- MacroBase — Analytic monitoring for the Internet of Things. The code behind a research paper, written up in the morning paper where Adrian Colyer says, there is another story that also unfolds in the paper – one of careful system design based on analysis of properties of the problem space, of thinking deeply and taking the time to understand the prior art (aka “the literature”), and then building on those discoveries to advance and adapt them to the new situation. “That’s what research is all about!” you may say, but it’s also what we’d (I’d?) love to see more of in practitioner settings, too. The result of all this hard work is a system that comprises just 7,000 lines of code, and I’m sure, many, many hours of thinking!
- Survey of Commenters and Comment Readers — Americans who leave news comments, who read news comments, and who do neither are demographically distinct. News commenters are more male, have lower levels of education, and have lower incomes compared to those who read news comments. (via Marginal Revolution)
- The Empathizing-Systemizing Theory, Social Abilities, and Mathematical Achievement in Children (Nature) — systematic thinking doesn’t predict math ability in children, but being empathetic predicts being worse at math. The effect is stronger with girls. The authors propose the mechanism is that empathetic children pick up a teacher’s own dislike of math, and any teacher biases like “girls aren’t good at math.”
- Moneyball for Book Publishers: A Detailed Look at How We Read (NYT) — On average, fewer than half of the books tested were finished by a majority of readers. Most readers typically give up on a book in the early chapters. Women tend to quit after 50 to 100 pages, men after 30 to 50. Only 5% of the books Jellybooks tested were completed by more than 75% of readers. Sixty percent of books fell into a range where 25% to 50% of test readers finished them. Business books have surprisingly low completion rates. Not surprisingly low to anyone who has ever read a business book. They’re always a 20-page idea stretched to 150 pages because that’s how wide a book’s spine has to be to visible on the airport bookshelf. Fat paper stock and 14-point text with wide margins and 1.5 line spacing help, too. Don’t forget to leave pages after each chapter for the reader’s notes. And summary checklists. And … sorry, I need to take a moment.
"streaming data" entries

Four short links: 16 March 2016
Analytic Monitoring, Commenter Demographics, Math and Empathy, and How We Read

A real-time tool for a real-time problem
Using VoltDB and the Lambda Architecture to locate abnormal behavior.

Subscriber Identity Module box (SIMbox) fraud is a type of telecommunications fraud where users avoid an international outbound-calls charge by redirecting the call through voice over IP to a SIM in the country where the destination is located. This is an issue we helped a client address at Wise Athena.
Taking on this type of problem requires a stream-based analysis of the Call Detail Record (CDR) logs, which are typically generated quickly. Detecting this kind of activity requires in-memory computations of streaming data. You might also need to scale horizontally.
We recently evaluated the use of VoltDB together with our cognitive analytics and machine-learning system to analyze CDRs and provide accurate and fast SIMbox fraud detection. At the beginning, we used batch processing to detect SIMbox fraud, but the response time took too long, so we switched to a technology that allows in-memory computations in order to reach the desired time constraints.
VoltDB’s in-memory distributed database provides transactions at streaming speed in a fast environment. It can support millions of small transactions per second. It also allows streaming aggregation and fast counters over incoming data. These attributes allowed us to develop a real-time analytics layer on top of VoltDB. Read more…
Four short links: 2 April 2015
250 Whys, Amazon Dash, Streaming Data, and Lightning Networks
- What I Learned from 250 Whys — Let’s Plan for a Future Where We’re All As Stupid as We Are Today.
- Thoughts on Amazon Dash (Matt Webb) — In a way, we’re really seeing the future of marketing here. We’ve separated awareness (advertising) and distribution (stores) for so long, but it’s no longer the way. When you get a Buy Now button in a Tweet, you’re seeing ads and distribution merging, and the Button is the physical instantiation of this same trend. […] in the future every product will carry a buy button.
- A Collection of Links for Streaming Algorithms and Data Structures — is this not the most self-evident title ever?
- Lightning Networks (Rusty Russell) — I finally took a second swing at understanding the Lightning Network paper. The promise of this work is exceptional: instant, reliable transactions across the bitcoin network. But the implementation is complex, and the draft paper reads like a grab bag of ideas; but it truly rewards close reading! It doesn’t involve novel crypto, nor fancy bitcoin scripting tricks. There are several techniques that are used in the paper, so I plan to concentrate on one per post and wrap up at the end. Already posted part II.
Four short links: 27 June 2014
Google MillWheel, 20yo Bug, Fast Real-Time Visualizations, and Google's Speed King
- MillWheel: Fault-Tolerant Stream Processing at Internet Scale — Google Research paper on the tech underlying the new cloud DataFlow tool. Watch the video. Yow.
- The Integer Overflow Bug That Went to Mars — long-standing (20 year old!) bug in a compression library prompts a wave of new releases. No word yet on whether NASA will upgrade the rover to avoid being pwned by Martian script kiddies. (update: I fell for a self-promoter. The Martians will need to find another attack vector. Huzzah!)
- epoch (github) — Fastly-produced open source general purpose real-time charting library for building beautiful, smooth, and high performance visualizations.
- Achieving Rapid Response Times in Large Online Services (YouTube) — Jeff Dean‘s keynote at Velocity. He wrote … a lot of things for this. And now he’s into deep learning ….

Expanding options for mining streaming data
New tools make it easier for companies to process and mine streaming data sources
Stream processing was in the minds of a few people that I ran into over the past week. A combination of new systems, deployment tools, and enhancements to existing frameworks, are behind the recent chatter. Through a combination of simpler deployment tools, programming interfaces, and libraries, recently released tools make it easier for companies to process and mine streaming data sources.
Of the distributed stream processing systems that are part of the Hadoop ecosystem0, Storm is by far the most widely used (more on Storm below). I’ve written about Samza, a new framework from the team that developed Kafka (an extremely popular messaging system). Many companies who use Spark express interest in using Spark Streaming (many have already done so). Spark Streaming is distributed, fault-tolerant, stateful, and boosts programmer productivity (the same code used for batch processing can, with minor tweaks, be used for realtime computations). But it targets applications that are in the “second-scale latencies”. Both Spark Streaming and Samza have their share of adherents and I expect that they’ll both start gaining deployments in 2014.
Stream Processing and Mining just got more interesting
A general purpose stream processing framework from the team behind Kafka and new techniques for computing approximate quantiles
Largely unknown outside data engineering circles, Apache Kafka is one of the more popular open source, distributed computing projects. Many data engineers I speak with either already use it or are planning to do so. It is a distributed message broker used to store1 and send data streams. Kafka was developed by Linkedin were it remains a vital component of their Big Data ecosystem: many critical online and offline data flows rely on feeds supplied by Kafka servers.
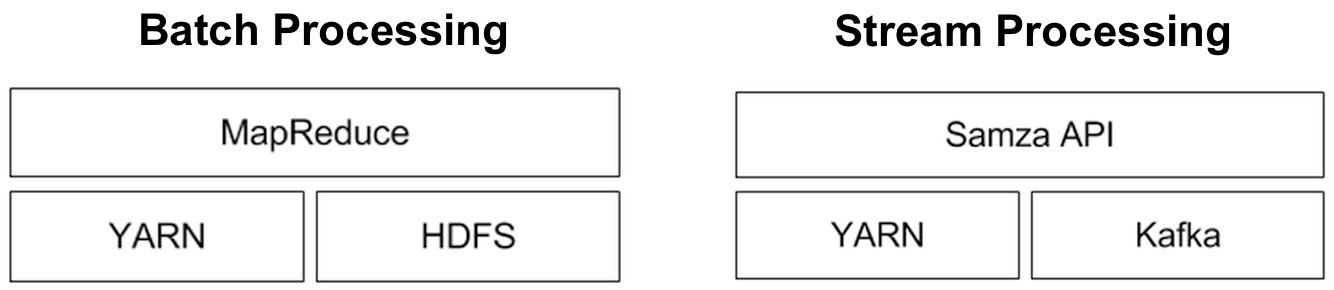
Apache Samza: a distributed stream processing framework
Behind Kafka’s success as an open source project is a team of savvy engineers who have spent2 the last three years making it a rock solid system. The developers behind Kafka realized early on that it was best to place the bulk of data processing (i.e., stream processing) in another system. Armed with specific use cases, work on Samza proceeded in earnest about a year ago. So while they examined existing streaming frameworks (such as Storm, S4, Spark Streaming), Linkedin engineers wanted a system that better fit their needs3 and requirements:
Near realtime, streaming, and perpetual analytics
Hadoop moves from batch to near realtime: next up, placing streaming data in context
Simple example of a near realtime app built with Hadoop and HBase
Over the past year Hadoop emerged from its batch processing roots and began to take on interactive and near realtime applications. There are numerous examples that fall under these categories, but one that caught my eye recently is a system jointly developed by China Mobile Guangdong (CMG) and Intel1. It’s an online system that lets CMG’s over 100 million subscribers2 access and pay their bills, and examine their CDR’s (call detail records) in near realtime.
A service for providing detailed billing information is an important customer touch point. Repeated/extended downtimes and data errors could seriously tarnish CMG’s image. CMG needed a system that could scale to their current (and future) data volumes, while providing the low-latency responses consumers have come to expect from online services. Scalability, price and open source3 were important criteria in persuading the company to choose a Hadoop-based solution over4 MPP data warehouses.
In the system it co-developed with Intel, CMG stores detailed subscriber billing records in HBase. This amounts to roughly 30 TB/month, but since the service lets users browse up to six months of billing data it provides near realtime query results on much larger amounts of data. There are other near realtime applications built from Hadoop components (notably the continuous compute system at Yahoo!), that handle much larger data sets. But what I like about the CMG example is that it’s an application that most people understand right away (a detailed billing lookup system), and it illustrates that the Hadoop ecosystem has grown beyond batch processing.
Besides powering their online billing lookup service, CMG uses its Hadoop platform for analytics. Data from multiple sources (including phone device preferences, usage patterns, and cell tower performance) are used to compute customer segments and targeted promotions. Over time, Hadoop’s ability to handle large amounts of unstructured data opens up other data sources that can potentially improve CMG’s current analytic models.
Contextualize: Streaming and Perpetual Analytics
This leads me to something “realtime” systems are beginning to do: placing streaming data in context. Streaming analytics operates over fixed time windows and is used to identify “top k” trending items, heavy-hitters, and distinct items. Perpetual analytics takes what you’re observing now and places it in the context of what you already know. As much as companies appreciate metrics produced by streaming engines, they also want to understand how “realtime observations” affect their existing knowledge base.
Pattern-detection and Twitter’s Streaming API
In some key use cases a random sample of tweets can capture important patterns and trends
Researchers and companies who need social media data frequently turn to Twitter’s API to access a random sample of tweets. Those who can afford to pay (or have been granted access) use the more comprehensive feed (the firehose) available through a group of certified data resellers. Does the random sample of tweets allow you to capture important patterns and trends? I recently came across two papers that shed light on this question.
Systematic comparison of the Streaming API and the Firehose
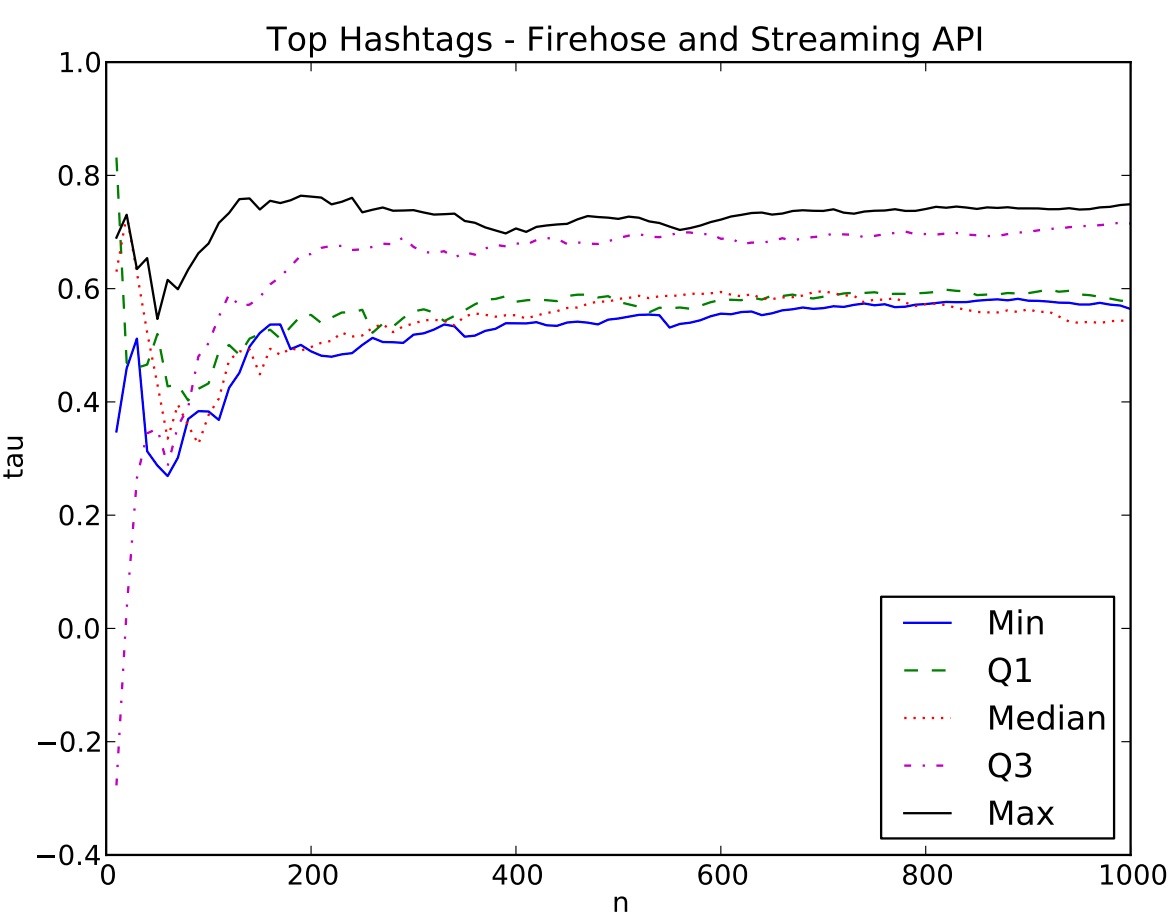
A recent paper from ASU and CMU compared data from the streaming API and the firehose, and found mixed results. Let me highlight two cases addressed in the paper: identifying popular hashtags and influential users.
Of interest to many users is the list of top hashtags. Can one identify the “top n” hastags using data made available throughthe streaming API? The graph below is a comparison of the streaming API to the firehose: n (as in “top n” hashtags) vs. correlation (Kendall’s Tau). The researchers found that the streaming API provides a good list of hashtags when n is large, but is misleading for small n.
Scalable streaming analytics using a single-server
The simplest and quickest way to mine your data is to deploy efficient algorithms designed to answer key questions at scale.
For many organizations real-time1 analytics entails complex event processing systems (CEP) or newer distributed stream processing frameworks like Storm, S4, or Spark Streaming. The latter have become more popular because they are able to process massive amounts of data, and fit nicely with Hadoop and other cluster computing tools. For these distributed frameworks peak volume is function of network topology/bandwidth and the throughput of the individual nodes.
Scaling up machine-learning: Find efficient algorithms
Faced with having to crunch through a massive data set, the first thing a machine-learning expert will try to do is devise a more efficient algorithm. Some popular approaches involve sampling, online learning, and caching. Parallelizing an algorithm tends to be lower on the list of things to try. The key reason is that while there are algorithms that are embarrassingly parallel (e.g., naive bayes), many others are harder to decouple. But as I highlighted in a recent post, efficient tools that run on single servers can tackle large data sets. In the machine-learning context recent examples2 of efficient algorithms that scale to large data sets, can be found in the products of startup SkyTree.

Five big data predictions for 2012
Edd Dumbill looks at the hot topics in data for the coming year.
The coming year of big data will bring developments in streaming data frameworks and data marketplaces, along with a maturation in the roles and processes of data science.