
Here are a few of the data stories that caught my eye this week.
The Book Genome Project tries to unlock book DNA
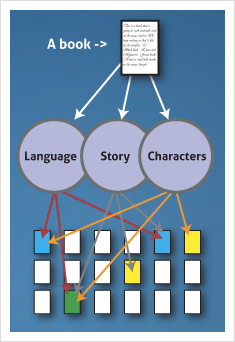 Recommendation engines for reading aren’t new. Amazon, for example, is more than happy to give you suggestions on what to read (or, rather, buy) next. But often these recommendations are based on the most popular titles. Even if you’re taking recommendations based on what your friends are reading — say, via sites like Goodreads — you’re still likely to see bestsellers rather than titles that match your particular taste or mood.
Recommendation engines for reading aren’t new. Amazon, for example, is more than happy to give you suggestions on what to read (or, rather, buy) next. But often these recommendations are based on the most popular titles. Even if you’re taking recommendations based on what your friends are reading — say, via sites like Goodreads — you’re still likely to see bestsellers rather than titles that match your particular taste or mood.
But BookLamp is working on building a better biblio-recommendation engine. BookLamp is the public face and the home of the Book Genome Project, a project founded in 2003 by students from the University of Idaho. Much like Pandora’s well-known Music Genome Project, the Book Genome Project contends that books can be broken down into small DNA-like components — the characteristics that make up the “genetic structure” of a book. These include things like language, characters, and story.
All told, one book can produce 32,162 “genomic measurements,” according to BookLamp. Unlike social reading or retail sites, this data doesn’t come from people’s tagging or purchasing behavior. Rather BookLamp gets data directly from publishers, ingesting the full texts of books. At the moment, BookLamp has participation from Random House and Kensington Publishers, making its literary catalog incomplete. Even so, the startup’s database currently tracks more than 617 million data points, or book DNA.
 Strata Conference New York 2011, being held Sept. 22-23, covers the latest and best tools and technologies for data science — from gathering, cleaning, analyzing, and storing data to communicating data intelligence effectively.
Strata Conference New York 2011, being held Sept. 22-23, covers the latest and best tools and technologies for data science — from gathering, cleaning, analyzing, and storing data to communicating data intelligence effectively.
Analyzing the entire Wikipedia data dump with WikiHadoop
One of the largest free datasets on the Internet is, as Diederik van Liere points out, the full XML data dump from the English version of Wikipedia. It’s openly available, sure, but coming in at more than 5.5 terabytes and growing, it’s hardly easy to take that dataset and download and/or analyze it. And while Hadoop seems like it might be the ideal tool to do the latter, that’s also easier said than done.
But in a blog post this week, van Liere points to WikiHadoop, a project undertaken by the Wikimedia Foundation’s Summer of Research.
WikiHadoop addresses some of the problems that make StreamXmlRecordReader unsuitable for analyzing the full Wikipedia data dump. In his post van Liere outlines some of WikiHadoop’s features:
- WikiHadoop uses Hadoop’s streaming interface, so you can write your own mapper in Python, Ruby, Hadoop Pipes or Java.
- You can choose between sending 1 or 2 revisions to a mapper. If you choose two revisions then it will send two consecutive revisions from a single page to a mapper.
- You can specify which namespaces to include when parsing the XML files. Default behavior is to include all namespaces.
- You can parse both bz2 compressed and uncompressed files using WikiHadoop.
On behalf of data geeks everywhere, thanks to the Wikimedia Summer of Research fellows!
The rise of the “Data Civilization”
Although this falls loosely under the “visualization of the week” category, it’s an interesting story nonetheless. The computational knowledge engine WolframAlpha released a “Timeline of Systematic Data and Computational Knowledge.” It’s a story, says WolframAlpha, “of how, in a multitude of steps, our civilization has systematized more and more areas of knowledge — collected the data associated with them, and gradually made them amenable to automation.”
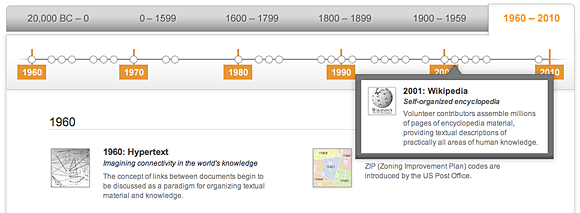
Screenshot from WolframAlpha’s Timeline of Systematic Data and Computational Knowledge.
The timeline begins circa 20,000 BC with the invention of arithmetic and progresses through to the present. It’s an interesting chronology to be sure, but when you look at the number of entries per decade and per century, you can see how rapidly we are seeing important data events. As Wolfram’s Stephen Wolfram observes, “… to me what’s somewhat remarkable is that nearly 20% of what’s on the timeline was already done by 1000 AD, 40% by 1800 and 60% by 1900. If one looks at the last 500 years, though, there’s a surprisingly good fit to an exponential increase, doubling every 95 years.”
It’s not Moore’s Law, but it does make for a nice poster.
Got data news?
Feel free to email me.
Related: