
As organizations continue to accumulate data, there has been renewed interest in interactive query engines that scale to terabytes (even petabytes) of data. Traditional MPP databases remain in the mix, but other options are attracting interest. For example, companies willing to upload data into the cloud are beginning to explore Amazon Redshift1, Google BigQuery, and Qubole.
A variety of analytic engines2 built for Hadoop are allowing companies to bring its low-cost, scale-out architecture to a wider audience. In particular, companies are rediscovering that SQL makes data accessible to lots of users, and many prefer3 not having to move data to a separate (MPP) cluster. There are many new tools that seek to provide an interactive SQL interface to Hadoop, including Cloudera’s Impala, Shark, Hadapt, CitusDB, Pivotal-HD, PolyBase4, and SQL-H.
An open source benchmark from UC Berkeley’s Amplab
A benchmark for tracking the progress5 of scalable query engines has just been released. It’s a worthy first effort, and its creators hope to grow the list of tools to include other open source (Drill, Stinger) and commercial6 systems. As these query engines mature and features get added, data from this benchmark can provide a quick synopsis of performance improvements over time.
The initial release includes Redshift, Hive, Impala, and Shark (Hive, Impala, Shark were configured to run on AWS). Hive 0.10 and the most recent versions7 of Impala and Shark were used (Hive 0.11 was released in mid-May and has not yet been included). Data came from Intel’s Hadoop Benchmark Suite and CommonCrawl. In the case of Hive/Impala/Shark, data was stored in compressed SequenceFile format using CDH 4.2.0.
Initial Findings
At least for the queries included in the benchmark, Redshift is about 2-3x faster than Shark/on-disk, and 0.3-2x faster than Shark/in-memory. Given that it’s built on top of a general purpose engine (Spark), it’s encouraging that Shark’s performance is within range of MPP8 databases (such as Redshift) that are highly optimized for interactive SQL queries. With new frameworks like Shark and Impala providing speedups comparable to those observed in MPP databases, organizations now have the option of using a single system (Hadoop/Spark) instead of two (Hadoop/Spark + MPP database).
Let’s look at some of the results in detail:
Exploratory SQL Queries
This test involves scanning and filtering operations on progressively larger data sets. Not surprisingly, the fastest results come when Impala and Shark9 could fit data in-memory. For the largest data set (Query 1C), Redshift is about 2x faster than Shark (on-disk) and 9x faster than Impala (on-disk).
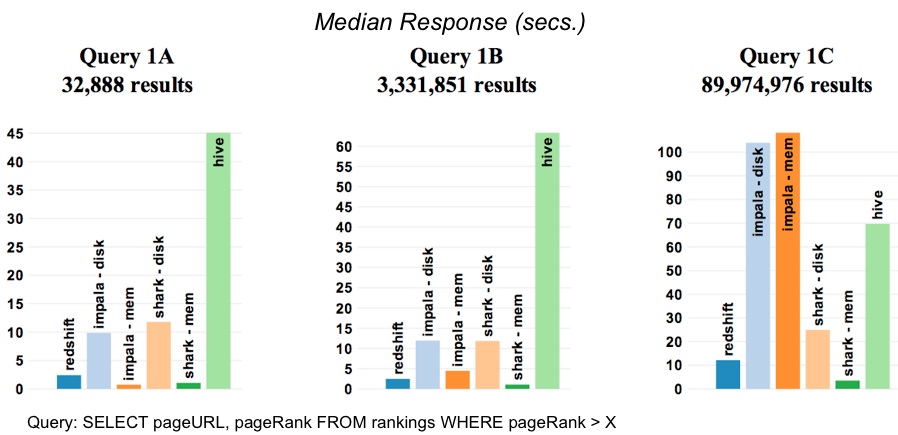
… As the result sets get larger, Impala becomes bottlenecked on the ability to persist the results back to disk. It seems as if writing large tables is not yet optimized in Impala, presumably because its core focus is BI-style queries.
Aggregations
This test involves string parsing and aggregation (where the number of groups progressively gets larger). Focusing on results for the largest data set (Query 2C), Redshift is 3x faster than Shark (on-disk) and 6x faster than Impala (on-disk).
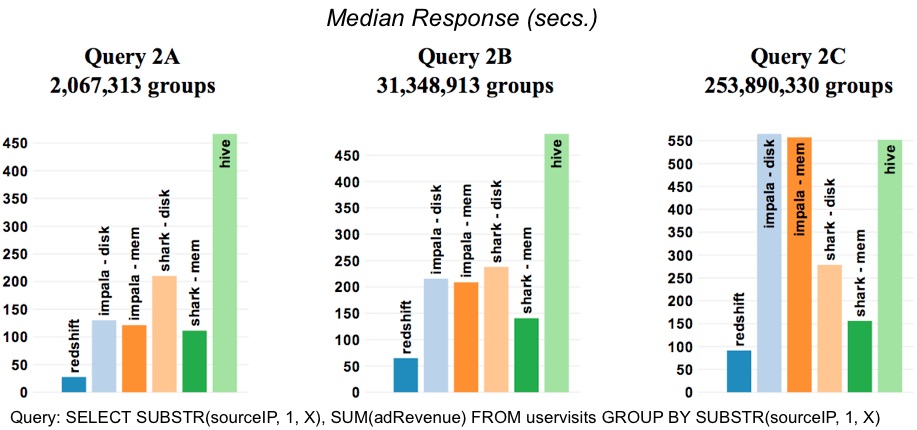
… Redshift’s columnar storage provides greater benefit … since several columns of the UserVisits table are unused. While Shark’s in-memory tables are also columnar, it is bottlenecked here on the speed at which it evaluates the SUBSTR expression. Since Impala is reading from the OS buffer cache, it must read and decompress entire rows. Unlike Shark, however, Impala evaluates this expression using very efficient compiled code. These two factors offset each other and Impala and Shark achieve roughly the same raw throughput for in-memory tables. For larger result sets, Impala again sees high latency due to the speed of materializing output tables.
Joins
This test involves merging10 a large table with a smaller one. Focusing on results for the largest data set (Query 3C), Redshift is 3x faster than Shark (on-disk) and 2x faster than Impala (on-disk).
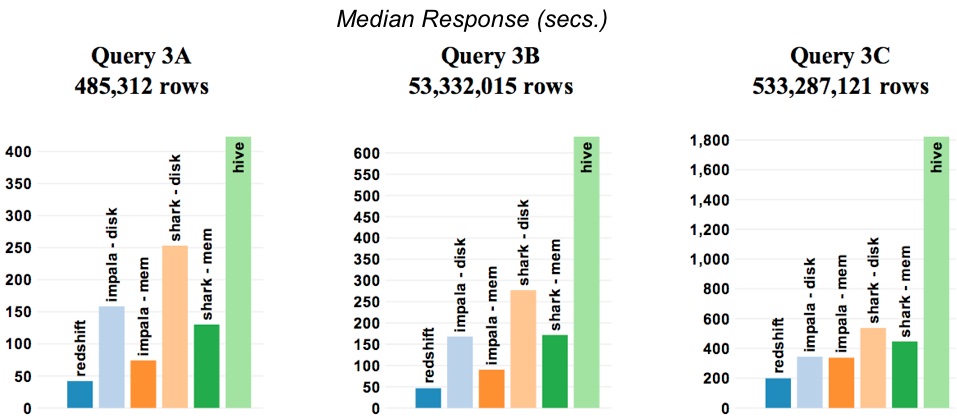
When the join is small (3A), all frameworks spend the majority of time scanning the large table and performing date comparisons. For larger joins, the initial scan becomes a less significant fraction of overall response time. For this reason the gap between in-memory and on-disk representations diminishes in query 3C. All frameworks perform partitioned joins to answer this query. CPU (due to hashing join keys) and network IO (due to shuffling data) are the primary bottlenecks. Redshift has an edge in this case because the overall network capacity in the cluster is higher.
Related posts:
(1) Airbnb has been using Redshift since early this year.
(2) Including some for interactive SQL analysis, machine-learning, streaming, and graphs.
(3) The recent focus on Hadoop query engines varies from company to company. Here’s an excerpt from a recent interview with Hortonworks CEO Robb Bearden: Bearden’s take is that real time processing is many years away if ever. “I’d emphasize ‘if ever,'” he said. “We don’t view Hadoop being storage, processing of unstructured data and real time.” Other companies behind distributions, notably Cloudera, see real-time processing as important. “Why recreate the wheel,” asks Bearden. Although trying to upend the likes of IBM, Teradata, Oracle and other data warehousing players may be interesting, it’s unlikely that a small fry could compete. “I’d rather have my distro adopted and integrated seamlessly into their environment,” said Bearden.
(4) A recent paper describes PolyBase in detail. Also see Hadapt co-founder, Daniel Abadi’s description of how PolyBase and Hadapt differ. (Update, 6/6/2013: Dave Dewitt of Microsoft Research, on the design of PolyBase.)
(5) To thoroughly compare different systems, a generic benchmark such as the one just released, won’t suffice. Users still need to load their own data and simulate their workloads.
(6) If their terms-of-service allow for inclusion into benchmarks.
(7) Versions used: Shark (v0.8 preview, 5/2013); Impala (v1.0, 4/2013); Hive (v0.10, 1/2013)
(8) Being close to MPP database speed is consistent with previous tests conducted by the Shark team.
(9) As I noted in a recent tweet and post: the keys to the BDAS stack are the use of memory (instead of disk), the use of recomputation (instead of replication) to achieve fault-tolerance, data co-partitioning, and in the case of Shark, the use of column stores.
(10) The query involves a subquery in the FROM clause.
{kind=link}
 O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
Strata Rx Health Data Conference: September 25-27 | Boston, MA
Strata + Hadoop World: October 28-30 | New York, NY
Strata in London: November 15-17 | London, England