
Researchers and companies who need social media data frequently turn to Twitter’s API to access a random sample of tweets. Those who can afford to pay (or have been granted access) use the more comprehensive feed (the firehose) available through a group of certified data resellers. Does the random sample of tweets allow you to capture important patterns and trends? I recently came across two papers that shed light on this question.
Systematic comparison of the Streaming API and the Firehose
A recent paper from ASU and CMU compared data from the streaming API and the firehose, and found mixed results. Let me highlight two cases addressed in the paper: identifying popular hashtags and influential users.
Of interest to many users is the list of top hashtags. Can one identify the “top n” hastags using data made available throughthe streaming API? The graph below is a comparison of the streaming API to the firehose: n (as in “top n” hashtags) vs. correlation (Kendall’s Tau). The researchers found that the streaming API provides a good list of hashtags when n is large, but is misleading for small n.
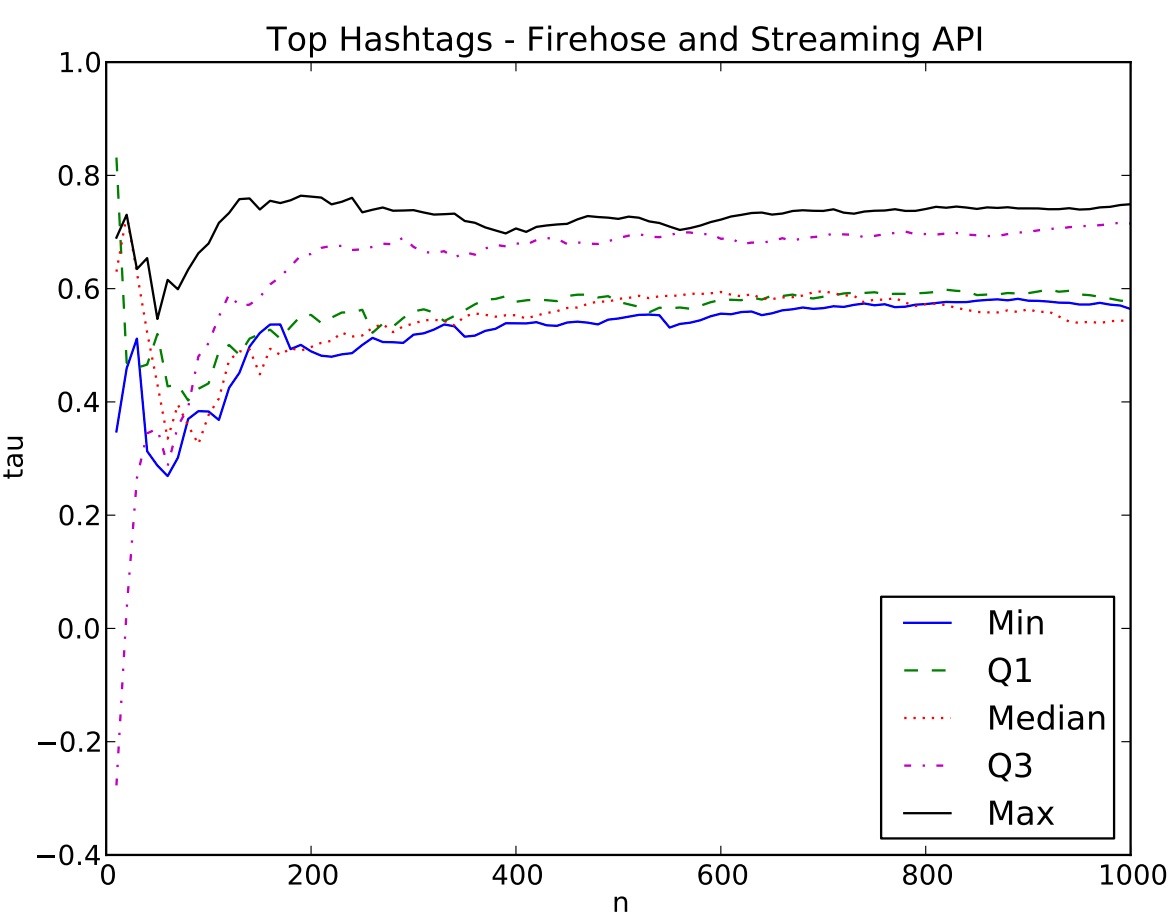
Another area of interest is identifying influential users. The study found that one can identify a majority of the most important users just from data available through the streaming API. More precisely1, the researchers could identify anywhere from “50–60% of the top 100 key-players when creating the networks based on one day of Streaming API data”.
Identifying trending topics on Twitter
When people describe Twitter as a source of “breaking news”, they’re referring to the list2 of trending topics it produces. A spot on that list is highly coveted3, and social media marketers mount campaigns designed to secure a place on it. The algorithm for how trending topics were identified was shrouded in mystery up until early this year, when a blog post (announcing the release of a new search app) hinted at how Twitter identifies trends:
Our approach to compute the burstiness of image and news facets is an extension of original work by Jon Kleinberg on bursty structure detection, which is in essence matching current level of burst to one of a predefined set of bursty states, while minimizing too diverse a change in matched states for smooth estimation.
I recently came across an interesting data-driven (“nonparametric”) method for identifying trending topics on Twitter. It works like a “weighted majority vote k-nearest-neighbors”, and uses a set of reference signals (a collection of some topics that trended and some that did not) to compare against.
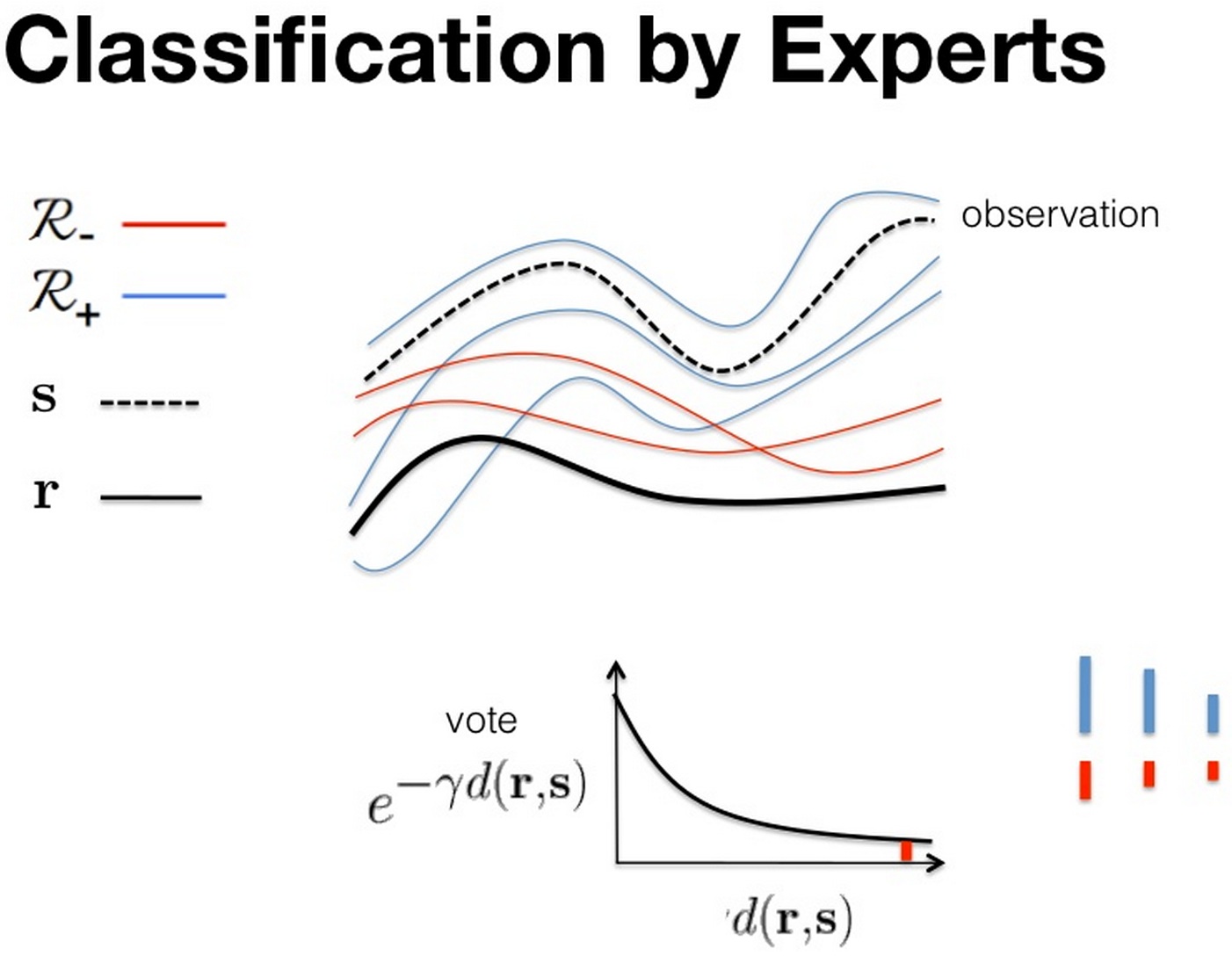
In order to test their new trend spotting technique, the MIT researchers used data similar3 to what’s available on the Twitter API. Their method produced impressive results: 95% true positive rate (4% false positive), and in 79% of the cases they detected trending topics more than an hour prior to their appearance on Twitter’s list.
The researchers were up against a black box (Twitter’s precise algorithm) yet managed to produce a technique that appears more prescient. As Twimpact co-founder, Mikio Braun, pointed out in a tweet, in essence we have two methods for identifying trends – the official (parametric) model used by Twitter, being estimated by a new (nonparametric) model introduced by the team from MIT!
Related posts:
(1) For their tests, the researchers assembled graphs whose nodes were comprised of users who tweeted or who were retweeted over given time periods. They measured influence using different notions of centrality.
(2) As with any successful “top n” list, once it takes off, spammers take notice.
(3) A 2011 study from HP labs examined what kinds of topics end up on this coveted list (turns out two common sources are retweets of stories from influential stories and new hashtags).
(3) From Stanislav Nikolov’s Masters thesis: “We obtained all data directly from Twitter via the MIT VI-A thesis program. However, the type as well as the amount of data we have used is all publicly available via the Twitter API.”
 O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
Strata Rx Health Data Conference: September 25-27 | Boston, MA
Strata + Hadoop World: October 28-30 | New York, NY
Strata in London: November 15-17 | London, England