Andy Oram
 Andy Oram is an editor at O'Reilly Media. An employee of the company since 1992, Andy currently specializes in open source technologies and software engineering. His work for O'Reilly includes the first books ever released by a U.S. publisher on Linux, the 2001 title Peer-to-Peer, and the 2007 best-seller Beautiful Code.
Andy Oram is an editor at O'Reilly Media. An employee of the company since 1992, Andy currently specializes in open source technologies and software engineering. His work for O'Reilly includes the first books ever released by a U.S. publisher on Linux, the 2001 title Peer-to-Peer, and the 2007 best-seller Beautiful Code.
New Swift language shows Apple history
Still reflects conventions going back to original adoption of Objective-C
 Like many Apple programmers (and new programmers who are curious about iOS), I treated Apple’s Swift language as a breath of fresh air. I welcomed when Vandad Nahavandipoor updated his persistently popular iOS Programming Cookbook to cover Swift exclusively. But I soon realized that the LLVM compiler and iOS runtime have persistent attributes of their own that have not gone away when programmers adopt Swift. This post tries to alert new iOS programmers to the idiosyncrasies of the runtime that they still need to learn.
Like many Apple programmers (and new programmers who are curious about iOS), I treated Apple’s Swift language as a breath of fresh air. I welcomed when Vandad Nahavandipoor updated his persistently popular iOS Programming Cookbook to cover Swift exclusively. But I soon realized that the LLVM compiler and iOS runtime have persistent attributes of their own that have not gone away when programmers adopt Swift. This post tries to alert new iOS programmers to the idiosyncrasies of the runtime that they still need to learn.
How Flash changes the design of database storage engines
High-performing memory throws many traditional decisions overboard

Over the past decade, SSD drives (popularly known as Flash) have radically changed computing at both the consumer level — where USB sticks have effectively replaced CDs for transporting files — and the server level, where it offers a price/performance ratio radically different from both RAM and disk drives. But databases have just started to catch up during the past few years. Most still depend on internal data structures and storage management fine-tuned for spinning disks.
Citing price and performance, one author advised a wide range of database vendors to move to Flash. Certainly, a database administrator can speed up old databases just by swapping out disk drives and inserting Flash, but doing so captures just a sliver of the potential performance improvement promised by Flash. For this article, I asked several database experts — including representatives of Aerospike, Cassandra, FoundationDB, RethinkDB, and Tokutek — how Flash changes the design of storage engines for databases. The various ways these companies have responded to its promise in their database designs are instructive to readers designing applications and looking for the best storage solutions.
Does net neutrality really matter?
Competition, access to bandwidth, and other issues muddy the net neutrality waters.

Screen shot of signatures from a “Common Carrier” petition to the White House.
It was the million comments filed at the FCC that dragged me out of the silence I’ve maintained for several years on the slippery controversy known as “network neutrality.” The issue even came up during President Obama’s address to the recent U.S.-Africa Business forum.
Most people who latch on to the term “network neutrality” (which was never favored by the experts I’ve worked with over the years to promote competitive Internet service) don’t know the history that brought the Internet to its current state. Without this background, proposed policy changes will be ineffective. So, I’ll try to fill in some pieces that help explain the complex cans of worms opened by the idea of network neutrality.
Read more…
Smarter buildings through data tracking
Buildings are ready to be smart — we just need to collect and monitor the data.
Buildings, like people, can benefit from lessons built up over time. Just as Amazon.com recommends books based on purchasing patterns or doctors recommend behavior change based on what they’ve learned by tracking thousands of people, a service such as Clockworks from KGS Buildings can figure out that a boiler is about to fail based on patterns built up through decades of data.
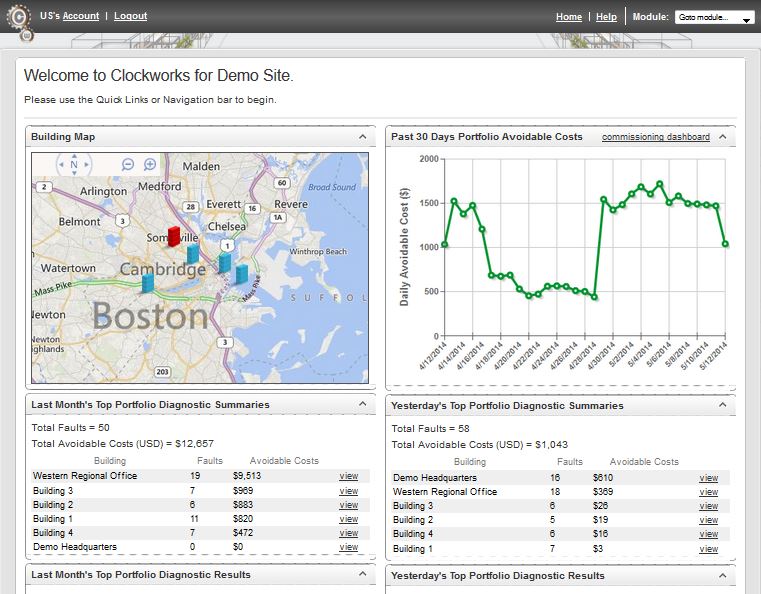
Screen shot from KGS Clockworks analytics tool
I had the chance to be enlightened about intelligent buildings through a conversation with Nicholas Gayeski, cofounder of KGS Buildings, and Mark Pacelle, an engineer with experience in building controls who has written for O’Reilly about the Internet of Things. Read more…
Health games platforms mature in preparation for mainstream adoption
Business models and sustainability will drive success in the health games space.

SPARX, a behavioral therapy game for youths,
combines a fantasy setting with skills for life.
These efforts have born fruit, and clinical trials have shown the value of many such games. Ben Sawyer, who founded the Games for Health conference more than 10 years ago, is watching all the pieces fall into place for the widespread adoption of games. Business plans, platforms, and the general environment for the acceptance of games (and other health-related apps) are coming together.
Graph tools forge path to new solutions
Find emergent properties and solutions to new computing problems with graphs
 Graph databases haven’t made the news much because, I think, they don’t fit in convenient categories. They certainly aren’t the relational databases we’re all familiar with, nor are they the arbitrary keys and values provided by many NoSQL stores. But in a highly connected world–where it’s not what you know but whom you know–it makes intuitive sense to arrange our knowledge as nodes and edges.
Graph databases haven’t made the news much because, I think, they don’t fit in convenient categories. They certainly aren’t the relational databases we’re all familiar with, nor are they the arbitrary keys and values provided by many NoSQL stores. But in a highly connected world–where it’s not what you know but whom you know–it makes intuitive sense to arrange our knowledge as nodes and edges.
Ted Nelson, inventor of the hyperlink, recognized the power of viewing life in graphs. After the implosion of his historic Xanadu project, he embarked on a graph database tool called ZigZag. The most modern instantiations of graphs–the Neo4j store and the Alchemy.js tool for interactively visualizing graphs–were well represented this year at O’Reilly’s Open Source convention.
OpenStack creates a structure for managing change without a benevolent dictator
Can education and peer review keep a huge open source project on track?
When does a software project grow to the point where one must explicitly think about governance? The term “governance” is stiff and gawky, but doing it well can carry a project through many a storm. Over the past couple years, the crucial OpenStack project has struggled with governance at least as much as with the technical and organizational issues of coordinating inputs from thousands of individuals and many companies.
A major milestone was the creation of the OpenStack Foundation, which I reported on in 2011. This event successfully started the participants’ engagement with the governance question, but it by no means resolved it. This past Monday, I attended some of the Open Cloud Day at O’Reilly’s Open Source convention, and talked to a lot of people working for or alongside the OpenStack Foundation about getting contributors to work together successfully in an open community. Read more…
Jeremy Rifkin unveils a return to the local in an interconnected future
Internet of Things, local energy sources, and online collaboration underlie the Zero Marginal Cost Society.

Stratasys’ Education, R&D departments and MIT’s Self-Assembly Lab are researching 4D printing — manufacturing one-off objects that can change their shapes or other physical characteristics in response to their environment. (View the video.)
Read more…
Online communities could benefit from the power of offline meetings
Face-to-face engagement can cement relationships and build depth in online communities.
As software vendors, open source projects, and companies in all fields rush to gather communities around themselves, I’m bothered that we haven’t spent much time studying the lessons face-to-face communities have forged over decades of intensive work by a dynamic community organizing movement. I have spoken twice at the Community Leadership Summit (CLS) about the tradition of community organizing as practiced by the classic social action group, Saul Alinsky’s Industrial Areas Foundation. Because we all understand that a community is people — not software, not meeting places, not rules or norms — it’s worth looking at how face-to-face communities flourish.

Storytelling and urban organizing session at CLS
Last week’s CLS event had several talks and sessions about face-to-face organizing, which the attendees liked to call offline meetings because we assume so much interaction between groups takes place nowadays on the Internet. As one can find at CLS, a passionate confluence and sharing among dedicated “people people,” there’s a great deal of power in offline meetings. An evening at a bar — or an alternative location for those who are uncomfortable in bars — can cement relationships and provide depth to the formal parts of the day. Read more…
Where did the issue of health data exchange disappear to?
More visible at Health Privacy Summit than Health Datapalooza.
On the first morning of the biggest conference on data in health care–the Health Datapalooza in Washington, DC–newspapers reported a bill allowing the Department of Veterans Affairs to outsource more of its care, sending veterans to private health care providers to relieve its burdensome shortage of doctors.
There has been extensive talk about the scandals at the VA and remedies for them, including the political and financial ramifications of partial privatization. Republicans have suggested it for some time, but for the solution to be picked up by socialist Independent Senator Bernie Sanders clinches the matter. What no one has pointed out yet, however–and what makes this development relevant to the Datapalooza–is that such a reform will make the free flow of patient information between providers more crucial than ever.