
Here are a few of the data stories that caught my attention this week:
A possible downside to Wikidata
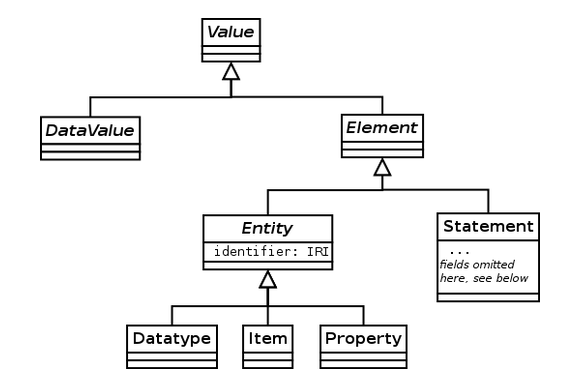
Screenshot from the Wikidata Data Model page.
The Wikimedia Foundation — the good folks behind Wikipedia — recently proposed a Wikidata initiative. It’s a new project that would build out a free secondary database to collect structured data that could provide support in turn for Wikipedia and other Wikimedia projects. According to the proposal:
“Many Wikipedia articles contain facts and connections to other articles that are not easily understood by a computer, like the population of a country or the place of birth of an actor. In Wikidata, you will be able to enter that information in a way that makes it processable by the computer. This means that the machine can provide it in different languages, use it to create overviews of such data, like lists or charts, or answer questions that can hardly be answered automatically today.”
But in The Atlantic this week, Mark Graham, a research fellow at the Oxford Research Institute, takes a look at the proposal, calling these “changes that have worrying connotations for the diversity of knowledge in the world’s sixth most popular website.” Graham points to the different language editions of Wikipedia, noting that the encyclopedic knowledge contained therein is always highly diverse. “Not only does each language edition include different sets of topics, but when several editions do cover the same topic, they often put their own, unique spin on the topic. In particular, the ability of each language edition to exist independently has allowed each language community to contextualize knowledge for its audience.”
Graham fears that emphasizing a standardized, machine-readable, semantic-oriented Wikipedia will lose this local flavor:
“The reason that Wikidata marks such a significant moment in Wikipedia’s history is the fact that it eliminates some of the scope for culturally contingent representations of places, processes, people, and events. However, even more concerning is that fact that this sort of congealed and structured knowledge is unlikely to reflect the opinions and beliefs of traditionally marginalized groups.”
His arguments raise questions about the perceived universality of data, when in fact what we might find instead is terribly nuanced and localized, particularly when that data is contributed by humans who are distributed globally.
The intricacies of Netflix personalization
 Netflix’s recommendation engine is often cited as a premier example of how user data can be mined and analyzed to build a better service. This week, Netflix’s Xavier Amatriain and Justin Basilico penned a blog post offering insights into the challenges that the company — and thanks to the Netflix Prize, the data mining and machine learning communities — have faced in improving the accuracy of movie recommendation engines.
Netflix’s recommendation engine is often cited as a premier example of how user data can be mined and analyzed to build a better service. This week, Netflix’s Xavier Amatriain and Justin Basilico penned a blog post offering insights into the challenges that the company — and thanks to the Netflix Prize, the data mining and machine learning communities — have faced in improving the accuracy of movie recommendation engines.
The Netflix post raises some interesting questions about how the means of content delivery have changed recommendations. In other words, when Netflix refocused on its streaming product, viewing interests changed (and not just because the selection changed). The same holds true for the multitude of ways in which we can now watch movies via Netflix (there are hundreds of different device options for accessing and viewing content from the service).
Amatriain and Basilico write:
“Now it is clear that the Netflix Prize objective, accurate prediction of a movie’s rating, is just one of the many components of an effective recommendation system that optimizes our members’ enjoyment. We also need to take into account factors such as context, title popularity, interest, evidence, novelty, diversity, and freshness. Supporting all the different contexts in which we want to make recommendations requires a range of algorithms that are tuned to the needs of those contexts.”
 Fluent Conference: JavaScript & Beyond — Explore the changing worlds of JavaScript & HTML5 at the O’Reilly Fluent Conference (May 29 – 31 in San Francisco, Calif.).
Fluent Conference: JavaScript & Beyond — Explore the changing worlds of JavaScript & HTML5 at the O’Reilly Fluent Conference (May 29 – 31 in San Francisco, Calif.).
Got data news?
Feel free to email me.
Related: