"analytic lifecycle" entries

A good nudge trumps a good prediction
Identifying the right evaluation methods is essential to successful machine learning.
Editor’s note: this is part of our investigation into analytic models and best practices for their selection, deployment, and evaluation.
We all know that a working predictive model is a powerful business weapon. By translating data into insights and subsequent actions, businesses can offer better customer experience, retain more customers, and increase revenue. This is why companies are now allocating more resources to develop, or purchase, machine learning solutions.
While expectations on predictive analytics are sky high, the implementation of machine learning in businesses is not necessarily a smooth path. Interestingly, the problem often is not the quality of data or algorithms. I have worked with a number of companies that collected a lot of data; ensured the quality of the data; used research-proven algorithms implemented by well-educated data scientists; and yet, they failed to see beneficial outcomes. What went wrong? Doesn’t good data plus a good algorithm equal beneficial insights? Read more…

Instrumenting collaboration tools used in data projects
Built-in audit trails can be useful for reproducing and debugging complex data analysis projects
As I noted in a previous post, model building is just one component of the analytic lifecycle. Many analytic projects result in models that get deployed in production environments. Moreover, companies are beginning to treat analytics as mission-critical software and have real-time dashboards to track model performance.
Once a model is deemed to be underperforming or misbehaving, diagnostic tools are needed to help determine appropriate fixes. It could well be models need to be revisited and updated, but there are instances when underlying data sources1 and data pipelines are what need to be fixed. Beyond the formal systems put in place specifically for monitoring analytic products, tools for reproducing data science workflows could come in handy.
Gaining access to the best machine-learning methods
Accuracy, simplicity, speed, and interpretability are some of the factors that need to be considered
For companies in the early stages of grappling with big data, the analytic lifecycle (model building, deployment, maintenance) can be daunting. In earlier posts I highlighted some new tools that simplify aspects of the analytic lifecycle, including the early phases of model building. But while tools are allowing companies to offload routine analytic tasks to business analysts, experienced modelers are still needed to fine-tune and optimize, mission-critical algorithms.
Model Selection: Accuracy and other considerations
Accuracy1 is the main objective and a lot of effort goes towards raising it. But in practice tradeoffs have to be made, and other considerations play a role in model selection. Speed (to train/score) is important if the model is to be used in production. Interpretability is critical if a model has to be explained for transparency2 reasons (“black-boxes” are always an option, but are opaque by definition). Simplicity is important for practical reasons: if a model has “too many knobs to tune” and optimizations have to be done manually, it might be too involved to build and maintain it in production3.
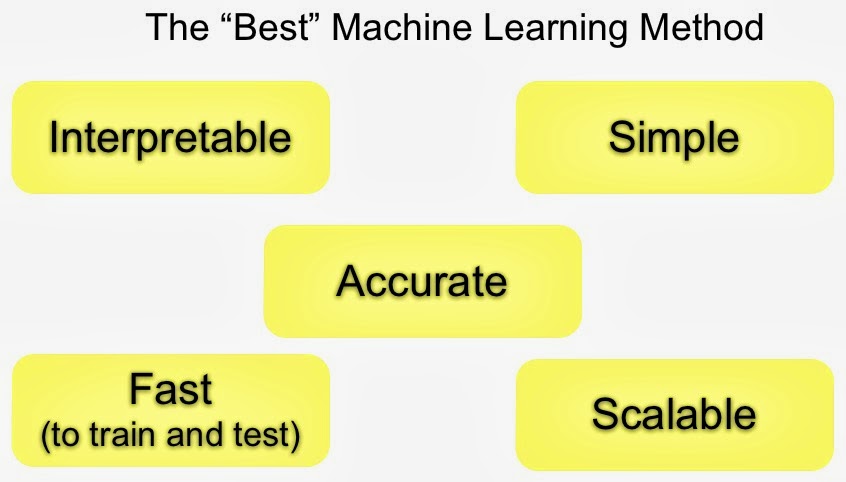
Chances are a model that’s fast, easy to explain (interpretable), and easy to tune (simple), is less4 accurate. Experienced model builders are valuable precisely because they’ve weighed these tradeoffs across many domains and settings. Unfortunately not many companies have the experts that can identify, build, deploy, and maintain models at scale. (An example from Google illustrates the kinds of issues that can come up.)
Data Analysis: Just one component of the Data Science workflow
Specialized tools run the risk of being replaced by others that have more coverage
Judging from articles in the popular press the term data scientist has increasingly come to refer to someone who specializes in data analysis (statistics, machine-learning, etc.). This is unfortunate since the term originally described someone who could cut across disciplines. Far from being confined to data analysis, a typical data science workflow1 means jumping back-and-forth between a series of interdependent tasks. Data scientists tend to use a variety of tools, often across different programming languages. Workflows that involve many different tools require a lot of context-switching which affects productivity and impedes reproducability:
Tools and Training
People who build tools appreciate the value of having their solutions span across the data science workflow. If a tool only addresses a limited section of the workflow, it runs the risk of being replaced by others that have more coverage. Platfora is as proud of its data store (the fractal cache) and data wrangling2 tools, as of its interactive visualization capabilities. The Berkeley Data Analytics Stack (BDAS) and the Hadoop community are expanding to include analytic engines that increase their coverage – over the next few months BDAS components for machine-learning (MLbase) and graph analytics (GraphX) are slated for their initial release. In an earlier post, I highlighted a number of tools that simplify the application of advanced analytics and the interpretation of results. Analytic tools are getting to the point that in the near future I expect many (routine) data analysis tasks will be performed by business analysts and other non-experts.
Running batch and long-running, highly available service jobs on the same cluster
Moving different workloads and frameworks onto the same collection of machines increases efficiency and ROI
As organizations increasingly rely on large computing clusters, tools for leveraging and efficiently managing compute resources become critical. Specifically, tools that allow multiple services and frameworks run on the same cluster can significantly increase utilization and efficiency. Schedulers1 take into account policies and workloads to match jobs with appropriate resources (e.g., memory, storage, processing power) in a large compute cluster. With the help of schedulers, end users begin thinking of a large cluster as a single resource (like “a laptop”) that can be used to run different frameworks (e.g., Spark, Storm, Ruby on Rails, etc.).
Multi-tenancy and efficient utilization translates into improved ROI. Google’s scheduler, Borg, has been in production for many years and has led to substantial savings2. The company’s clusters handle a variety of workloads that can be roughly grouped into batch (compute something, then finish) and services (web or infrastructure services like BigTable). Researchers recently examined traces from several Google clusters and observed that while “batch jobs” accounted for 80% of all jobs, “long service jobs” utilize 55-60% of resources.
There are other benefits of multi-tenancy. Being able to run analytics (batch, streaming) and long running services (e.g., web applications) on the same cluster significantly lowers latency3, opening up the possibility for real-time, analytic applications. Bake-offs can be done more effectively as competing tools, versions, and frameworks can be deployed on the same cluster. Data scientists and production engineers leverage the same compute resources, making it easier for teams to work together across the analytic lifecycle. An additional benefit is that data science teams learn to build products and services that factor in efficient utilization and availability.
Mesos, Chronos, and Marathon
Apache Mesos is a popular open source scheduler that originated from UC Berkeley’s AMPlab. Mesos is based on features in modern kernels for resource isolation (cgroups in Linux). It has been in production for a few years at Twitter4, airbnb5, and many other companies – AMPlab simulations showed Mesos comfortably handling clusters with 30K servers.
Data scientists tackle the analytic lifecycle
A new crop of data science tools for deploying, monitoring, and maintaining models
What happens after data scientists build analytic models? Model deployment, monitoring, and maintenance are topics that haven’t received as much attention in the past, but I’ve been hearing more about these subjects from data scientists and software developers. I remember the days when it took weeks before models I built got deployed in production. Long delays haven’t entirely disappeared, but I’m encouraged by the discussion and tools that are starting to emerge.
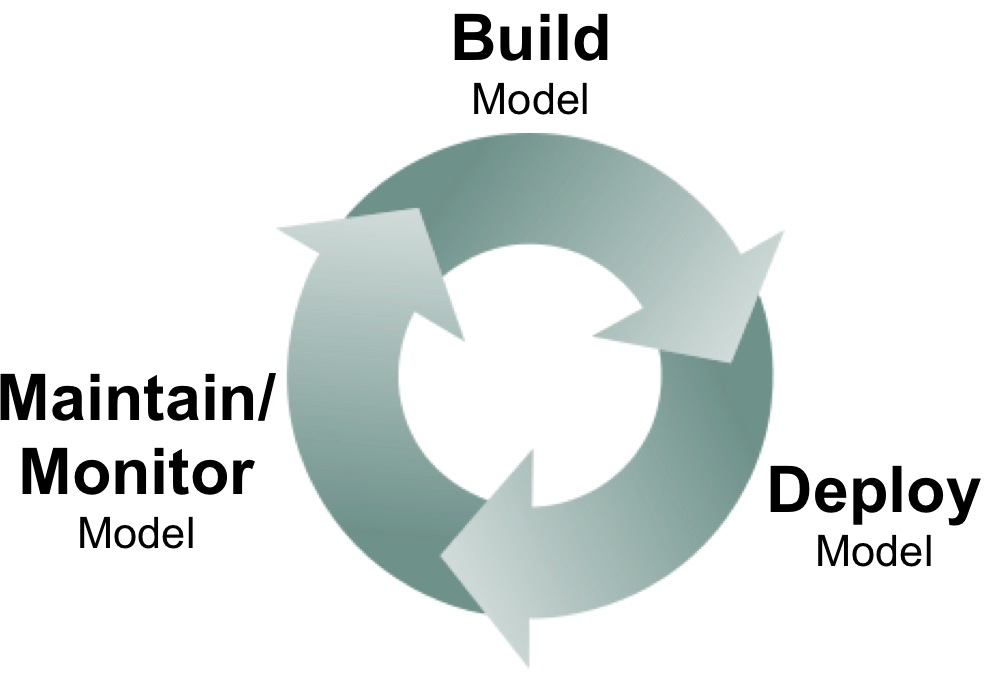
The problem can often be traced to the interaction between data scientists and production engineering teams: if there’s a wall separating these teams, then delays are inevitable. In contrast having data scientists work more closely with production teams makes rapid iteration possible. Companies like Linkedin, Google, and Twitter work to make sure data scientists know how to interface with their production environment. In many forward thinking companies, data scientists and production teams work closely on analytic projects. Even a high-level understanding of production environments help data scientists develop models that are feasible to deploy and maintain.
Model Deployment
Models generally have to be recoded before deployment (e.g., data scientists may favor Python, but production environments may require Java). PMML, an XML standard for representing analytic models, has made things easier. Companies who have access to in-database analytics1, may opt to use their database engines to encode and deploy models.