
Editor’s note: we’ll explore present and future applications of cryptocurrency and blockchain technologies at our upcoming Radar Summit: Bitcoin & the Blockchain on Jan. 27, 2015, in San Francisco.
A few data scientists are starting to play around with cryptocurrency data, and as bitcoin and related technologies start gaining traction, I expect more to wade in. As the space matures, there will be many interesting applications based on analytics over the transaction data produced by these technologies. The blockchain — the distributed ledger that contains all bitcoin transactions — is publicly available, and the underlying data set is of modest size. Data scientists can work with this data once it’s loaded into familiar data structures, but producing insights requires some domain knowledge and expertise.
Subscribe to the O’Reilly Data Show Podcast
I recently spoke with Sarah Meiklejohn, a lecturer at UCL, and an expert on computer security and cryptocurrencies. She was part of an academic research team that studied pseudo-anonymity (“pseudonymity”) in bitcoin. In particular, they used transaction data to compare “potential” anonymity to the “actual” anonymity achieved by users. A bitcoin user can use many different public keys, but careful research led to a few heuristics that allowed them to cluster addresses belonging to the same user:
“In theory, a user can go by many different pseudonyms. If that user is careful and keeps the activity of those different pseudonyms separate, completely distinct from one another, then they can really maintain a level of, maybe not anonymity, but again, cryptographically it’s called pseudo-anonymity. So, if they are a legitimate businessman on the one hand, they can use a certain set of pseudonyms for that activity, and then if they are dealing drugs on Silk Road, they might use a completely different set of pseudonyms for that, and you wouldn’t be able to tell that that’s the same user.
“It turns out in reality, though, the way most users and services are using bitcoin, was really not following any of the guidelines that you would need to follow in order to achieve this notion of pseudo-anonymity. So, basically, what we were able to do is develop certain heuristics for clustering together different public keys, or different pseudonyms. I’m happy to get into the technical details, but I’m not sure how relevant they are. The point is that, if you think these are good heuristics, then basically they provided evidence that a certain set of pseudonyms were called into the same owner. In that owner could be a single individual or it could be an entire service, like bit scams or another exchange.”
In the course of their research, Sarah and her collaborators realized that addresses used to collect excess bitcoins (“change addresses”) provided a good clustering mechanism:
“If you think about making change with physical cash, if I walk into a physical store and I hand the clerk a $20 bill, and my thing only costs $5, then I’m going to get $15 back in change, right? And in bitcoin, that process of making change is actually completely transparent, so you can observe the change public key in the blockchain.
“What we tried to do is distinguish change addresses, as we called them, from the legitimate recipient in the transaction. So, in my example in the store, you’d see two public keys as the out in that transaction, one of them would receive $5, and the other would receive $15. What we tried to do is develop a heuristic for distinguishing that $15 part of the transaction from the legitimate $5 recipient. That turned out to be much trickier, but that really was the bulk of the work in the project, just trying to make that heuristic as safe as possible.”
Once they settled on heuristics with which to cluster addresses, the research project still required a data set for testing their theories. This entailed conducting and following transactions through the bitcoin ledger:
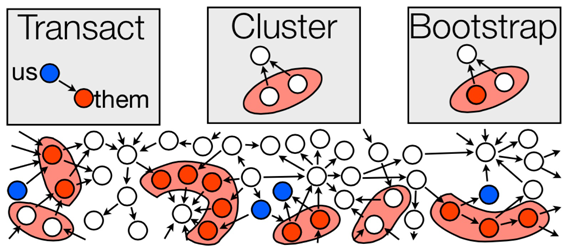
Image courtesy of Sarah Meiklejohn.
“The main issue with doing these clusters, with doing any kind of heuristics with bitcoin is that it’s very hard to test how well you are doing. You know there’s no ground truth data in bitcoin. And since part of the point of it is this anonymous cryptocurrency, people aren’t going to voluntarily reveal information, to allow you to test your heuristics or not. So we really had to collect this ground truth data ourselves. What this meant was this very manual process of doing our all in transactions, with as many users and services as we could find. For example, we opened up accounts with exchanges and deposited bitcoins into our accounts and withdrew them, and repeated this process with the same exchange many times, and with many different exchanges, and as you said, what we ended up with was this very carefully put together ground truth dataset. And then, layering this clustering on top of that dataset, let us sort of bootstrap from that very minimal amount of ground truth data to saying the same things about much larger clusters of public keys. And also, the ground truth data allowed us to try to measure our heuristics and try to validate our heuristics.
…
“I would say the main conclusion was that, if you are not carefully considering anonymity, then you are probably not really achieving it. As I said, there are guidelines that you can follow, to keep the activity of your different pseudonyms distinct. And we did see people following those sorts of guidelines. So they were completely evading detection. We sort of developed not just these clustering heuristics, but this kind of mechanism for trying to follow flows of bitcoin throughout the network. And so, if you are careful, then you could go undetected. But if you are not careful, which the majority of users do not seem to be, then you are actually exposing quite a lot of activity, perhaps unknowingly.”
The techniques they used are accessible, but their research relied on some familiarity with the underlying data (and the protocol that produces it). It’s a data set that requires some “unpacking” before one can dive into analytics. One way data scientists can contribute is by creating scalable tools for visual exploration:
“I think data visualization goes a long way. So even mapping out … as I mentioned, bitcoin induces this graph structure, where you can think of the notes as public keys, or you could do clustering as users, and then these edges representing transactions between them. So if you had some great data visualization tool where you could explore those relationships visually, I think that would be quite helpful. So we did try to develop such a tool, using D3, but I think we didn’t push it as far as we could’ve. And so that would already be a way of exploring these relationships, not just typing queries into a database, but actually seeing the information could allow you to spot anomalies or to spot really interesting relationships.”
You can listen to our entire interview in the SoundCloud player above, in our SoundCloud stream, or on iTunes.