
![]() The Library of Congress is now more responsive — at least when it comes to web design. Today, the nation’s repository for its laws launched a new beta website at Congress.gov and announced that it would eventually replace Thomas.gov, the 17-year-old website that represented one of the first significant forays online for Congress. The new website will educate the public looking for information on their mobile devices about the lawmaking process, but it falls short of the full promise of embracing the power of the Internet. (More on that later).
The Library of Congress is now more responsive — at least when it comes to web design. Today, the nation’s repository for its laws launched a new beta website at Congress.gov and announced that it would eventually replace Thomas.gov, the 17-year-old website that represented one of the first significant forays online for Congress. The new website will educate the public looking for information on their mobile devices about the lawmaking process, but it falls short of the full promise of embracing the power of the Internet. (More on that later).
Tapping into a growing trend in government new media, the new Congress.gov features responsive design, adapting to desktop, tablet or smartphone screens. It’s also search-centric, with Boolean search and, in an acknowledgement that most of its visitors show up looking for information, puts a search field front and center in the interface. The site includes member profiles for U.S. Senators and Representatives, with associated legislative work. In a nod to a mainstay of social media and media websites, the new Congress.gov also has a “most viewed bills” list that lets visitors see at a glance what laws or proposals are gathering interest online. (You can download a fact sheet on all the changes as a PDF).
On the one hand, the new Congress.gov is a dramatic update to a site that desperately needed one, particularly in a historic moment where citizens are increasingly connecting to the Internet (and one another) through their mobile devices.
On the other hand, the new Congress.gov beta has yet to realize the potential of Congress publishing bulk open legislative data. There is no application programming interface (API) for open government developers to build upon. In many ways, the new Congress.gov replicates what was already available to the public at sites like Govtrack.us and OpenCongress.org.
In response to my tweets about the site, former law librarian Meg Lulofs Kuhagan (@librarylulu) noted on Twitter that there’s “no data whatsoever, just window dressing” in the new site — but that “it looks good on my phone. More #opengov if you have a smartphone.”
Aaron E. Myers, the director of new media for Senator Major Leader Harry Reid, commented on Twitter that legislative data is a “tough nut to crack,” with the text of amendments, SCOTUS votes and treaties missing from new Congress.gov. In reply, Chris Carlson, the creative director for the Library of Congress, tweeted that that information is coming soon and that all the data that is currently in Thomas.gov will be available on Congress.gov.
Emi Kolawole, who reviewed the new Congress.gov for the Washington Post, reported that more information, including the categories Meyers cited, will be coming to the site soon, during its beta, including the Congressional Record and Index. Here’s hoping that Congress decides to publish all of its valuable Congressional Research Reports, too. Currently, the public has to turn to OpenCRS.com to access that research.
Carlson was justifiably proud of the beta of Congress.gov: “The new site has clean URLs, powerful search, member pages, clean design,” he tweeted. “This will provide access to so many more people who only have a phone for internet.”
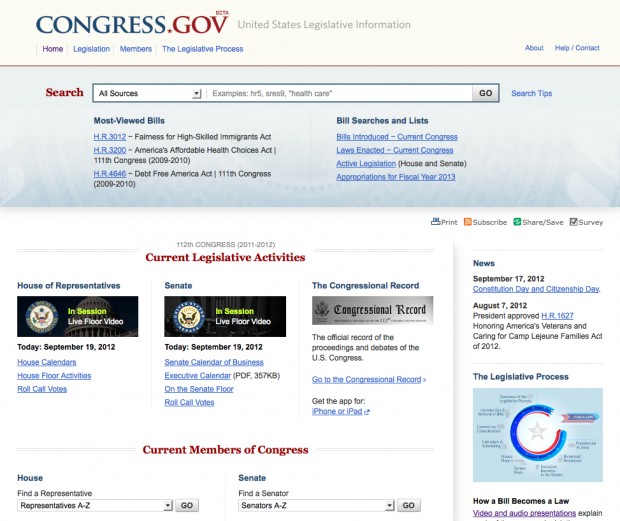
While the new Congress.gov is well designed and has the potential to lead to more informed citizens, the choice to build a new website versus release the data disappointed some open government advocates.
“Another hilarious/clueless misallocation of resources,” commented David Moore, co-founder of OpenCongress. “First liberate bulk open gov data; then open API; then website.”
“What’s noticeable about this evolving beta website, besides the major improvements in how people can search and understand legislative developments, is what’s still missing: public comment on the design process and computer-friendly bulk access to the underlying data,” wrote Daniel Schuman, legislative counsel for the Sunlight Foundation. “We hope that Congress will now deeply engage with the public on the design and specifications process and make sure that legislative information is available in ways that most encourage analysis and reuse.”
Kolawole asked Congressional officials about bulk data access and an API and heard that the capacity is there but the approval is not. “They said the system could handle it, but they haven’t received congressional auth. to do it yet,” she tweeted.
Vision and bipartisan support for open government on this issue does exist among Congressional leadership. There has been progress on this front in the 112th Congress: the U.S. House started publishing machine-readable legislative data at docs.house.gov this past January.
“Making legislative data easily available in machine-readable formats is a big victory for open government, and another example of the new majority keeping its pledge to make Congress more open and accountable,” said Speaker of the House John Boehner.
Last December, House Minority Whip Steny Hoyer commented upon on how technology is affecting Congress, his caucus and open government in the executive branch:
For Congress, there is still a lot of work to be done, and we have a duty to make the legislative process as open and accessible as possible. One thing we could do is make THOMAS.gov — where people go to research legislation from current and previous Congresses — easier to use, and accessible by social media. Imagine if a bill in Congress could tweet its own status.
The data available on THOMAS.gov should be expanded and made easily accessible by third-party systems. Once this happens, developers, like many of you here today, could use legislative data in innovative ways. This will usher in new public-private partnerships that will empower new entrepreneurs who will, in turn, yield benefits to the public sector.
For any of that vision of civic engagement and entrepreneurship to can happen around Web, the Library of Congress will need to fully open up the data. Why hasn’t it happened yet, given bipartisan support and a letter from the Speaker of the House?
techPresident managing editor Nick Judd asked the Library of Congress about Congress.gov. The director of the communications for the Library of Congress, Gayle Osterberg, suggested in an email in response that Congress hasn’t been clear about the manner for data release.
“Congress has said what to do on bulk access,” commented Schuman. “See the joint explanatory statement. “There is support for bulk access.”
In June 2012, the House’s leadership has issued a bipartisan statement that adopted the goal of “provid[ing] bulk access to legislative information to the American people without further delay,” putting releasing bulk data among its “top priorities in the 112th Congress” and directed a task force “to begin its important work immediately.”
The 112th Congress will come to a close soon. The Republicans swept into the House in 2010 promising a new era of innovation and transparency. If Speaker Boehner, Rep. Hoyer and their colleagues want to end these two divisive years on a high note, fully opening legislative data to the People would be an enduring legacy. Congressional leaders will need to work with the Library of Congress to make that happen.
All that being said, the new Congress.gov is in beta and looks dramatically improved. The digital infrastructure of the federal legislative system got a bit better today, moving towards a more adaptive government. Stay tuned, and give the Library of Congress (@LibraryCongress) some feedback: there’s a new button for it on every page.
This post has been updated with comments from Facebook, a link and reporting from techPresident, and a clarification from Daniel Schuman regarding the position of the House of Representatives.