- Things Software Leaders Should Know (Ben Gracewood) — If you have people things and tech things on your to-do list, put the people things first on the list.
- The Hadoop Ecosystem — table of the different projects across the Hadoop ecosystem.
- Narcos GPS-Spoofing Border Drones — not only are the border drones expensive and ineffective, now they’re being tricked. Basic trade-off: more reliability or longer flight times?
- A Model Explanation System (PDF) — you can explain any machine-learned decision, though not necessarily the way the model came to the decision. Confused? This summary might help. Explainability is not a property of the model.
"Hadoop" entries

Four short links: 23 December 2015
Software Leaders, Hadoop Ecosystem, GPS Spoofing, and Explaining Models

Jai Ranganathan on architecting big data applications in the cloud
The O’Reilly Data Show podcast: The Hadoop ecosystem, the recent surge in interest in all things real time, and developments in hardware.
Subscribe to the O’Reilly Data Show Podcast to explore the opportunities and techniques driving big data and data science.
_(14760632446).jpg)
Given the quick pace of innovation in the data ecosystem, we like to take a step back from the details of individual components, architecture, and applications, in order to take a wider view of the landscape of big data. This allows us to evaluate the progress of technology and infrastructure along the way, shifting our attention from the details of individual components like Spark and Kafka, to larger trends.
Some of the larger trends we’ve been exploring include the capabilities of distributed machine learning and the tradeoffs and design decisions involved in cloud architecture and stream processing.
In this episode of the O’Reilly Data Show, I sat down with Jai Ranganathan, senior director of product management at Cloudera. We talked about the trends in the Hadoop ecosystem, cloud computing, the recent surge in interest in all things real time, and hardware trends:
Large-scale machine learning
This sounds a bit like this should already exist in really good form right now, but one of the things that I’m really interested in is expanding the set of capabilities for distributed machine learning. While there are systems out there today that do do this, I think relative to what you can experience from a singular environment learning scikit-learn or R, the set of things you can do in a distributed fashion is limited. … It’s not easy to distribute various algorithms and model-building techniques. I think there is still a lot of work for us to do to improve that experience. … And I do want to have good open source options like MLlib. MLlib may be the right answer. I would be perfectly happy if that’s the final answer, but we do need systems just to provide the kind of depth that you typically are used to in the singular environment. That’s just a matter of time and investment because these are non-trivial problems, but they are things that people are working on.
Four short links: 15 September 2015
Bot Bucks, Hadoop Database, Futurism Biases, and Tactile Prosthetics
- Ashley Madison’s Fembot Con (Gizmodo) — As documents from company e-mails now reveal, 80% of first purchases on Ashley Madison were a result of a man trying to contact a bot, or reading a message from one.
- Terrapin — Pinterest’s low-latency NoSQL replacement for HBase. See engineering blog post.
- Why Futurism Has a Cultural Blindspot (Nautilus) — As the psychologist George Lowenstein and colleagues have argued, in a phenomenon they termed “projection bias,” people “tend to exaggerate the degree to which their future tastes will resemble their current tastes.”
- Mind-Controlled Prosthetic Arm (Quartz) — The robotic arm is connected by wires that link up to the wearer’s motor cortex — the part of the brain that controls muscle movement — and sensory cortex, which identifies tactile sensations when you touch things. The wires from the motor cortex allow the wearer to control the motion of the robot arm, and pressure sensors in the arm that connect back into the sensory cortex give the wearer the sensation that they are touching something.
From search to distributed computing to large-scale information extraction
The O'Reilly Data Show Podcast: Mike Cafarella on the early days of Hadoop/HBase and progress in structured data extraction.
Subscribe to the O’Reilly Data Show Podcast to explore the opportunities and techniques driving big data and data science.
 February 2016 marks the 10th anniversary of Hadoop — at a point in time when many IT organizations actively use Hadoop, and/or one of the open source, big data projects that originated after, and in some cases, depend on it.
February 2016 marks the 10th anniversary of Hadoop — at a point in time when many IT organizations actively use Hadoop, and/or one of the open source, big data projects that originated after, and in some cases, depend on it.
During the latest episode of the O’Reilly Data Show Podcast, I had an extended conversation with Mike Cafarella, assistant professor of computer science at the University of Michigan. Along with Strata + Hadoop World program chair Doug Cutting, Cafarella is the co-founder of both Hadoop and Nutch. In addition, Cafarella was the first contributor to HBase.
We talked about the origins of Nutch, Hadoop (HDFS, MapReduce), HBase, and his decision to pursue an academic career and step away from these projects. Cafarella’s pioneering contributions to open source search and distributed systems fits neatly with his work in information extraction. We discussed a new startup he recently co-founded, ClearCutAnalytics, to commercialize a highly regarded academic project for structured data extraction (full disclosure: I’m an advisor to ClearCutAnalytics). As I noted in a previous post, information extraction (from a variety of data types and sources) is an exciting area that will lead to the discovery of new features (i.e., variables) that may end up improving many existing machine learning systems. Read more…

Hadoop for business: Analytics across industries
The O’Reilly Podcast: Ben Sharma on the business impact of Hadoop and the evolution of tools

In this episode of the O’Reilly Podcast, O’Reilly’s Ben Lorica chats with Ben Sharma, CEO and co-founder of Zaloni, a company that provides enterprise data management solutions for Hadoop. Sharma was one of the first users of Apache Hadoop, and has a background in enterprise solutions architecture and data analytics.
Before starting Zaloni, Sharma spent many years as a business consultant and began to see that companies across industries were struggling to process, store, and extract value from their data. Having worked extensively in telecom, Sharma helped equipment vendors deploy large-scale network infrastructures at carriers across the world. He began to see how Hadoop could have an impact in the business analytics aspect of companies, not just in IT.
In this interview, Lorica and Sharma discuss the early days of Hadoop and how businesses across industries are benefitting from Hadoop. They also discuss the evolution of tools in the space and how more companies are moving toward real-time decision-making with the growth of streaming tools and real-time data. Read more…

How an enterprise begins its big data journey
An ETL offload solution addresses the challenges of data overload, rising costs, and the skills gap.

As the amount of data continues to double in size every two years, organizations are struggling more than ever before to manage, ingest, store, process, transform, and analyze massive data sets. It has become clear that getting started on the road to using data successfully can be a difficult task, especially with a growing number of new data sources, demands for fresher data, and the need for increased processing capacity. In order to advance operational efficiencies and drive business growth, however, organizations must address and overcome these challenges.
In recent years, many organizations have heavily invested in the development of enterprise data warehouses (EDW) to serve as the central data system for reporting, extract/transform/load (ETL) processes, and ways to take in data (data ingestion) from diverse databases and other sources both inside and outside the enterprise. Yet, as the volume, velocity, and variety of data continues to increase, already expensive and cumbersome EDWs are becoming overloaded with data. Furthermore, traditional ETL tools are unable to handle all the data being generated, creating bottlenecks in the EDW that result in major processing burdens.
As a result of this overload, organizations are now turning to open source tools like Hadoop as cost-effective solutions to offloading data warehouse processing functions from the EDW. While Hadoop can help organizations lower costs and increase efficiency by being used as a complement to data warehouse activities, most businesses still lack the skill sets required to deploy Hadoop. Read more…

Navigating the Hadoop ecosystem
A field guide to the Apache Hadoop projects, subprojects, and related technologies.
Marshall Presser, co-author of Field Guide to Hadoop, contributed to this post.

IT managers, developers, data analysts, and system architects are encountering the largest and most disruptive change in data analysis since the ascendency of the relational database in early 1980s — the challenge to process, organize, and take full advantage of big data. With 73% of organizations making big data investments in 2014 and 2015, this transition is occurring at a historic pace, requiring new ways of thinking to go along with new tools and techniques.
Hadoop is the cornerstone of this change to a landscape of systems and skills we’ve traditionally possessed. In the nine short years since the project revolutionized data science at Yahoo!, an entire ecosystem of technologies has sprung up around it. While the power of this ecosystem is plain to see, it can be a challenge to navigate your way through the complex and rapidly evolving collection of projects and products.
A couple years ago, my coworker Marshall Presser and I started our journey into the world of Hadoop. Like many folks, we found the company we worked for was making a major investment in the Hadoop ecosystem, and we had to find a way to adapt. We started in all of the typical places — blog posts, trade publications, Wikipedia articles, and project documentation. Quickly, we learned that many of these sources are often highly biased, either too shallow or too deep, and just plain inconsistent. Read more…
Four short links: 16 February 2015
Grace Hopper, Car Dashboard UIs, DAO Governance, and Sahale.
- The Queen of Code — 12m documentary on Grace Hopper, produced by fivethirtyeight.com.
- Car Dashboard UI Collection — inspiration board for your (data) dashboards.
- Subjectivity-Exploitability Tradeoff — Voting-based DAOs, lacking an equivalent of shareholder regulation, are vulnerable to attacks where 51% of participants collude to take all of the DAO’s assets for themselves […] The example supplied here will define a new, third, hypothetical form of blockchain or DAO governance. Every day we’re closer to Stross’s Accelerando.
- Sahale — open source cascading workflow visualizer to help you make sense of tasks decomposed into Hadoop jobs. (via Code as Craft)

A tale of two clusters: Mesos and YARN
With Myriad, analytics can be performed on the same hardware that runs your production services.
This is a tale of two siloed clusters. The first cluster is an Apache Hadoop cluster. This is an island whose resources are completely isolated to Hadoop and its processes. The second cluster is the description I give to all resources that are not a part of the Hadoop cluster. I break them up this way because Hadoop manages its own resources with Apache YARN (Yet Another Resource Negotiator). Which is nice for Hadoop, but all too often those resources are underutilized when there are no big data workloads in the queue. And then when a big data job comes in, those resources are stretched to the limit, and they are likely in need of more resources. That can be tough when you are on an island.
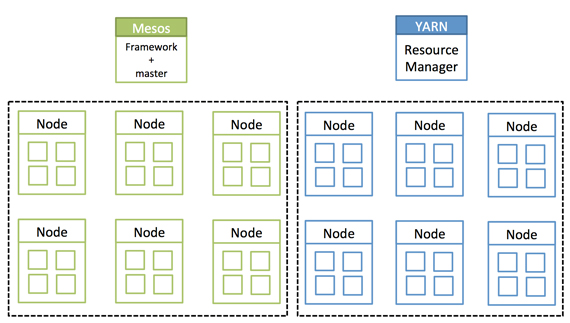
Isolated clusters. Source: Mesosphere and MapR, used with permission.
Hadoop was meant to tear down walls — albeit, data silo walls — but walls, nonetheless. What has happened is that while tearing some walls down, other types of walls have gone up in their place.
Another technology, Apache Mesos, is also meant to tear down walls — but Mesos has often been positioned to manage the “second cluster,” which are all of those other, non-Hadoop workloads.
This is where the story really starts, with these two silos of Mesos and YARN. They are often pitted against each other, as if they were incompatible. It turns out they work together, and therein lies my tale. Read more…

A million rows isn’t cool. You know what’s cool? A billion rows.
Changing your frame of reference when starting with SQL on Hadoop.
Editor’s note: John Russell will be one of the teachers of the tutorial Getting Started with Interactive SQL-On-Hadoop at Strata + Hadoop World in San Jose. Visit the Strata + Hadoop World website for more information on the program.
If you’re just getting started doing analytic work with SQL on Hadoop, a table with a million rows might seem like a good starting point for experimentation. Isn’t that a lot of data? While you can exercise the features of a traditional database with a million rows, for Hadoop it’s not nearly enough. Think billions of rows instead.
Let’s look at the ways a million-row table falls short. Understanding the data volumes involved with big data can help you avoid going down unproductive pathways based on misleading assumptions.
With a million-row table, every byte in each row represents a megabyte of total data volume. Let’s say your table represents people and has fields for name, address, occupation, salary, height, weight, number of children, and favorite food. Here’s what a sample field might look like, with a scale underneath to illustrate length:

This particular record takes up 78 characters, including the comma separators. A back-of-the-envelope calculation suggests that, if this is an average row, we’ll end up with about 78 megabytes of data in the table. (And don’t recycle that envelope just yet — doing analytics with Hadoop, you’ll do a lot of rough estimates like this to sanity-check your expectations about performance and scalability.) Read more…