
If you had 10 million pounds to spend on open data research, development and startups, what would you do with it? That’s precisely the opportunity that Gavin Starks (@AgentGav) has been given as the first CEO of the Open Data Institute (ODI) in the United Kingdom.
 The ODI, which officially opened last September, was founded by Sir Tim Berners-Lee and Professor Nigel Shadbolt. The independent, non-partisan, “limited by guarantee” nonprofit is a hybrid institution focused on unlocking the value in open data by incubating startups, advising governments, and educating students and media.
The ODI, which officially opened last September, was founded by Sir Tim Berners-Lee and Professor Nigel Shadbolt. The independent, non-partisan, “limited by guarantee” nonprofit is a hybrid institution focused on unlocking the value in open data by incubating startups, advising governments, and educating students and media.
Previously, Starks was the founder and chairman of AMEE, a social enterprise that scored environmental costs and risks for businesses. (O’Reilly’s AlphaTech Ventures was one of its funders.) He’s also worked in the arts, science and technology. I spoke to Starks about the work of the ODI and open data earlier this winter as part of our continuing series investigating the open data economy.
What have you accomplished to date?
Gavin Starks: We opened our offices on the first of October last year. Over the first 12 weeks of operation, we’ve had a phenomenal run. The ODI is looking to create value to help everyone address some of the greatest challenges of our time, whether that’s in education, health, in our economy or to benefit our environment.
Since October, we’ve had literally hundreds of people through the door. We’ve secured $750,000 in matched funding from the Omidyar Network, on top of a 10-million-pound investment from the UK Government’s Technology Strategy Board. We’ve helped identify 200 million pounds a year in savings for the health service in the UK.
200 million pounds? What do you base that estimate upon?
Gavin Starks: Part of our remit is to bring together the main experts from different areas. To illustrate the kind of benefit that I think we can bring here, one part of what we’re doing is to try and unlock data supply.
The Health Service in the UK started to release a lot of its prescription information as open data about nine months ago. We worked with some of the main experts in the health service with a big data analytics firm, Mastodon C, which is a startup that we’re incubating at the ODI.
Together, they identified potential areas of investigation. The data science folks drilled into every single prescription. (I think the dataset was something like 47 million rows of data.) What they were looking at there was the difference between proprietary drugs and generics, where there may be a generic equivalent. In many cases, the generic equivalent has no clinical difference between the proprietary drugs — and so the cost difference is huge. It might be 81 pence or 81 pennies for a generic to more than 20 pounds for a drug that’s still under license.
Looking at the entire dataset, the analytics revealed different patterns, and from that, cost differences. If we carried out this research over a year ago, for example, we could have saved 200 million pounds over the last year. It really is quite significant. That’s on one class of drugs, on one area. We think this research could be repeated against different classes of drugs and replicated internationally.
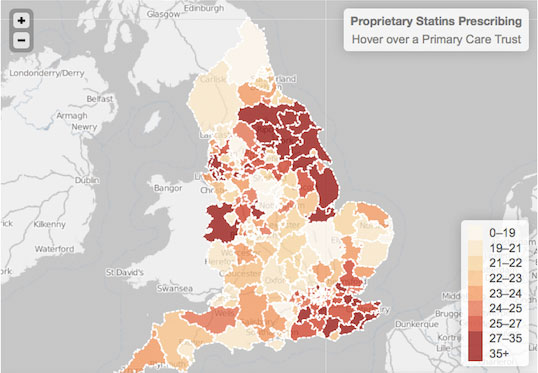
Percentage of proprietary statin prescribing by CCG Sept 2011 – May 2012.
Image Credit: PrescribingAnalytics.com
Which open data business models are the most exciting to you?
Gavin Starks: I think there’s lots of different areas to explore here. There are areas where there can be cost savings brought to any organization, whether it’s public sector or private sector organizations. There’s also areas of new innovation. (I think that they’re quite different directions.) Some of the work that we’ve done with the prescription data, that’s where you’re looking at efficiencies.
We’ve got other startups that are based in our offices here in Shoreditch and London that are looking at transportation information. They’re looking at location-based services and other forms of analytics within the commercial sectors: financial information, credit ratings, those kinds of areas. When you start to pull together different levels of open data that have been available but haven’t been that accessible in the past, there’s new services that can be derived from them.
What creates a paid or value-add service? It’s essential that we create a starting point where free and open access to the data itself can be made available for certain use cases for as many people as possible. There, you stimulate innovation if you can gain access to discern new insight from that data.
Having the data aggregated, structured and accessible in an automated way is worth paying for. There could be a service-level-agreement-based model. There could be a carve-out of use cases. You could borrow from the Creative Commons world and say, “If you’re going to have a share alike license on this, then that’s fine, you can use it for free. But if you’re going to start creating closed assets, as a result, there may be a charge for the use of data at that point.”
I think there’s a whole range of different data models, but really, the goal here is to try and discern what insight can be derived from existing datasets and what happens when you start mashing them up with other datasets.
What are the greatest challenges to achieving some of the economic outcomes that the UK Cabinet Office has described?
Gavin Starks: I think there are many challenges. One of the key ones is just understanding. One challenge we’ve heard consistently from pretty much everybody has been, “We believe there’s a huge amount of potential here, but where do we start?”
Part of the ODI’s mission is to provide training, education and assets that enable people to begin on that journey. We’re in the process right now of designing our first dozen or so training programs. We’re working at one level with the World Bank to train the world’s politicians and national leaders, and we’re working at the other end with schools to create programs that fit with existing graduate courses.
Education is one of the biggest challenges. We want to train more than technologists — we also want to train lawyers and journalists about the business case to enable people to understand and move forward at the same pace. There’s very little point in just saying, “There is huge value here,” without trying to demonstrate that return on investment (ROI) and value case at the same time.
What is the ODI’s approach to incubating civic startups?
Gavin Starks: There are two parts to it. One is unlocking supply. We’re working with different government departments and public sector agencies to help them understand what unlocking supply means. Creating structured, addressable, repeatable data creates the supply piece so that you can actually start to build a business. It’s very high-risk to try and build a business when you don’t have a guarantee of supply.
Two, encouraging and incubating the demand side. We’ve got six startups in our space already. They’re all at different stages. Some of them are very early on, just trying to navigate toward the value here that we can discern from the data. Others are more mature, and maybe have some existing revenue streams, but they’re looking at how to really make this scale.
What we’ve found is of benefit so far — and again, we’re only three months in — is our ability to network and convene the different stakeholders. We can take a small startup and get them in front of one of the large corporations and help them bridge that sales process. Helping them communicate their ideas in a clear way, where the value is obvious to the end customer, is important.
What are some of the approaches that have worked to unlock value from open government data?
Gavin Starks: We’re not believers in “If you build it, they will come.” You need to create a guaranteed data supply, but you also need to really engage with people to start to unlock ideas.
We’ve been running our own hackathons, but I think there’s a difference in the way that we’ve structured them and organized them. We include domain experts and frame the hack events around a specific problem or a specific set of problems. For example, we had a weekend-long hackathon in the health space, looking at different datasets, convening domain experts and technical experts.
It involved competitions, when the winner gets a seat at the ODI to take their idea forward. It might be that an idea turns into a business, it might turn into a project, or it might just turn into a research program.
I think that you need to really lead people by the hand through the process of innovation, helping them and supporting them to unlock the value, rather than just having the datasets there and expecting them to be used.
Given the cost the UK’s National Audit Office ascribed to opening data, is the investment worth it?
Gavin Starks: This is like the early days of the web. There are lots of estimates about how much everything is going to be worth and what sort of ROI people are going to see. What we’ve yet to see, I think, is the honest answer.
The reason I’m very excited about this area is that I see the same potential as I saw in the mid-1990s, when I got involved with the web. The same patterns exist today. There are new datasets and ecosystems coming into existence that can be data-mined. They can be joined together in novel ways. They can bridge the virtual and physical worlds. They can bring together people who have not been able to collaborate in different ways.
There’s a huge amount of value to be unlocked. There will be some dead ends, as we had in the web’s development, but there will be some incredible wins. We’re trying to refine our own skills around identifying where those potential hot spots might be.
Health services is an area where it’s really obvious there’s a lot of benefits. There are clear benefits from opening up transportation and location-based services. You can see the potential behind energy efficiency, creating efficient supply chains and opening up more information around education.
You can see resonant points. We’re really drilling into those and asking, “What happens when you really put together the right domain experts and the supportive backers?”
Those backers can be financial as well as in industry. The Open Data Institute has been pulling together those experts and providing a neutral space for that innovation to happen.
Which of those areas have the most clear economic value, in terms of creating shorter term returns on investment and quick wins?
Gavin Starks: I don’t think there’s a single answer to that question. If you look at location-based services, corporate data, health data or education, there are examples and use cases in different parts of the world where they will have different weightings.
If you were looking at water sanitation in areas of the world where there is an absence of it, then they may provide more immediate return than unlocking huge amounts of transportation information.
In Denmark, look at the release of the equivalent of zip code data and the more detailed addresses. I believe the numbers there went from four-fold return to 17-fold return, in terms of value to the country of their investment in decent address-level data.
This is one area that we’ve provided a consultation response in the UK. I think it may vary from state-to-state in the U.S., or maybe in areas where the specific focus on health would be very beneficial. There may be areas where a focus on energy efficiency may be most beneficial.
What conditions lead to beneficial outcomes for open data?
Gavin Starks: A lot of the real issues are not really about the technology. When it comes to the technology, we know what a lot of the solutions are. How can we address or improve the data quality? What standards need to exist? What anonymity, privacy or secrecy needs to exist around the data? How do we really measure the outcomes? What are the circumstances where stakeholders need to get involved?
You definitely need political buy-in, but there also needs to be a sense of what the data landscape is. What’s the inventory? What’s the legal situation? Who has access? What kind of access is required? What does success look like against a particular use case?
You could be looking at health in somewhere like Rwanda, you could be looking at a national statistics office in a particular country where they may not have access to the data themselves, and they don’t have very much access to resources. You could be looking at contracting, government procurement and improving simple accountability, where there may be more information flow than there is around energy data, for example.
I think there’s a range of different use cases that we need to really explore here. We’re looking for great use cases where we can say, “This is something that’s simple to achieve, that’s repeatable, that helps lower costs and stimulate innovation.”
We are really at the beginning of a journey here.
Red Hat made headlines for becoming the first billion-dollar open source company. What do you think the first billion-dollar open data company will be?
Gavin Starks: It would be not unlikely for that to be in the health arena.
This interview has been edited and condensed for clarity. This post is part of our ongoing investigation into the open data economy.
Related: