"YARN" entries

A tale of two clusters: Mesos and YARN
With Myriad, analytics can be performed on the same hardware that runs your production services.
This is a tale of two siloed clusters. The first cluster is an Apache Hadoop cluster. This is an island whose resources are completely isolated to Hadoop and its processes. The second cluster is the description I give to all resources that are not a part of the Hadoop cluster. I break them up this way because Hadoop manages its own resources with Apache YARN (Yet Another Resource Negotiator). Which is nice for Hadoop, but all too often those resources are underutilized when there are no big data workloads in the queue. And then when a big data job comes in, those resources are stretched to the limit, and they are likely in need of more resources. That can be tough when you are on an island.
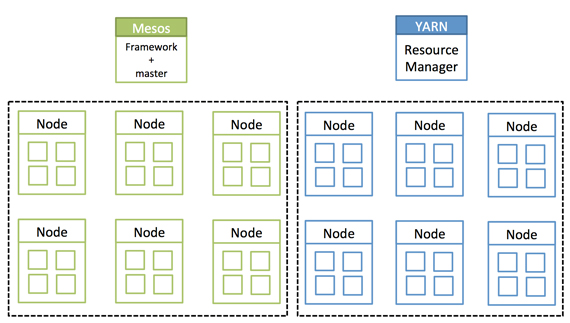
Isolated clusters. Source: Mesosphere and MapR, used with permission.
Hadoop was meant to tear down walls — albeit, data silo walls — but walls, nonetheless. What has happened is that while tearing some walls down, other types of walls have gone up in their place.
Another technology, Apache Mesos, is also meant to tear down walls — but Mesos has often been positioned to manage the “second cluster,” which are all of those other, non-Hadoop workloads.
This is where the story really starts, with these two silos of Mesos and YARN. They are often pitted against each other, as if they were incompatible. It turns out they work together, and therein lies my tale. Read more…