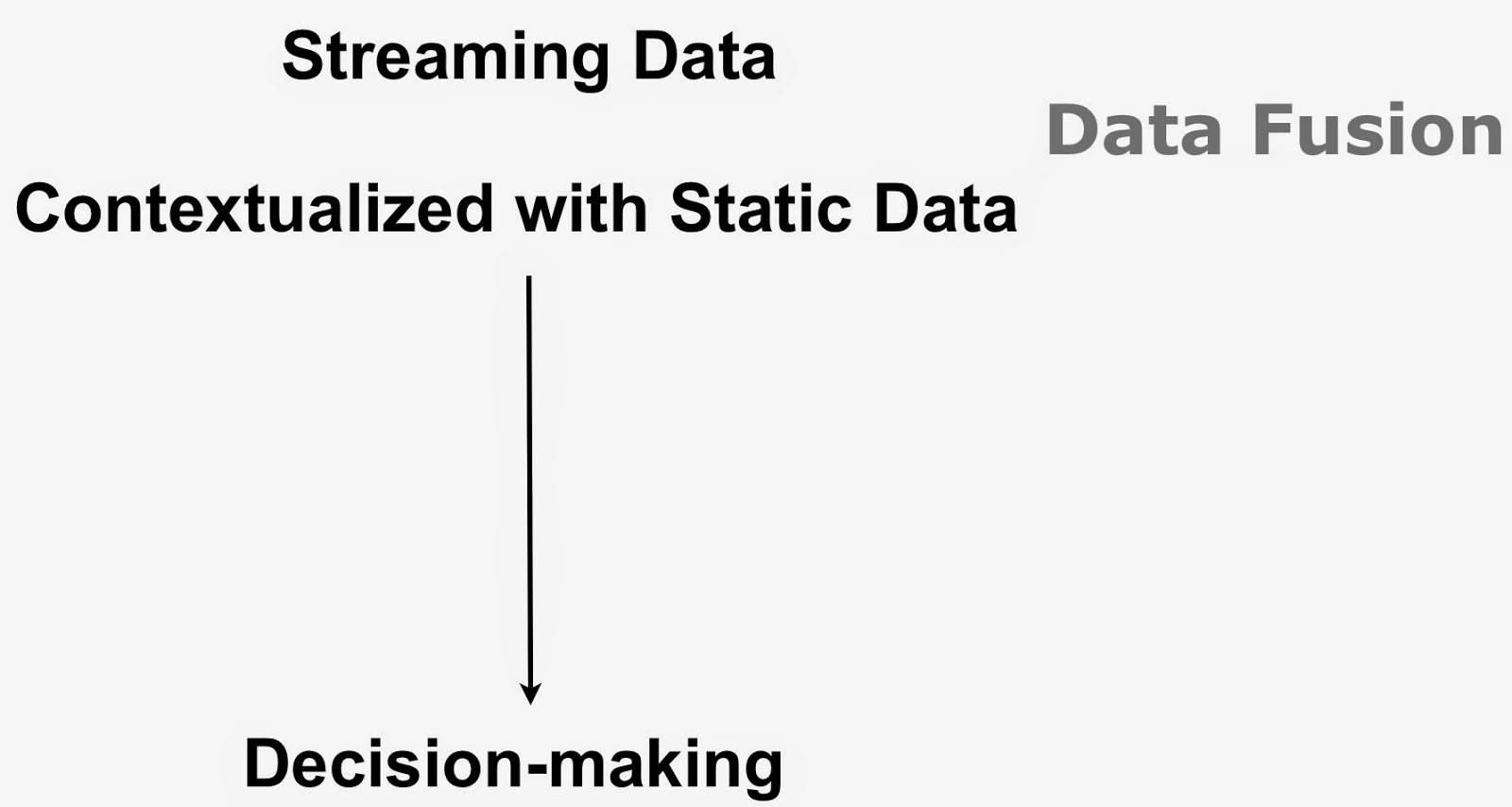
This simple idea can be hard to execute in practice (think volume, variety, velocity). Unlocking value from disparate data sources entails some familiarity with domain-specific1 data sources, requirements, and business problems.
It’s difficult enough to solve a specific problem, let alone a generic one. Consider the case of Guavus – a successful startup that builds big data solutions for the telecom industry (“communication service providers”). Its founder was very familiar with the data sources in telecom, and knew the types of applications that would resonate within that industry. Once they solve one set of problems for a telecom company (network optimization), they quickly leverage the same systems to solve others (marketing analytics).
This ability to address a variety of problems stems from Guavus’ deep familiarity with data and problems in telecom. In contrast, a typical general-purpose platform can come across as a hammer in search of a nail. So while I remain a fan (and user) of general-purpose platforms, the less well-known verticalized solutions are definitely on my radar.
Better tools can’t overcome poor analysis
I’m not suggesting that the criticisms raised against big data don’t apply to verticalized solutions. But many problems are due to poor analysis and not the underlying tools. A few of the more common criticisms arise from analyzing correlations: correlation is not causation, correlations are dynamic and can sometimes change drastically2, and data dredging3.
Related Content:
- The backlash against big data, continued
- The CFP for Strata New York + Hadoop World 2014 is now open!
- Strata Santa Clara 2014 Video Compilation
- Financial analytics as a service
(0) This post grew out of a recent conversation with Guavus founder, Anukool Lakhina.
(1) General-purpose platforms and components are helpful, but they usually need to be “tweaked” or “optimized” to solve problems in a variety of domains.
(2) When I started working as a quant at a hedge fund, traders always warned me that correlations jump to 1 during market panics.
(3) The best example comes from finance and involves the S&P 500 and butter production in Bangladesh.
Bridging the divide between big data and (big) algorithms
Strata SC 2014 Session Postmortem
In February, GraphLab took a road trip to Strata, a Big Data conference organized by O’Reilly. It was a gathering of close to 3100 people–engineers, business folks, industry evangelists, and data scientists. We had a lot of fun meeting and socializing with our peers and customers. Amidst all the conference excitement, we presented two talks. Carlos Guestrin, our intrepid CEO, held a tutorial on large-scale machine learning. I gave a talk in the Hardcore Data Science track.