
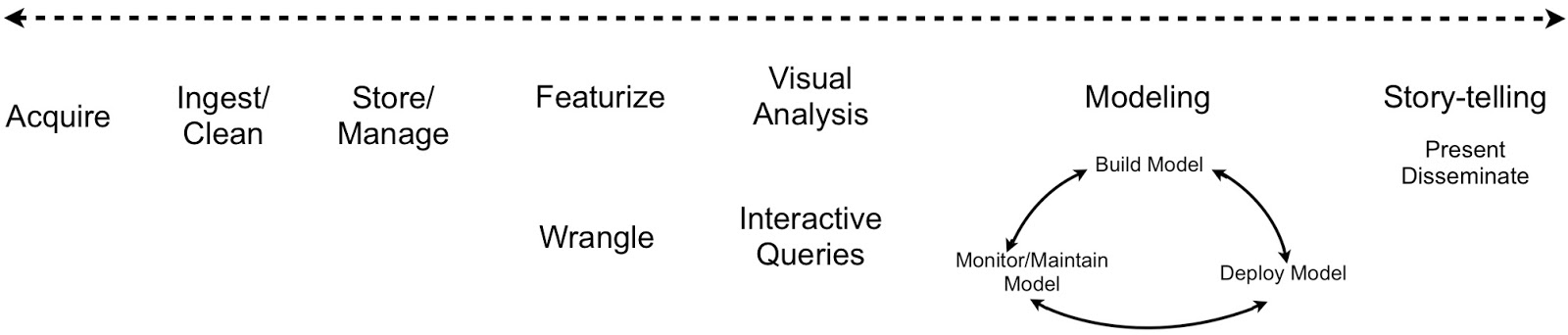
Judging from articles in the popular press the term data scientist has increasingly come to refer to someone who specializes in data analysis (statistics, machine-learning, etc.). This is unfortunate since the term originally described someone who could cut across disciplines. Far from being confined to data analysis, a typical data science workflow1 means jumping back-and-forth between a series of interdependent tasks. Data scientists tend to use a variety of tools, often across different programming languages. Workflows that involve many different tools require a lot of context-switching which affects productivity and impedes reproducability:
Tools and Training
People who build tools appreciate the value of having their solutions span across the data science workflow. If a tool only addresses a limited section of the workflow, it runs the risk of being replaced by others that have more coverage. Platfora is as proud of its data store (the fractal cache) and data wrangling2 tools, as of its interactive visualization capabilities. The Berkeley Data Analytics Stack (BDAS) and the Hadoop community are expanding to include analytic engines that increase their coverage – over the next few months BDAS components for machine-learning (MLbase) and graph analytics (GraphX) are slated for their initial release. In an earlier post, I highlighted a number of tools that simplify the application of advanced analytics and the interpretation of results. Analytic tools are getting to the point that in the near future I expect many (routine) data analysis tasks will be performed by business analysts and other non-experts.
The people who train future data scientists also seem aware of the need to teach more than just data analysis skills. A quick glance at the syllabi and curricula of a few3 data science courses and programs reveals that – at least in some training programs – students get to learn other components of the data science workflow. One course that caught my eye: CS 109 at Harvard seems like a nice introduction to the many facets of practical data science – plus it uses IPython notebooks, Pandas, and scikit-learn!
The Analytic Lifecycle and Data Engineers
As I noted in a recent post, model building is only one aspect of the analytic lifecycle. Organizations are starting to pay more attention to the equally important tasks of model deployment, monitoring, and maintenance. One telling example comes from a recent paper on sponsored search advertising at Google: a simple model was chosen (logistic regression) and most of the effort (and paper) was devoted to devising ways to efficiently train, deploy, and maintain it in production.
In order to deploy their models into production, data scientists learn to work closely with folks who are responsible for building scalable data infrastructures – data engineers. If you talk with enough startups in Silicon Valley, you quickly realize that data engineers are in even higher4 demand than data scientists. Fortunately some forward thinking consulting services are stepping forward to help companies address both their data science and data engineering needs.
Related posts:
- What is Data Science
- Tightly integrated engines streamline Big Data analysis
- Data scientists tackle the analytic lifecycle
- Data analysis tools target non-experts
(1) For a humorous view, see Data Science skills as a subway map!
(2) Here’s a funny take on the rule-of-thumb that data wrangling accounts for 80% of time spent on data projects: “In Data Science, 80% of time spent prepare data, 20% of time spent complain about need for prepare data.”
(3) Here is a short list: UW Intro to Data Science and Certificate in Data Science, CS 109 at Harvard, Berkeley’s Master of Information and Data Science program, Columbia’s Certification of Professional Achievement in Data Sciences, MS in Data Science at NYU, and the Certificate of Advanced Study In Data Science at Syracuse.
(4) I’m not sure why the popular press hasn’t picked up on this distinction. Maybe it’s a testament to the the buzz surrounding data science.
 O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.Strata Rx Health Data Conference: September 25-27 | Boston, MA
O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.Strata Rx Health Data Conference: September 25-27 | Boston, MAStrata + Hadoop World: October 28-30 | New York, NY
Strata in London: November 15-17 | London, England