
This past week I had the good fortune of attending two great talks1 on Deep Learning, given by Googlers Ilya Sutskever and Jeff Dean. Much of the excitement surrounding Deep Learning stems from impressive results in a variety of perception tasks, including speech recognition (Google voice search) and visual object recognition (G+ image search).
Data scientists seek to generate information and patterns from raw data. In practice this usually means learning a complicated function for handling a specified task (classify, cluster, predict, etc.). One approach to machine learning mimics how the brain works: starting with basic building blocks (neurons), it approximates complex functions by finding optimal arrangements of neurons (artificial neural networks).
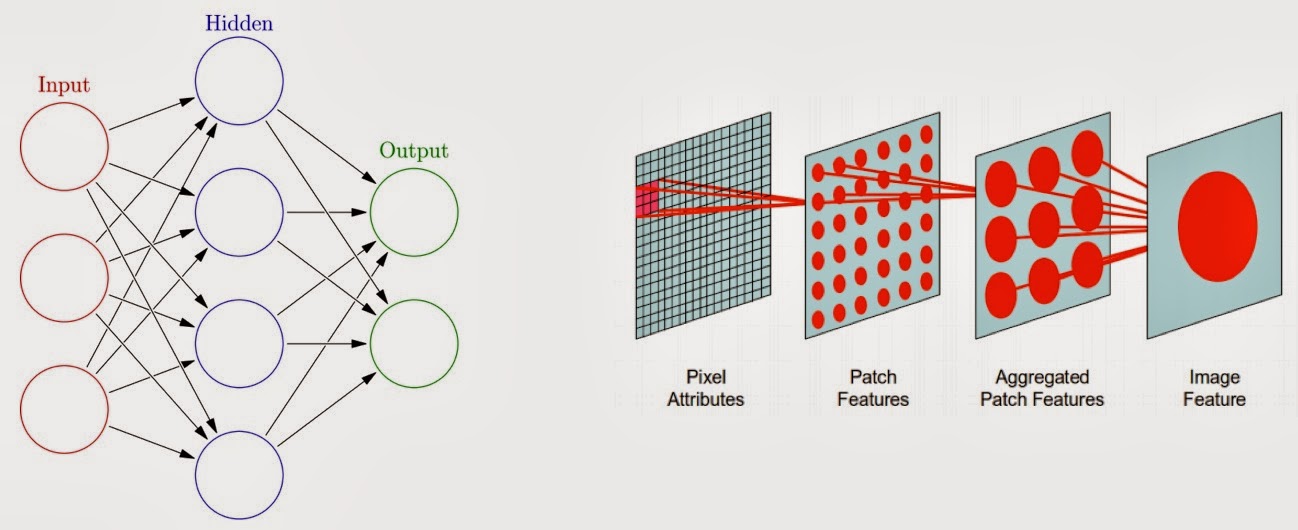
One of the most cited papers in the field showed that any continuous function can be approximated, to arbitrary precision, by a neural network with a single hidden layer. This led some to think that neural networks with single hidden layers would do well on most machine-learning tasks. However this universal approximation property came at a steep cost: the requisite (single hidden layer) neural networks were exponentially inefficient to construct (you needed a neuron for every possible input). For a while neural networks took a backseat to more efficient and scalable techniques like SVM and Random Forest.
What’s changed since the 1980s? More data + faster computational tools
More recently, the advent of big data (availability of much larger labeled/training sets), compute power (FLOPS via GPUs and distributed computing), and some advances in training algorithms (stochastic gradient descent, convolutional NN), have led to strategies2 for training 10-layer neural networks. Why 10-layers (and not 15 or 20 layers)? It turns out 8-10 layers work well in practice, but there isn’t much theoretical justification3 for why that many layers is optimal in many settings. Both Ilya and Jeff admitted that at this point the excitement behind Deep Learning is based on empirical evidence. Encouraged by the success displayed by Deep Learning in a variety of tasks (including speech and visual object recognition), both speakers expressed confidence that large4 10-layer networks could equal humans at (any) perception task5 that takes 0.1 second!
Strong Oral Tradition
Will neural networks work for you? If you have a complex problem (such as recognizing objects in an image), Deep Learning can help but you’ll need to have access to large training data sets (deep networks work best when you have a very specific error rate that you need to minimize). Since lots of FLOPS are required, access to distributed compute resources and systems experts are essential. Some amount of domain expertise can help produce simpler networks.
Deep networks also require some fiddling to optimize (in an earlier post I listed simplicity as one reason for choosing a specific model over another). Ilya Sutskever alluded to a strong “oral tradition”6 in training deep neural networks. Practitioners share hacks and best practices (e.g., setting configuration parameters), that aren’t easy to glean from papers. The best way to pick up these critical bits of knowledge is to apprentice with more experienced users. You can overcome the absence of experienced mentors, but a lot of trial and error is required to acquire useful “rules of thumb”. The good news is that researchers are looking for ways to automate some of the “black art” and “oral traditions” involved in training neural networks. Early results using Bayesian optimization have been promising: automatic methods for selecting configuration parameters reached or surpassed human expert optimization.
Unsupervised learning for machine translation
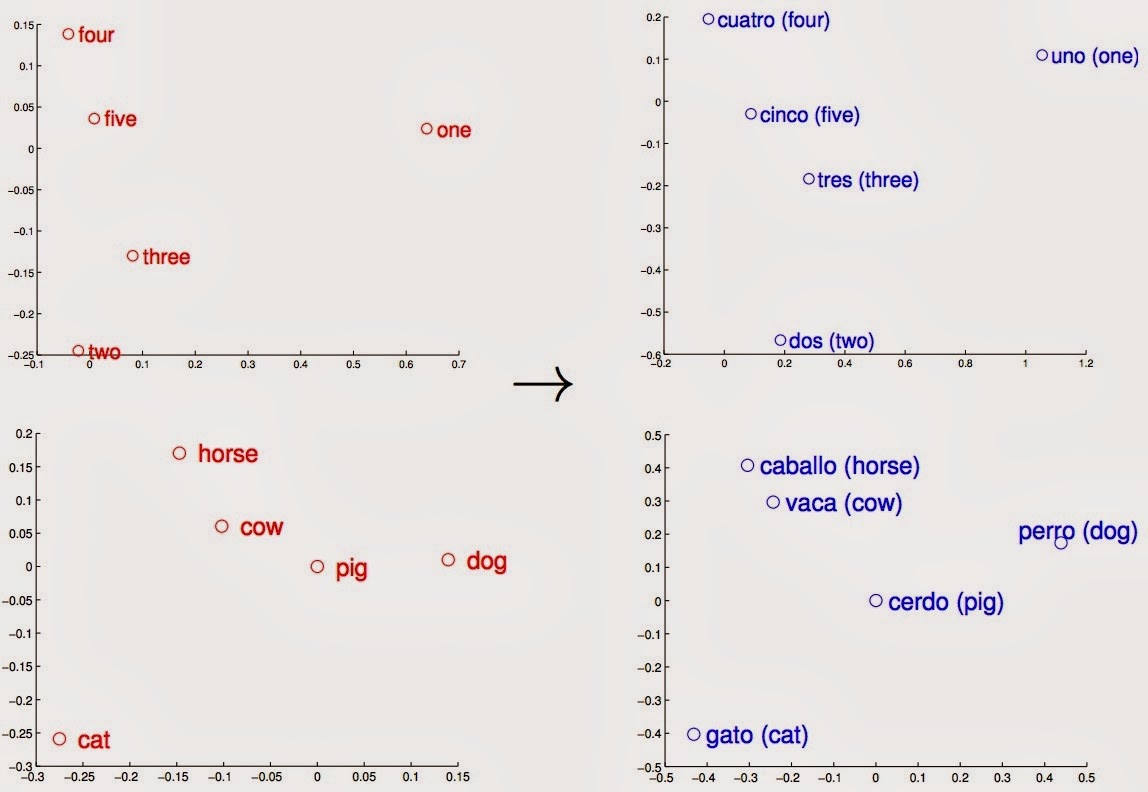
One area where unsupervised learning for neural networks has been successful is in representing words as vectors in a high-dimensional space. To be useful, such geometric representations should have the following property: similar words (similar in the sense that they tend to co-occur) should have similar vectors7. More importantly, these vector representations also turn out to be useful for machine translation. The figure below illustrates how one can “learn” a linear mapping from one language to another: vector representations of words in English and Spanish were projected to two dimensions using PCA, then manually rotated to highlight the similarity of patterns across the two languages.
Related posts:
- Gaining access to the best machine-learning methods
- Data analysis tools target non-experts
- Data Analysis: Just one component of the Data Science workflow
(1) Both talks were free and open to the public. A video of Ilya’s talk is available online (starts around minute 24:00).
(2) Both Ilya Sutskever and Jeff Dean alluded to having “recipes” for learning 10-layer networks.
(3) The rationale for 10-layers is loosely based on neuroscience. In about 0.1 second, a neuron (in a human brain) fires about 10 times – which is roughly the amount of time needed for many common perception tasks (like speech or visual object recognition).
(4) Network size: (Number of training cases) ~ (Number of trainable parameters)
(5) Assuming one has enough training data!
(6) Skip to 1:05:10 of Ilya’s talk.
(7) These vector representations lead to fun factoids like: [Vector(China) + Vector(Currency)] ~ Vector(Yuan)
 O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
Strata + Hadoop World: October 28-30 | New York, NY
Strata in London: November 15-17 | London, England
Strata in Santa Clara: February 11-13 | Santa Clara, CA