
Guest blogger Andrew Clay Shafer is helping telcos and hosting providers implement cloud services at Cloudscaling. He co-founded Reductive Labs, creators of Puppet, the configuration management framework. Andrew preaches the “infrastructure is code” gospel, and he supports approaches for applying agile methods to infrastructure and operations. Some of those perspectives were captured in his chapter in the O’Reilly book “Web Operations.”
“Technical debt” is used two ways in the analysis of software systems. The phrase was first introduced in 1992 by Ward Cunningham to describe the premise that increased speed of delivery provides other advantages, and that the debt leveraged to gain those advantages should be strategically paid back.
Somewhere along the way, technical debt also became synonymous with poor implementation; reflecting the difference between the current state of a code base and an idealized one. I have used the term both ways, and I think they both have merit.
Technical debt can be extended and discussed along several additional axes: process debt, personnel debt, experience debt, user experience debt, security debt, documentation debt, etc. For this discussion, I won’t quibble about the nuances of categorization. Instead, I want to take a high-level look at operations and infrastructure choices people make and the impact of those choices.
The technical debt metaphor
Debts are created by some combination of choice and circumstance. Modern economies are predicated on the flow of debt as much as anything else, but not all debt is created equal. There is a qualitative difference between a mortgage and carrying significant debt on maxed-out credit cards. The point being that there are a variety of ways to incur debt, and the quality of debts have different consequences.
Jesse Robbins’ Radar post about operations as the secret sauce talked about boot strapping web startups in 80 hours. It included the following infographic showing the time cost of traditional versus special sauce operations:
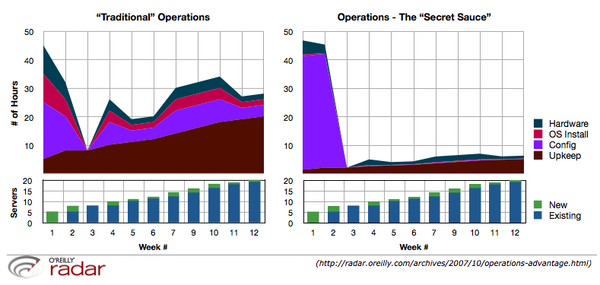
I contend that the ongoing difference in time cost between the two solutions is the interest being paid on technical debt.
Understanding is really the crux of the matter. No one who really understands compound interest would intentionally make frivolous purchases on a credit card and not make every effort to pay down high interest debt. Just as no one who really understands web operations would create infrastructure with an exponentially increasing cost of maintenance. Yet, people do both of these things.
As the graph is projected out, the ongoing cost of maintenance in both projects reflects the maxim of “the rich get richer.” One project can focus on adding value and differentiating itself in the market while the other will eventually be crushed under the weight of its own maintenance.
Technical debt and the Big Ball of Mud
Without a counterbalancing investment, system and software architectures succumb to entropy and become more difficult to understand. The classic “Big Ball of Mud” by Brian Foote and Joseph Yoder catalogs forces that contribute to the creation of haphazard and undifferentiated software architectures. They are:
- Time
- Cost
- Experience
- Skill
- Visibility
- Complexity
- Change
- Scale
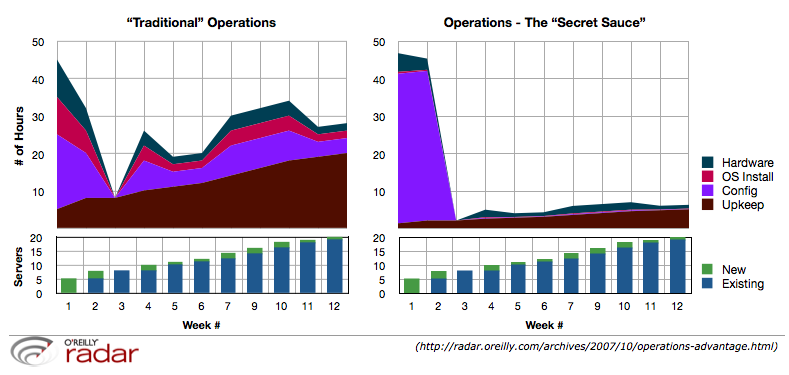
These same forces apply just as much to infrastructure and operations, especially if you understand the “infrastructure is code” mantra. If you look at the original “Tale of Two Ops Teams” graphic, both teams spent almost the same amount of time before the launch. If we assume that these are representative, then the difference between the two approaches is essentially experience and skill, which is likely to be highly correlated with cost. As the project moves forward, the difference in experience and skill reflects itself in how the teams spend time, provide visibility and handle complexity, change and scale.
{kind=link}
Using this list, and the assumption that balls of mud are synonymous with high technical debt, combating technical debt becomes an exercise in minimizing the impact of these forces.
- Time and cost are what they are, and often have an inverse relationship. From a management perspective, I would like everything now and for free, so everything else is a compromise. Undue time pressure will always result in something else being compromised. That compromise will often start charging interest immediately.
- Experience is invaluable, but sometimes hard to measure and overvalued in technology. Doing the same thing over and over with a technology is not 10 years of experience, it is the first year of experience 10 times. Intangible experience should not be measured in time, and experience in this sense is related to skill.
- Visibility has two facets in ops work: Visibility into the design and responsibilities of the systems, and real-time metrics and alerting on the state of the system. The first allows us to take action, the second informs us that we should.
- Complex problems can require complex solutions. Scale and change add complexity. Complexity obscures visibility and understanding.
Each of these forces and specific examples of how they impact infrastructure would fill a book, but hopefully that is enough to get people thinking and frame a discussion.
There is a force that may be missing from the “Big Ball of Mud”: tools (which might be an oversight, might be an attempt to remain tool-agnostic, or might be considered a cross-cutting aspect of cost, experience and skill). That’s not to say that tools don’t add some complexity and the potential for technical debt as well. But done well, tools provide ongoing insight into how and why systems are configured the way they are, illumination of the complexity and connections of the systems, and a mechanism to rapidly implement changes. That is just an example. Every tool choice, from the operating system, to the web server, to the database, to the monitoring and more, has an impact on the complexity, visibility and flexibility of the systems, and therefore impacts operations effectiveness.
Many parallels can be drawn between operations and fire departments. One big difference is most fire departments don’t spend much time actually putting out fires. If operations is reacting all the time, that indicates considerable technical debt. Furthermore, in reactive environments, the probability is high that the solutions of today are contributing to the technical debt and the fires of tomorrow.
Focus must be directed toward getting the fires under control in a way that doesn’t contribute to future fires. The coarse metric of time spent reactively responding to incidents versus the time spent proactively completing ops-related projects is a great starting point for understanding the situation. One way to insure operations is always a cost center is to keep treating it like one. When the flow of technical debt is understood and well managed, operations is certainly a competitive advantage.
Related: