
Sections
For more than 25 years, data warehousing has been the accepted architecture for providing information to support decision makers. Despite numerous implementation approaches, it is founded on sound information management principles, most particularly that of integrating information according to a business-directed and predefined model before allowing use by decision makers. Big data, however one defines it, challenges some of the underlying principles behind data warehousing, causing some analysts to question if the data warehouse will survive.
In this article, I address this question directly and propose that data warehousing, and indeed information management as a whole, must evolve in a radically new direction if we are to manage big data properly and solve the key issue of finding implicit meaning in data.
Back in the 1980s I worked for IBM in Ireland, defining the first published data warehouse architecture (Devlin & Murphy, 1988). At that time, the primary driver for data warehousing was to reconcile data from multiple operational systems and to provide a single, easily-understood source of consistent information to decision makers. The architecture defined the “Business Data Warehouse (BDW) … [as] the single logical storehouse of all the information used to report on the business … In relational terms, the end user is presented with a view / number of views that contain the accessed data …” Note the phrase “single logical storehouse” — I’ll return to it later.
Big data (or what was big data then — a few hundred MB in many cases!) and the poor performance of early relational databases proved a challenge to the physical implementation of this model. Within a couple of years, the layered model emerged. Shown in Figure 1 (below), this has a central enterprise data warehouse (EDW) as a point of consolidation and reconciliation, and multiple user-access data marts fed from it. This implementation model has stood the test of time. But it does say that all data must (or should) flow through the EDW, the implications of which I’ll discuss later.
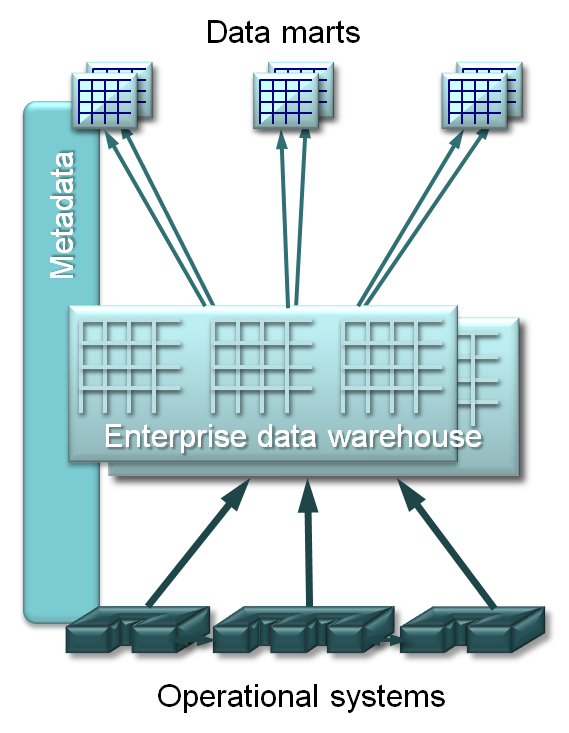
Figure 1: The Traditional Data Warehouse Architecture.
The current hype around “big data” has caused some analysts and vendors to declare the death of data warehousing, and in some cases, the demise even of the relational database.
A prerequisite to discussing these claims is to understand and clearly define the term “big data.” However, it’s a fairly nebulous concept. Wikipedia’s definition, as of December 2010, is vague and pliable:
Big Data is a term applied to data sets whose size is beyond the ability of commonly used software tools to capture, manage and process the data within a tolerable elapsed time. Big data sizes are a constantly moving target currently ranging from a few dozen terabytes to many petabytes in a single data set.
So, it’s as big as you want and getting ever larger.
A taxonomy for data — mind over matter
To get a better understanding, we need to look at the different types of data involved and, rather than focus on the actual data volumes, look to the scale and variety of processing required to extract implicit meaning from the raw data.
Figure 2 (below) introduces a novel and unique view of data, its categories and its relationship to meaning, which I call somewhat cheekily “Mind over Matter.”
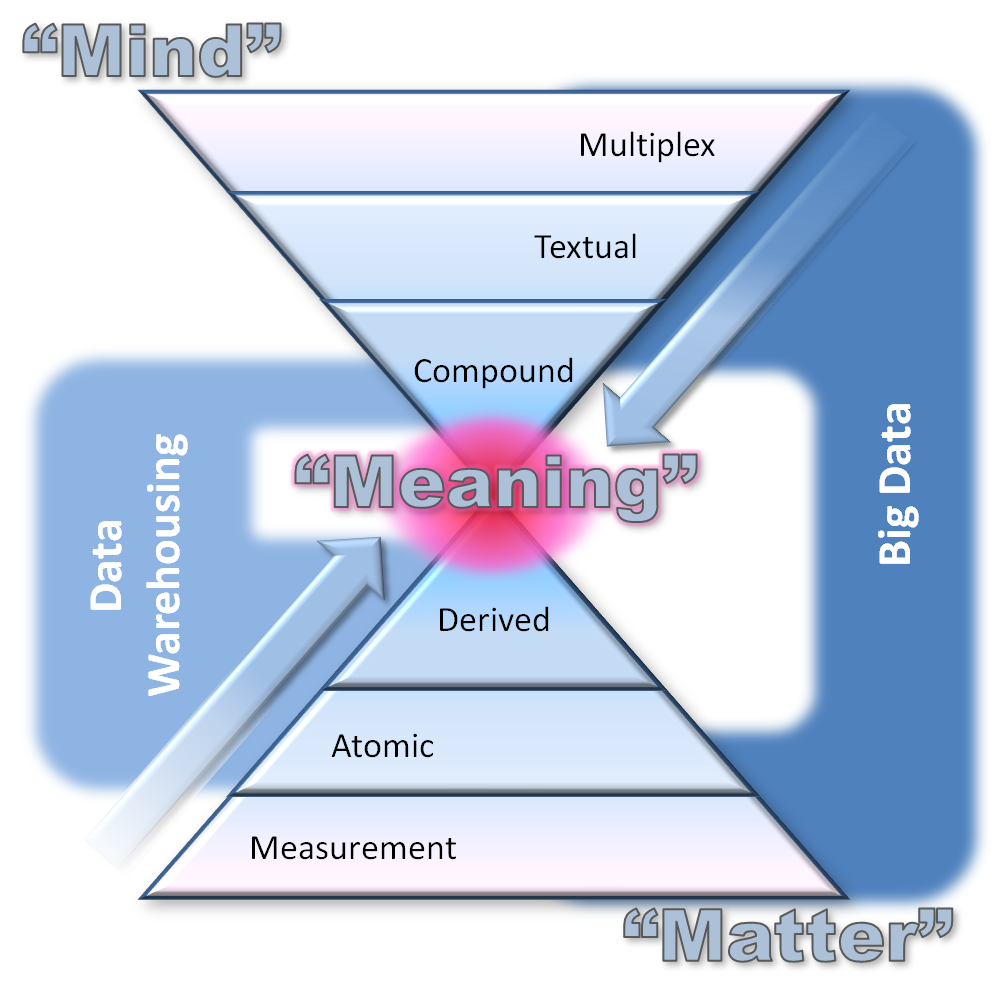
Figure 2: Mind over Matter and the Heart of Meaning.
Broadly speaking, the bottom pyramid represents data gleaned primarily from the physical world, the world of matter. At the lowest level, we have measurement data, sourced from a variety of sensors connected to computers and the Internet. Such physical event data includes location, velocity, flow rate, event count, G-force, chemical signal, and many more. Such measurements are widely used in science and engineering applications, and have grown to enormous volumes in areas such as particle physics, genomics and performance monitoring of complex equipment. This type of big data has been recognized by the scientific and engineering community for many years and is the basis for much modern research and development. When such basic data is combined in meaningful ways, it becomes interesting in the commercial world.
Atomic data is thus comprised of physical events, meaningfully combined in the context of some human interaction. For example, a combined set of location, velocity and G-force measurements in a specific pattern and time from an automobile monitoring box may indicate an accident. A magnetic card reading of account details, followed by a count of bills issued at an ATM, is clearly a cash withdrawal transaction. More sophisticated combinations include call detail records (CDRs) in telecom systems, web log records, e-commerce transactions and so on. There’s nothing new in this type of big data. Telcos, financial institutions and web retailers have statistically analyzed it extensively since the early days of data warehousing for insight into customer behavior and as a basis for advertising campaigns or offers aimed at influencing it.
Derived data, created through mathematical manipulation of atomic data, is generally used to create a more meaningful view of business information to humans. For example, banking transactions can be accumulated and combined to create account status and balance information. Transaction data can be summarized into averages or sampled. Some of these processes result in a loss of detailed data. This data type and the two below it in the lower pyramid comprise hard information, that is largely numerical and keyword data, well structured for use by computers and amenable to standard statistical processing.
As we move to the top pyramid, we enter the realm of the mind — information originating from the way we as humans perceive the world and interact socially within it. We also call this soft information — less well structured and requiring more specialized statistical and analytical processing. The top layer is multiplex data, image, video and audio information, often in smaller numbers of very large files and very much part of the big data scene. Very specialized processing is required to extract context and meaning from such data and extensive research is ongoing to create the necessary tools. The layer below — textual data — is more suited to statistical analysis and text analytics tools are widely used against big data of this type.
The final layer in our double pyramid is compound data, a combination of hard and soft information, typically containing the structural, syntactic and model information that adds context and meaning to hard information and bridges the gap between the two categories. Metadata is a very significant subset of compound data. It is part of the data/information continuum; not something to push out to one side of the information architecture as a separate box — as often seen in data warehousing architectures.
Compound data is the final category of data, and probably the category of most current interest in big data. It contains much social media information — a combination of hard web log data and soft textual and multimedia data from sources such as Twitter, Facebook and so on.
The width of each layer in the pyramids corresponds loosely to data volumes and numbers of records in each category. The outer color bands in Figure 2 place data warehousing and big data in context. The two concepts overlap significantly in the world of matter. The major difference is that big data includes and even focuses on the world of mind at the detailed, high volume level.
More importantly, the underlying reason we do data warehousing (more correctly, business intelligence, for which data warehousing is the architectural foundation) and analyze big data is essentially the same: we are searching for meaning in the data universe. And meaning resides at the conjoined apexes of the two pyramids.
Both data warehousing and big data begin with highly detailed data, and approach its meaning by moving toward very specific insights that are represented by small data sets that the human mind can grasp. The old nugget, now demoted to urban legend, of “men who buy diapers on Friday evenings are also likely to buy beer” is a case in point. Business intelligence works more from prior hypotheses, whereas big data uses statistics to extract hypotheses.
Now that we understand the different types of data and how big data and data warehousing relate, we can address the key question: does big data spell the end of data warehousing?
 Strata: Making Data Work, being held Feb. 1-3, 2011 in Santa Clara, Calif., will focus on the business and practice of data. The conference will provide three days of training, breakout sessions, and plenary discussions — along with an Executive Summit, a Sponsor Pavilion, and other events showcasing the new data ecosystem.
Strata: Making Data Work, being held Feb. 1-3, 2011 in Santa Clara, Calif., will focus on the business and practice of data. The conference will provide three days of training, breakout sessions, and plenary discussions — along with an Executive Summit, a Sponsor Pavilion, and other events showcasing the new data ecosystem.
Reports of my death are greatly exaggerated
Data warehousing, as we currently do it — and that’s a key phrase — is usually rather difficult to implement and maintain. The ultimate reason is that data warehousing seeks to ensure that enterprise-wide decision making is consistent and trusted. This was and is a valid and worthy objective, but it’s also challenging. Furthermore, it has driven two architectural aims:
- To define, create and maintain a reconciled, integrated set of enterprise data for decision making.
- That this set should be the single source for all decision-making needs, be they immediate or long-term, one-off or ongoing, throw-away or permanent.
The first of these aims makes sense: there are many decisions which should be based on reconciled and integrated information for commercial, legal or regulatory reasons. The second aim was always questionable — as shown, for example, by the pervasive use of spreadsheets — and becomes much more so as data volumes and types grow. Big data offers new, easier and powerful ways to interactively explore even larger data sets, most of which have never seen the inside of a data warehouse and likely never will.
Current data warehousing practices also encourage and, in many ways, drive the creation of multiple copies of data. Data is duplicated across the three layers of the architecture in Figure 1, and further duplicated in the functional silos of the data marts. What is more, the practice of building independent data marts fed directly from the operational environment and bypassing the EDW entirely is lamentably far too common. The advent of big data, with its large and growing data volumes, argues strongly against duplication of data. I’ve explored these issues and more in a series of articles on B-eye-Network (Devlin, 2010), concluding that a new inclusive architecture — Business Integrated Insight (BI2) — is required to extend existing data warehousing approaches.
Big data will give (re)birth to the data warehouse
As promised, it is time to return to the “single logical storehouse” of information required by the business. Back in the 1980s, that information was very limited in comparison to what business needs today, and its uses were similarly circumscribed. Today’s business needs both a far broader information environment and a much more integrated processing approach. A single logical storehouse is required with both a well-defined, consistent and integrated physical core, and a loose federation of data whose diversity, timeliness and even inconsistency is valued. In order to discuss this sensibly, we need some new terminology that minimizes confusion and contention between the advocates of the various different technologies and approaches.
The first term is “Business Information Resource” (BIR), introduced in a Teradata-sponsored white paper (Devlin, 2009), and defined as a single logical view of the entire information foundation of the business that aims to differentiate between different data uses and to reduce the tendency to duplicate data multiple times. Within a unified information space, the BIR has a conceptual structure allowing reasonable boundaries of business interest and implementation viability to be drawn (Devlin, 2010a). With such a broad scope, the BIR is clearly instantiated in a number of technologies, of which relational and XML databases, and distributed file and content stores such as Hadoop are key. Thus, the relational database technology of the data warehouse is focused on the creation and maintenance of a set of information that can support common and consistent decision making. Hadoop, MapReduce and similar technologies are directed to their areas of strength such as temporary, throw away data, fast turnaround reports where speed trumps accuracy, text analysis, graphs, large-scale quantitative analytical sand boxes, and web farm reporting. Furthermore, these stores are linked through virtual access technology that presents the separate physical stores to the business user as a single entity as and when required.
The second term, “Core Business Information” (CBI), from an Attivio-sponsored white paper (Devlin, 2010b), is the set of information that ensures the long-term quality and consistency of the BIR. This information needs to be modeled and defined at an early stage of the design and its content and structure subject to rigorous change management. While other information may undergo changes in definition or relationships over time, the CBI must remain very stable.
While space doesn’t permit a more detailed description here of these two concepts, the above-mentioned papers make clear that the CBI contains the information at the heart of a traditional enterprise data warehouse (and, indeed, of modern Master Data Management). The Business Information Resource, on the other hand, is a return to the conceptual basis of the data warehouse — a logical single storehouse of all the information required by the business, which, by definition, encompasses big data in all its glory.
Conclusions
While announcing the death of data warehousing and relational databases makes for attention-grabbing headlines, reality is more complex. Big data is actually a superset of the information and processes that have characterized data warehousing since its inception, with big data focusing on large-scale and often short-term analysis. With the advent of big data, data warehousing itself can return to its roots — the creation of consistency and trust in enterprise information. In truth, there exists a substantial overlap between the two areas; the precepts and methods of both are highly complementary and the two will be mandatory for all forward-looking businesses.
References
Devlin, B. A. and Murphy, P. T., “An architecture for a business and information system,” IBM Systems Journal, Volume 27, Number 1, Page 60 (1988) http://bit.ly/EBIS1988
Devlin, B., “Business Integrated Insight (BI2) — Reinventing enterprise information management,” White Paper, (2009) http://bit.ly/BI2_White_Paper
Devlin, B., “From Business Intelligence to Enterprise IT Architecture,” B-eye-Network, (2010) http://bit.ly/BI_to_ent_arch
Devlin, B., “Beyond Business Intelligence,” Business Intelligence Journal, Volume 15, Number 2, Page 7, (2010a) http://bit.ly/Beyond_BI
Devlin, B., “Beyond the Data Warehouse: A Unified Information Store for Data and Content,” White Paper, (2010b) http://bit.ly/uis_white_paper
Related: