- The Virtuous Pipeline of Code (Public Resource) — Chicago partnering with Public Resource to open its legal codes for good. “This is great! What can we do to help?” Bravo Chicago, and everyone else—take note!
- Smithsonian’s 3D Data — models of 21 objects, from a gunboat to the Wright Brothers’ plane, to a wooly mammoth skeleton, to Lincoln’s life masks. I wasn’t able to find a rights statement on the site which explicitly governed the 3D models. (via Smithsonian Magazine)
- Anki’s Robot Cars (Xconomy) — The common characteristics of these future products, in Sofman’s mind: “Relatively simple and elegant hardware; incredibly complicated software; and Web and wireless connectivity to be able to continually expand the experience over time.” (via Slashdot)
- An Empirical Evaluation of TCP Performance in Online Games — We show that because TCP was originally designed for unidirectional and network-limited bulk data transfers, it cannot adapt well to MMORPG traffic. In particular, the window-based congestion control and the fast retransmit algorithm for loss recovery are ineffective. Furthermore, TCP is overkill, as not every game packet needs to be transmitted in a reliably and orderly manner. We also show that the degraded network performance did impact users’ willingness to continue a game.
"open data" entries

Four short links: 18 November 2013
Chicago Code, 3D Smithsonian Data, AI Controlling Everything, and Game TCP
Four short links: 1 October 2013
Ploughbot, Amazon Warehouses, Kickstarting Safety, and The Island of Dr Thoreau
- Farmbot Wiki — open-source, scalable, automated precision farming machines.
- Amazon’s Chaotic Storage — photos from inside an Amazon warehouse. At the heart of the operation is a sophisticated database that tracks and monitors every single product that enters/leaves the warehouse and keeps a tally on every single shelf space and whether it’s empty or contains a product. Software-optimised spaces, for habitation by augmented humans.
- Public Safety Codes of the World — Kickstarter project to fund the release of public safety codes.
- #xoxo Thoreau Talk (Maciej Ceglowski) — exquisitely good talk by the Pinboard creator, on success, simplicity, and focus.
Four short links: 2 August 2013
Algorithmic Optimisation, 3D Scanners, Corporate Open Source, and Data Dives
- Unhappy Truckers and Other Algorithmic Problems — Even the insides of vans are subjected to a kind of routing algorithm; the next time you get a package, look for a three-letter letter code, like “RDL.” That means “rear door left,” and it is so the driver has to take as few steps as possible to locate the package. (via Sam Minnee)
- Fuel3D: A Sub-$1000 3D Scanner (Kickstarter) — a point-and-shoot 3D imaging system that captures extremely high resolution mesh and color information of objects. Fuel3D is the world’s first 3D scanner to combine pre-calibrated stereo cameras with photometric imaging to capture and process files in seconds.
- Corporate Open Source Anti-Patterns (YouTube) — Brian Cantrill’s talk, slides here. (via Daniel Bachhuber)
- Hacking for Humanity) (The Economist) — Getting PhDs and data specialists to donate their skills to charities is the idea behind the event’s organizer, DataKind UK, an offshoot of the American nonprofit group.

Ways to put the patient first when collecting health data
Report from 2013 Health Privacy Summit
The timing was superb for last week’s Health Privacy Summit, held on June 5 and 6 in Washington, DC. First, it immediately followed the 2000-strong Health Data Forum (Health Datapalooza), where concern for patients rights came up repeatedly. Secondly, scandals about US government spying were breaking out and providing a good backdrop for talking about protection our most sensitive personal information–our health data.
The health privacy summit, now in its third year, provides a crucial spotlight on the worries patients and their doctors have about their data. Did you know that two out of three doctors (and probably more–this statistic cites just the ones who admit to it on a survey) have left data out of a patient’s record upon the patient’s request? I have found that the summit reveals the most sophisticated and realistic assessment of data protection in health care available, which is why I look forward to it each year. (I’m also on the planning committee for the summit.) For instance, it took a harder look than most observers at how health care would be affected by patient access to data, and the practice of sharing selected subsets of data, called segmentation.
What effect would patient access have?
An odd perceptual discontinuity exists around patient access to health records. If you go to your doctor and ask to see your records, chances are you will be turned down outright or forced to go through expensive and frustrating magical passes. One wouldn’t know that HIPAA explicitly required doctors long ago to give patients their data, or that the most recent meaningful use rules from the Department of Health and Human Services require doctors to let patients view, download, and transmit their information within four business days of its addition to the record.

Strata Week: President Obama opens up U.S. government data
U.S. opens data, Wong tapped for U.S. chief privacy officer, FBI might read your email sans warrant, and big data spells trouble for anonymity.
U.S. government data to be machine-readable, Nicole Wong may fill new White House chief privacy officer role
The U.S. government took major steps this week to open up government data to the public. U.S. President Obama signed an executive order requiring government data to be made available in machine-readable formats, and the Office of Management and Budget and the Office of Science and Technology Policy released a Open Data Policy memo (PDF) to address the order’s implementation.
The press release announcing the actions notes the benefit the U.S. economy historically has experienced with the release of government data — GPS data, for instance, sparked a flurry of innovation that ultimately contributed “tens of billions of dollars in annual value to the American economy,” according to the release. President Obama noted in a statement that he hopes a similar result will come from this open data order: “Starting today, we’re making even more government data available online, which will help launch even more new startups. And we’re making it easier for people to find the data and use it, so that entrepreneurs can build products and services we haven’t even imagined yet.”
FCW’s Adam Mazmanian notes a bit from the Open Data Policy memo that indicates the open data framework doesn’t only apply to data the government intends to make public. Read more…

Linking open data to augmented intelligence and the economy
Nigel Shadbolt on AI, ODI, and how personal, open data could empower consumers in the 21st century.
After years of steady growth, open data is now entering into public discourse, particularly in the public sector. If President Barack Obama decides to put the White House’s long-awaited new open data mandate before the nation this spring, it will finally enter the mainstream.
As more governments, businesses, media organizations and institutions adopt open data initiatives, interest in the evidence behind release and the outcomes from it is similarly increasing. High hopes abound in many sectors, from development to energy to health to safety to transportation.
“Today, the digital revolution fueled by open data is starting to do for the modern world of agriculture what the industrial revolution did for agricultural productivity over the past century,” said Secretary of Agriculture Tom Vilsack, speaking at the G-8 Open Data for Agriculture Conference.
As other countries consider releasing their public sector information as data and machine-readable formats onto the Internet, they’ll need to consider and learn from years of effort at data.gov.uk, data.gov in the United States, and Kenya in Africa.
 One of the crucial sources of analysis for the success or failure of open data efforts will necessarily be research institutions and academics. That’s precisely why research from the Open Data Institute and Professor Nigel Shadbolt (@Nigel_Shadbolt) will matter in the months and years ahead.
One of the crucial sources of analysis for the success or failure of open data efforts will necessarily be research institutions and academics. That’s precisely why research from the Open Data Institute and Professor Nigel Shadbolt (@Nigel_Shadbolt) will matter in the months and years ahead.
In the following interview, Professor Shadbolt and I discuss what lies ahead. His responses were lightly edited for content and clarity.
Read more…
Sprinting toward the future of Jamaica
Open data is fundamental to democratic governance and development, say Jamaican officials and academics.
Creating the conditions for startups to form is now a policy imperative for governments around the world, as Julian Jay Robinson, minister of state in Jamaica’s Ministry of Science, Technology, Energy and Mining, reminded the attendees at the “Developing the Caribbean” conference last week in Kingston, Jamaica.

Robinson said Jamaica is working on deploying wireless broadband access, securing networks and stimulating tech entrepreneurship around the island, a set of priorities that would have sounded of the moment in Washington, Paris, Hong Kong or Bangalore. He also described open access and open data as fundamental parts of democratic governance, explicitly aligning the release of public data with economic development and anti-corruption efforts. Robinson also pledged to help ensure that Jamaica’s open data efforts would be successful, offering a key ally within government to members of civil society.
The interest in adding technical ability and capacity around the Caribbean was sparked by other efforts around the world, particularly Kenya’s open government data efforts. That’s what led the organizers to invite Paul Kukubo to speak about Kenya’s experience, which Robinson noted might be more relevant to Jamaica than that of the global north. Read more…
Strata Week: Our phones are giving us away
Anonymized phone data isn't as anonymous as we thought, a CFPB API, and NYC's "geek squad of civic-minded number-crunchers."
Mobile phone mobility traces ID users with only four data points
A study published this week by Scientific Reports, Unique in the Crowd: The privacy bounds of human mobility, shows that the location data in mobile phones is posing an anonymity risk. Jason Palmer reported at the BBC that researchers at MIT and the Catholic University of Louvain reviewed data from 15 months’ worth of phone records for 1.5 million people and were able to identify “mobility traces,” or “evident paths of each mobile phone,” using only four locations and times to positively identify a particular user. Yves-Alexandre de Montjoye, the study’s lead author, told Palmer that “[t]he way we move and the behaviour is so unique that four points are enough to identify 95% of people.”

Four short links: 28 March 2013
Chinese Lessons, White House Embraces Makers, DC Codes Freed, and Malware Numbers
- What American Startups Can Learn From the Cutthroat Chinese Software Industry — It follows that the idea of “viral” or “organic” growth doesn’t exist in China. “User acquisition is all about media buys. Platform-to-platform in China is war, and it is fought viciously and bitterly. If you have a Gmail account and send an email to, for example, NetEase163.com, which is the local web dominant player, it will most likely go to spam or junk folders regardless of your settings. Just to get an email to go through to your inbox, the company sending the email needs to have a special partnership.” This entire article is a horror show.
- White House Hangout Maker Movement (Whitehouse) — During the Hangout, Tom Kalil will discuss the elements of an “all hands on deck” effort to promote Making, with participants including: Dale Dougherty, Founder and Publisher of MAKE; Tara Tiger Brown, Los Angeles Makerspace; Super Awesome Sylvia, Super Awesome Maker Show; Saul Griffith, Co-Founder, Otherlab; Venkatesh Prasad, Ford.
- Municipal Codes of DC Freed (BoingBoing) — more good work by Carl Malamud. He’s specifically providing data for apps.
- The Modern Malware Review (PDF) — 90% of fully undetected malware was delivered via web-browsing; It took antivirus vendors 4 times as long to detect malware from web-based applications as opposed to email (20 days for web, 5 days for email); FTP was observed to be exceptionally high-risk.
Sensoring the news
Sensor journalism will augment our ability to understand the world and hold governments accountable.
When I went to the 2013 SXSW Interactive Festival to host a conversation with NPR’s Javaun Moradi about sensors, society and the media, I thought we would be talking about the future of data journalism. By the time I left the event, I’d learned that sensor journalism had long since arrived and been applied. Today, inexpensive, easy-to-use open source hardware is making it easier for media outlets to create data themselves.
“Interest in sensor data has grown dramatically over the last year,” said Moradi. “Groups are experimenting in the areas of environmental monitoring, journalism, human rights activism, and civic accountability.” His post on what sensor networks mean for journalism sparked our collaboration after we connected in December 2011 about how data was being used in the media.
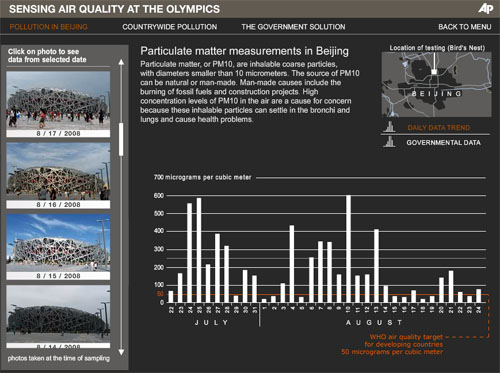
Associated Press visualization of Beijing air quality. See related feature.
At a SXSW panel on “sensoring the news,” Sarah Williams, an assistant professor at MIT, described how the Spatial Information Design Lab At Columbia University* had partnered with the Associated Press to independently measure air quality in Beijing.
Prior to the 2008 Olympics, the coaches of the Olympic teams had expressed serious concern about the impact of air pollution on the athletes. That, in turn, put pressure on the Chinese government to take substantive steps to improve those conditions. While the Chinese government released an index of air quality, explained Williams, they didn’t explain what went into it, nor did they provide the raw data.
The Beijing Air Tracks project arose from the need to determine what the conditions on the ground really were. AP reporters carried sensors connected to their cellphones to detect particulate and carbon monoxide levels, enabling them to report air quality conditions back in real-time as they moved around the Olympic venues and city. Read more…