"StrataRX" entries

The democratization of medical science
An interview with Ash Damle of Lumiata on the role of data in healthcare.
Vinod Khosla has stirred up some controversy in the healthcare community over the last several years by suggesting that computers might be able to provide better care than doctors. This includes remarks he made at Strata Rx in 2012, including that, “We need to move from the practice of medicine to the science of medicine. And the science of medicine is way too complex for human beings to do.”
So when I saw the news that Khosla Ventures has just invested $4M in Series A funding into Lumiata (formerly MEDgle), a company that specializes in healthcare data analytics, I was very curious to hear more about that company’s vision. Ash Damle is the CEO at Lumiata. We recently spoke by phone to discuss how data can improve access to care and help level the playing field of care quality.
Tell me a little about Lumiata: what it is and what it does.

A Lumiata network graph of diagnosis interrelation.
Ash Damle: We’re bringing together the best of medical science and graph analytics to provide the best prescriptive analysis to those providing care. We data-mine all the publicly available data sources, such as journals, de-identified records, etc. We analyze the data to make sure we’re learning the right things and, most importantly, what the relationships are among the data. We have fundamentally delved into looking at that whole graph, the way Google does to provide you with relevant search results. We curate those relationships to make sure they’re sensible, and take into account behavioral and social factors.

Big Data systems are making a difference in the fight against cancer
Open source, distributed computing tools speedup an important processing pipeline for genomics data
As open source, big data tools enter the early stages of maturation, data engineers and data scientists will have many opportunities to use them to “work on stuff that matters”. Along those lines, computational biology and medicine are areas where skilled data professionals are already beginning to make an impact. I recently came across a compelling open source project from UC Berkeley’s AMPLab: ADAM is a processing engine and set of formats for genomics data.
Second-generation sequencing machines produce more detailed and thus much larger files for analysis (250+ GB file for each person). Existing data formats and tools are optimized for single-server processing and do not easily scale out. ADAM uses distributed computing tools and techniques to speedup key stages of the variant processing pipeline (including sorting and deduping):
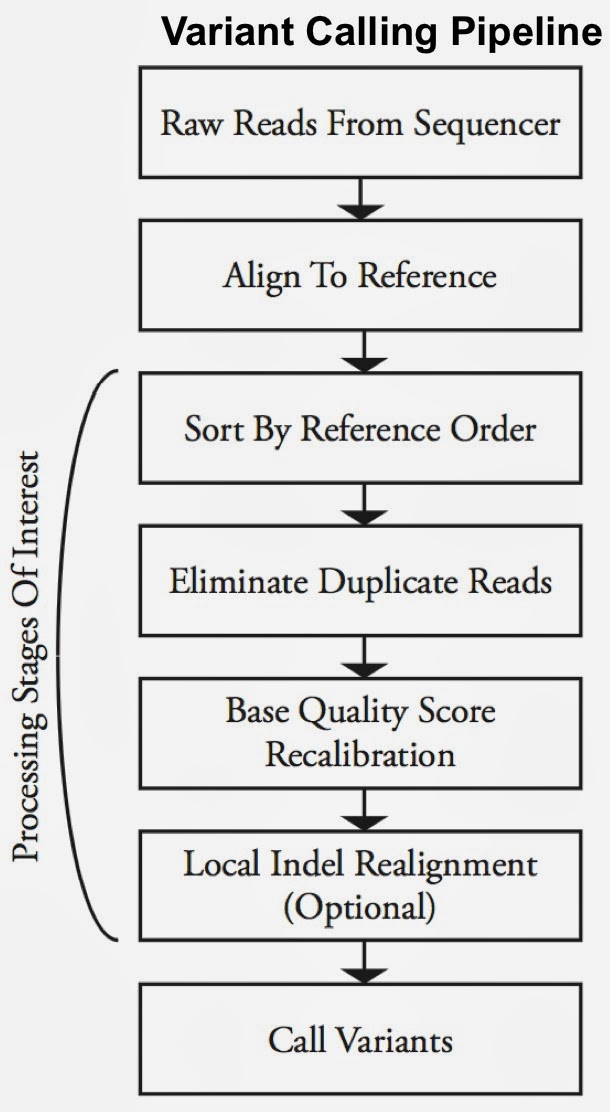
Very early on the designers of ADAM realized that a well-designed data schema (that specifies the representation of data when it is accessed) was key to having a system that could leverage existing big data tools. The ADAM format uses the Apache Avro data serialization system and comes with a human-readable schema that can be accessed using many programming languages (including C/C++/C#, Java/Scala, php, Python, Ruby). ADAM also includes a data format/access API implemented on top of Apache Avro and Parquet, and a data transformation API implemented on top of Apache Spark. Because it’s built with widely adopted tools, ADAM users can leverage components of the Hadoop (Impala, Hive, MapReduce) and BDAS (Shark, Spark, GraphX, MLbase) stacks for interactive and advanced analytics.

Data sharing drives diagnoses and cures, if we can get there (part 2)
How the field of genetics is using data within research and to evaluate researchers
Editor’s note: Earlier this week, Part 1 of this article described Sage Bionetworks, a recent Congress they held, and their way of promoting data sharing through a challenge.
Data sharing is not an unfamiliar practice in genetics. Plenty of cell lines and other data stores are publicly available from such places as the TCGA data set from the National Cancer Institute, Gene Expression Omnibus (GEO), and Array Expression (all of which can be accessed through Synapse). So to some extent the current revolution in sharing lies not in the data itself but in critical related areas.
First, many of the data sets are weakened by metadata problems. A Sage programmer told me that the famous TCGA set is enormous but poorly curated. For instance, different data sets in TCGA may refer to the same drug by different names, generic versus brand name. Provenance–a clear description of how the data was collected and prepared for use–is also weak in TCGA.
In contrast, GEO records tend to contain good provenance information (see an example), but only as free-form text, which presents the same barriers to searching and aggregation as free-form text in medical records. Synapse is developing a structured format for presenting provenance based on the W3C’s PROV standard. One researcher told me this was the most promising contribution of Synapse toward the shared used of genetic information.
Data sharing drives diagnoses and cures, if we can get there (part 1)
Observations from Sage Congress and collaboration through its challenge
The glowing reports we read of biotech advances almost cause one’s brain to ache. They leave us thinking that medical researchers must command the latest in all technological tools. But the engines of genetic and pharmaceutical innovation are stuttering for lack of one key fuel: data. Here they are left with the equivalent of trying to build skyscrapers with lathes and screwdrivers.
Sage Congress, held this past week in San Francisco, investigated the multiple facets of data in these field: gene sequences, models for finding pathways, patient behavior and symptoms (known as phenotypic data), and code to process all these inputs. A survey of efforts by the organizers, Sage Bionetworks, and other innovations in genetic data handling can show how genetics resembles and differs from other disciplines.
An intense lesson in code sharing
At last year’s Congress, Sage announced a challenge, together with the DREAM project, intended to galvanize researchers in genetics while showing off the growing capabilities of Sage’s Synapse platform. Synapse ties together a number of data sets in genetics and provides tools for researchers to upload new data, while searching other researchers’ data sets. Its challenge highlighted the industry’s need for better data sharing, and some ways to get there.
Making government health data personal again
An interview with Fred Smith of the CDC on their open content APIs.
Health care data liquidity (the ability of data to move freely and securely through the system) is an increasingly crucial topic in the era of big data. Most conversations about data liquidity focus on patient data, but other kinds of information need to be able to move freely and securely, too. Enter several government initiatives, including efforts at agencies within the Department of Health and Human Services (HHS) to make their content more easily available.
Fred Smith is team lead for the Interactive Media Technology Team in the Division of News and Electronic Media in the Office of the Associate Director for Communication for the U.S. Centers for Disease Control and Prevention (CDC) in Atlanta. We recently spoke by phone to discuss ways in which the CDC is working to make their information more “liquid”: easier to access, easier to repurpose, and easier to combine with other data sources.
Which data is available from the CDC APIs?

Fred Smith, CDC
Fred Smith: In essence, what we’re doing is taking our unstructured web content and turning it into a structured database, so we can call an API into it for reuse. It’s making our content available for our partners to build into their websites or applications or whatever they’re building.
Todd Park likes to talk about “liberating data” — well, this is liberating content. What is a more high-value dataset than our own public health messaging? It incorporates not only HTML-based text, but also we’re building this to include multimedia — whether it’s podcasts, images, web badges, or other content — and have all that content be aware of other content based on category or taxonomy. So it will be easy to query, for example: “What content does the CDC have on smoking prevention?”
Not just big data, but better data
Five ways we can improve the information we collect to help us solve hard problems in health care.
I was honored to chair O’Reilly’s inaugural edition of Strata Rx, our conference on data science in health care, this past October along with Colin Hill. As we’re beginning to plan this year’s event, I find myself thinking a lot about a theme that emerged from some of the keynotes last fall: in order to solve the problems we’re facing in health care — to lower costs and provide more personal, targeted treatments to patients — we don’t just need more data; we need better data.
Much has been made about the era of big data we find ourselves in. But though the data we collect is straining the limits of our tools and models, we’re still not making the kind of headway we hoped for in areas like health care. So big data isn’t enough. We need better data.
What does it mean to have better data in health care? Here are some things on my list; perhaps you can think of others. Read more…

Preferred structures for cleaned-up doctor data
Which data formats should the DocGraph project support?
The DocGraph project has an interesting issue that I think will become a common one as the open data movement continues. For those that have not been keeping up, DocGraph was announced at Strata RX, described carefully on this blog, and will be featured again at Strata 2013. For those that do not care to click links, DocGraph is a crowdfunded open data set, which merges open data sources on doctors and hospitals.
As I recently described on the DocGraph mailing list, work is underway to acquire the data sets that we set out to merge. The issue deals with file formats.
The core identifier for doctors, hospitals and other healthcare entities is the National Provider Identifier (NPI). This is something like a Social Security number for doctors and hospitals. In fact it was created in part so that doctors would not need to use their Social Security numbers or other identifiers in order to participate in healthcare financial transactions (i.e. paid by insurance companies for their services). The NPI is the “one number to rule them” in healthcare and we want to map data from other sources accurately to that ID.
Each state releases none, one or several data files that can be purchased and also contain doctor data. But these file downloads are in “random file format X.” Of course we are not yet done with our full survey of the files and their formats, but I can assure you that they are mostly CSV files and a troubling number of PDF files. It is our job to take these files and merge them against the NPI, in order to provide a cohesive picture for data scientists.
But the data available from each state varies greatly. Sometimes they will have addresses, sometimes not. Sometimes they will have fax numbers, sometimes not, sometimes they will include medical school information, some will not. Sometimes they will simply include the name of the medical school, sometimes they will use a code. Sometimes when they use codes they will make up their own …
I am not complaining here. We knew what we were getting ourselves into when we took on the DocGraph project. The community at large has paid us well to do this work! But now we have a question? What data formats should we support? Read more…

Approaching ethics and big data
What to do when facing the stoic expressions that pop up during ethics discussions.
The other day I clicked on a message posted to the O’Reilly editors’ email list and the message text filled up almost the entire monitor screen. I must admit that I thought “Am I going to require another caffeine hit to read through this?”
I decided to take a chance, not take another break just then, and read the lengthy note. I didn’t need that caffeine hit after all. Apparently, neither did half a dozen other editors.
The note was about ethics.
In a previous life, I worked in the competitive intelligence field. I remember participating in a friendly confab at an industry event and then someone mentioned the word “e-t-h-i-c-s”. It was rather fascinating to see how that word elicited stoic faces. No one wanted to be the first person to say anything on that topic. Now when working at ORM, mention the word “ethics!” and folks are not shy about saying exactly what they think. Not. At. All.
During the discussion, Ethics of Big Data by Kord Davis, came up. While I was not the editor on this book, I did read it when I was in New York. It made my list of recommended books for people looking to jump into the world of big data. Why? Because I remembered the stoic poker faces from my previous life in competitive intelligence. Read more…
DocGraph: Open social doctor data
An inside look at DocGraph, a data project that shows how the U.S. health care system delivers care.
Notice, October 2015: Certain versions of this data have been retracted. Please read more here.
At Strata RX in October I announced the availability of DocGraph. This is the first project of NotOnly Development, which is a Not Only For Profit Health IT micro-incubator.
The DocGraph dataset shows how doctors, hospitals, laboratories and other health care providers team together to treat Medicare patients. This data details how the health care system in the U.S. delivers care.
You can read about the basics of this data release, and you can read about my motivations for making the release. Most importantly, you can still participate in our efforts to crowdfund improvements to this dataset. We have already far surpassed our original $15,000 goal, but you can still get early and exclusive access to the data for a few more days. Once the crowdfunding has ended, the price will go up substantially.
This article will focus on this data from a technical perspective.
In a few days, the crowdfunding (hosted by Medstartr) will be over, and I will be delivering this social graph to all of the participants. We are offering a ransom license that we are calling “Open Source Eventually,” so participants in the crowdfunding will get exclusive access to the data for a full six months before the license to this dataset automatically converts to a Creative Commons license. The same data is available under a proprietary-friendly license for more money. For all of these “releases,” this article will be the go-to source for technical details about the specific contents of the file.
How to open an industry: data points from Strata Rx
O'Reilly conference brings together health care and data
O’Reilly’s first conference devoted to health care, Strata Rx, wrapped up earlier this week. Despite competing with at least three other conferences being held on the same week around the country on various aspects of health care and technology, we drew a crowd that filled the ballroom during keynotes and spent the breaks networking more hungrily than they attacked the (healthy) food provided throughout.
Springing from O’Reilly’s Strata series about the use of data to change business and society, Strata Rx explored many other directions in health care, as a peek at the schedule will show. The keynotes were filmed and will soon appear online. The unique perspectives offered by expert speakers is evident, but what’s hard is making sense of the two days as a whole.
In this article I’ll try to show the underlying threads that tied together the many sessions about data analytics, electronic records, disruption in the health care industry, 21st-century genetics research, patient empowerment, and other themes. The essential message from the leading practitioners at Strata Rx is ultimately that no one in health care (doctors, administrators, researchers, regulators, patients) can practice their discipline in isolation any more. We are all going to have to work together.
We can’t wait for insights from others, expecting researchers to hand us ideal treatment plans or doctors to make oracular judgments. The systems are all interconnected now. And if we want healthy people, not to mention sustainable health care costs, we will have to play our roles in these systems with nuance and sophistication.
But I’ll get to this insight by steps. Let’s look at some major themes of Strata Rx. Read more…