
 When I first hear of a new open source project that might help me solve a problem, the first thing I do is ask around to see if any of my friends have tested it. Sometimes, however, the early descriptions sound so promising that I just jump right in and try it myself — and in a few cases, I transition immediately (this was certainly the case for Spark).
When I first hear of a new open source project that might help me solve a problem, the first thing I do is ask around to see if any of my friends have tested it. Sometimes, however, the early descriptions sound so promising that I just jump right in and try it myself — and in a few cases, I transition immediately (this was certainly the case for Spark).
I recently had a conversation with Erich Nachbar, founder and CTO of Virtual Power Systems, and one of the earliest adopters of Spark. In the early days of Spark, Nachbar was CTO of Quantifind, a startup often cited by the creators of Spark as one of the first “production deployments.” On the latest episode of the O’Reilly Data Show Podcast, we talk about the ease with which Nachbar integrates new open source components into existing infrastructure, his contributions to Mesos, and his new “software-defined power distribution” startup.
Ecosystem of open source big data technologies
When evaluating a new software component, nothing beats testing it against workloads that mimic your own. Nachbar has had the luxury of working in organizations where introducing new components isn’t subject to multiple levels of decision-making. But, as he notes, everything starts with testing things for yourself:
“I have sort of my mini test suite…If it’s a data store, I would just essentially hook it up to something that’s readily available, some feed like a Twitter fire hose, and then just let it be bombarded with data, and by now, it’s my simple benchmark to know what is acceptable and what isn’t for the machine…I think if more people, instead of reading papers and paying people to tell them how good or bad things are, would actually set aside a day and try it, I think they would learn a lot more about the system than just reading about it and theorizing about the system.
…
“For example, with Spark — we had an iterative processing that we did for Quantifind. If we had to spill to disk, run the usual MapReduce, it would have been probably 50 times slower because there is disk involved versus just keeping it in RAM and reprocessing it. I do try to look at what I see out there, and then if I see Spark can actually give us an edge, because I can’t buy 100 times more machines for this particular product feature, I switch to Spark and I can buy a little more RAM. That is a great trade-off to implementing product features that other people couldn’t, or would need to spend a lot more money for.
“I do try to refresh my stack by looking at, picking out which technology I think is right for disruption. For example, Kafka was a similar thing, where I tried the usual suspects like RabbitMQ and ActiveMQ. It was pretty clear that there was not really anything that worked as well as I thought it should.”
Software-defined power distribution
Nachbar’s new startup Virtual Power Systems uses sensors, big data, and algorithms to simplify the power infrastructure within data centers, while simultaneously increasing reliability and lowering costs. Nachbar explains:
“Pretty much everyone has accepted virtualization for compute…For most people, it sounds a bit counter-intuitive because it’s power and it’s, really, electricity, and you can’t really control it that easily. But the same principles apply also for software-defined power.
“The basic idea is that, instead of statically allocating power, which is the equivalent of buying a server that runs exactly from that location, you could really have software that essentially analyzes where power is needed — it will say, ‘Historically, this equipment has never used more than X kilowatts, and if the equipment actually uses more, we will be able to step in with lithium batteries and essentially flatten peaks.
“All the IT equipment is essentially hooked up to that same pool of power supplies and batteries, and then in software, you can find and pick how you want to run the equipment. You power it 30% from solar power because it’s sunny outside. You power 50% from utility, and you boost in the rest from batteries. Essentially, every rack stands on its own as its own media center. The software now becomes the sort of fabric that controls where power is being used. Essentially, every rack has an Ethernet port, and the software controls over a rest interface how these components interact with each other.”
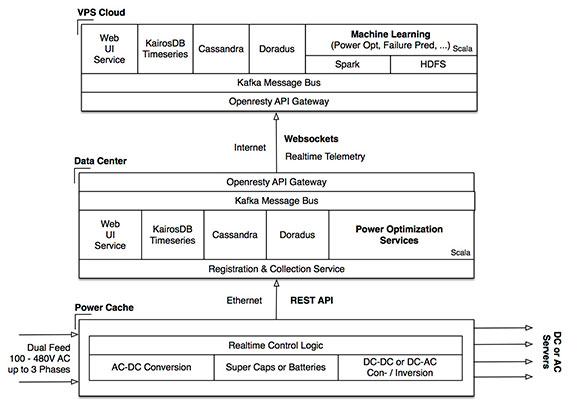
Virtual Power Systems: data flow and platform. Source: Erich Nachbar, used with permission.
Massive amounts of event data
When it comes to large-scale stream processing and analytics, the most interesting solutions are being developed for buildings, factories and machines (industrial Internet), and IT infrastructure (data center/DevOps). The data platform Nachbar and his team developed for processing event data relies on popular, open source, distributed computing components:
“So, one great thing that we haven’t implemented yet, but that would be great, is we record about every 100 milliseconds about 100 values about the power — including temperatures, power consumptions — and so you could really say, ‘Hey, you know what? I noticed that this rack has some vibrations. There is probably something in the server that’s about to fail, maybe a fan is vibrating or the batteries are getting too hot.’ … At the minimum level, we track everything about our equipment. For example, the temperature. We know that cells, when they tend to fail, they get warmer. … [We’re collecting] pretty much all-time, series-based data, and if you do that math, if you have 1,000 racks without even collecting any information about the actual equipment that is installed, it is uncompressed about 170 terabytes a year. … The idea is, basically, that I push [our data] into Kafka … a lot of people don’t realize that having a messaging system as your backbone, if you build anything data driven, it’s sort of almost like a must because otherwise you end up with this spaghetti architecture.”
Subscribe to the O’Reilly Data Show Podcast
You can listen to our entire interview in the SoundCloud player above, or subscribe through SoundCloud, TuneIn, or iTunes.
Cropped image on article and category pages by alex.ch on Flickr, used under a Creative Commons license.