
The R programming language is the most popular statistical software in use today by data scientists, according to the 2013 Rexer Analytics Data Miner survey. One of the main drawbacks of vanilla R is the inability to scale and handle extremely large datasets because by default, R programs are executed in a single thread, and the data being used must be stored completely in RAM. These barriers present a problem for data analysis on massive datasets. For example, the R installation and administration manual suggests using data structures no larger than 10-20% of a computer’s available RAM. Moreover, high-level languages such as R or Matlab incur significant memory overhead because they use temporary copies instead of referencing existing objects.
One potential forthcoming solution to this issue could come from Teradata’s upcoming product, Teradata Aster R, which runs on the Teradata Aster Discovery Platform. It aims to facilitate the distribution of data analysis over a cluster of machines and to overcome one-node memory limitations in R applications.
In some business areas, such as telecommunications, social graph analysis offers high business benefit. However, it is difficult to compute this kind of analysis on the full user base using R on a single node due to memory limitations. To overcome this limitation, sampling-based approaches are commonly used, but they are restricted to a subset of users. Moreover, social graph analysis is not easily parallelizable because friendship connections are difficult to isolate following partition-based approaches. At WiseAthena.com, we’ve spent a lot of engineering effort building in-house graph-mining algorithms needed for machine-learning-based churn prediction and fraud-detection systems.
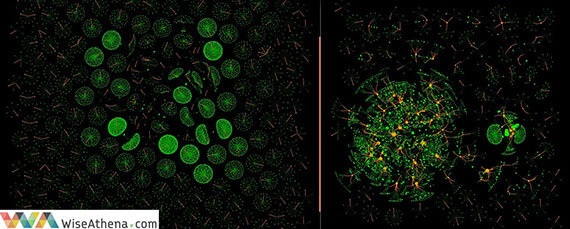
An example of two social graphs. The image on the left shows a legitimate user network among millions of Telco call records; the image on the right shows a fraudster graph in the same network. Photo copyright: WiseAthena.com, used with permission.
One of the benefits of graph analysis in telecommunications is the ability to detect influencers. For example, we recently discovered for one of our clients that for each influencer that becomes a churner, the company will lose 4.4 more customers in the next three months.
In order to compute influencers in a network, first we need to count the number of interactions among each user. Based on documentation provided by Teradata, I will illustrate an example of how to compute the interactions among users in a telecommunication network using call detail records (CDR) of six months. A similar example can be executed on plain vanilla R using the standard functions instead of Aster R ta.*( ) family functions. However, when the size of the input data is greater than the available memory, we will get a typical memory error like, “Error: cannot allocate vector of size 10 GB.”
When Aster R becomes available (targeted for the fourth quarter of 2014), it will make it possible to load and analyze input data, regardless of size. The first step in the process will be to connect to the Aster cluster by using the Teradata Aster package.
R>library(TeradataAsterR)
R>ta.connect(“AsterDSN”, uid = “ABC”, pwd = “123”, database = “CDR”, dType = “odbc”)
Then, we can create virtual data frames that provide access to the outgoing and incoming calls per each user. These data were previously stored into the database CDR within the tables “outgoing_calls” and “incoming_calls”. Note that this virtual data frame can be extremely large, and it provides access to data stored in the Teradata Unified Data Architecture.
R>outgoing.calls <- ta.data.frame(“outgoing_calls”)
R>incoming.calls <- ta.data.frame(“incoming_calls”)
Now, lets have a look at the first and last records of each virtual data frame:
> ta.head(incoming.calls)
ID_CELL_A NUM_A ID_CELL_B NUM_B DAY HOUR DURATION
1: 380030021 f2187c6d2ee8c15fcfaef5a8e16bc13e 380030021 000000c861763358b3a68c346cd8103e 28/02/2013 11:28:59 167
2: 380030172 cabceccf96498011e7f9b1eb4efb2154 380030021 000000c861763358b3a68c346cd8103e 28/02/2013 11:40:12 86
3: 380030021 f2187c6d2ee8c15fcfaef5a8e16bc13e 380030021 000000c861763358b3a68c346cd8103e 28/02/2013 11:50:52 110
4: 380030021 f2187c6d2ee8c15fcfaef5a8e16bc13e 380030021 000000c861763358b3a68c346cd8103e 28/02/2013 13:08:30 301
5: 380030021 f2187c6d2ee8c15fcfaef5a8e16bc13e 380030021 000000c861763358b3a68c346cd8103e 28/02/2013 19:09:30 407
6: 381180045 f2187c6d2ee8c15fcfaef5a8e16bc13e 381180045 000000c861763358b3a68c346cd8103e 01/03/2013 08:15:51 765
> ta.tail(outgoing.calls)
ID_CELL_A NUM_A ID_CELL_B NUM_B DAY HOUR DURATION
1: 380170648 ffffe1a2a4dd2a6ef5cdfc4f99404d82 380170217 e7e8953caafe1ee9f19754368be57ce2 30/09/2013 15:43:51 118
2: 381181812 ffffe5d38cf3cc937c37f3fdaab705fa 381180542 ecd03464c3771a92660184365f9f3596 30/09/2013 09:03:21 171
3: 381180587 fffff973cfd726cf4d723f7d249b32e0 381180698 d6752c8f1466b7d619726dd970163d80 30/09/2013 13:38:41 134
4: 381180853 fffff973cfd726cf4d723f7d249b32e0 381180853 f30af0ffbe00838a37d99482a17ba2be 30/09/2013 18:37:53 20
5: 380060339 fffffa3d16ef46fc51886f753933c4a7 380061087 9b4b60ecfa08b22aefc2ecae798cf5aa 30/09/2013 18:02:16 59
6: 380060339 fffffa3d16ef46fc51886f753933c4a7 380060339 d8aa7a8ca273ba78a9e37dc3d58ab1d7 30/09/2013 18:24:09 1821
In each virtual data frame, NUM_A, refers to the phone number that is making the call, and NUM_B refers to the one that is receiving the call.
Now, we only get those interactions from calls with a duration greater than five seconds:
R>incoming.calls <- ta.subset(incoming.calls, DURATION > 5)
R>outgoing.calls <- ta.subset(outgoing.calls, DURATION > 5)
Since we are only interested in the interactions from one user to another, we can skip the cell towers, date time, and duration information:
R>incoming.calls <- incoming.calls[, c(2,4)]
R>outgoing.calls <- outgoing.calls[, c(2,4)]
Now, we can combine both data frames into one data frame by concatenating rows:
R> friends.calls <- ta.rbind(outgoing.calls, incoming.calls)
We assume a User A is a friend of User B if they called each other. We can compute the number of closed loops per friendship link by creating a dummy variable just with ones and using the Aster R parallel constructor to run this code in parallel across all the nodes and count closed loops:
R> friends.calls[“DUMMY”] <- 1
R> counting.friends.calls <- ta.tapply(friends.calls$DUMMY, list(friends.calls$NUM_A, friends.calls$NUM_B), sum)
Finally, we can have a look at the number of closed loops of each user and another one.
As an example, lets query the closed loops among number 9f2dc668556ec6353d5a197d8aabaf2 and f84af42b298dacd1cc479d8c814fac1a4:
R> counting.friends.calls <- ta.as.data.frame(counting.friends.calls)
R> counting.friends.calls[c(“9f2dc668556ec6353d5a197d8aabaf2”),c(“f84af42b298dacd1cc479d8c814fac1a4”)]/2
206
Note that we are dividing the total number by 2 because we are counting closed interactions, that is the number of times NUM_A calls NUM_B and NUM_B calls NUM_A back.
Benefits of an integrated scalable R solution
Aster R virtual data frames can be used directly with existing R functions (ta.* family), which is an important advantage over current open source solutions, such as the bigmemory R package. For example, matrices provided by bigmemory cannot be used directly by functions such as base::summary. Therefore, analysis must be done on subsets of the big.matrix using the available RAM, as with common R matrices. Furthermore, bigmemory only supports numeric matrices instead of more flexible data structures such as data frames.
It is also possible to use parallel programming abstractions in R programs. However, there are different mechanisms, and each one has its own interface, like the multicore, snow, parallel, and Rmpi packages. Therefore, different versions of the same code are required for each parallel mechanism. Another option is to use the foreach package, which is a framework that encapsulates the underlying parallel environment; however, this is not completely transparent to the developer because it requires use of the specific %dopar% syntax in the loops.
Teradata’s forthcoming Aster R product might provide solutions for managing and analyzing massive data using standard R syntax and allow the application of statistical analysis, regardless of the size of the problem and without requiring you to hire senior engineers to develop an in-house solution.
James Taylor, CEO and a Principal Consultant of Decision Management Solutions, and Bill Franks, Chief Analytics Officer of Teradata, will explore a day in the life of an R analyst during a free webcast on Tuesday, July 29th at 10 a.m. PDT / 1 p.m. EDT. Register for the free online event, presented in collaboration with Teradata.
This post is part of a collaboration between O’Reilly and Teradata. See our statement of editorial independence.