- Aaron’s Army — powerful words from Carl Malamud. Aaron was part of an army of citizens that believes democracy only works when the citizenry are informed, when we know about our rights—and our obligations. An army that believes we must make justice and knowledge available to all—not just the well born or those that have grabbed the reigns of power—so that we may govern ourselves more wisely.
- Vaurien the Chaos TCP Monkey — a project at Netflix to enhance the infrastructure tolerance. The Chaos Monkey will randomly shut down some servers or block some network connections, and the system is supposed to survive to these events. It’s a way to verify the high availability and tolerance of the system. (via Pete Warden)
- Foto Forensics — tool which uses image processing algorithms to help you identify doctoring in images. The creator’s deconstruction of Victoria’s Secret catalogue model photos is impressive. (via Nelson Minar)
- All Trials Registered — Ben Goldacre steps up his campaign to ensure trial data is reported and used accurately. I’m astonished that there are people who would withhold data, obfuscate results, or opt out of the system entirely, let alone that those people would vigorously assert that they are, in fact, professional scientists.
"open data" entries

Four short links: 28 January 2013
Informed Citizenry, TCP Chaos Monkey, Photographic Forensics, Medical Trial Data

Making open data more valuable, one micropayment at a time
Yo Yoshida's startup, Appallicious, is using San Francisco's government data as a backbone.
When it comes to making sense of the open data economy, tracking cents is valuable. In San Francisco, where Mayor Ed Lee’s administration has reinvigorated city efforts to release open data for economic benefits, entrepreneur Yo Yoshida has made the City by the Bay’s government data central to his mobile ecommerce startup, Appallicious.
Appallicious is positioning its Skipitt mobile platform as a way for cities to easily process mobile transactions for their residents. The startup is generating revenue from each transaction the city takes with its platform using micropayments, a strategy that’s novel in the world of open data but has enabled Appallicious to make enough money to hire more employees and look to expand to other municipalities. I spoke to Yoshida last fall about his startup, what it’s like to go through city procurement, and whether he sees a market opportunity in more open government data.
Where did the idea for Appallicious come from?
Yo Yoshida: About three years ago, I was working on another platform with a friend that I met years ago, working on a company called Beaker. We discovered a number of problems. One of them was being able to find our way around San Francisco and not only get information, but be able to transact with different services and facilities, including going to a football game at the 49ers stadium. Why couldn’t we order a beer to our seats or order merchandise? Or find the food trucks that were sitting in some of the parks and then place an order from that?
So we were looking at what solutions were out there via mobile. We started exploring how to go about doing this. We looked first at the vendors and approaching them. That’s been done with a lot of other specific verticals. We started talking to the city a little bit. We looked at the open data legislation that was coming out at that time and said, “This is the information we need, but now we also need to be able to figure out how to monetize and populate that.” Read more…
U.S. House makes legislative data more open to the people in XML
Opening data in Congress is a marathon, not a sprint. The 113th Congress is making notable, incremental progress on open government.
It was a good week for open government data in the United States Congress. On Tuesday, the Clerk of the House made House floor summaries available in bulk XML format. Yesterday, the House of Representatives announced that it will make all of its legislation available for bulk download in a machine-readable format, XML, in cooperation with the U.S. Government Printing Office. As Nick Judd observes at TechPresident, such data is catnip for developers. While full bulk data from THOMAS.gov is still not available, this incremental progress deserves mention.
14 big trends to watch in 2013
From sensor journalism to lean government to preemptive health care, 2013 will be interesting.
2012 was a remarkable year for technology, government and society. In my 2012 year in review, I looked back at 10 trends that mattered. Below, I look ahead to the big ideas and technologies that will change the world, again. Read more…
Big, open and more networked than ever: 10 trends from 2012
Social media, open source in government, open mapping and other trends that mattered this year.
In 2012, technology-accelerated change around the world was accelerated by the wave of social media, data and mobile devices. In this year in review, I look back at some of the stories that mattered here at Radar and look ahead to what’s in store for 2013.
Below, you’ll find 10 trends that held my interest in 2012. This is by no means a comprehensive account of “everything that mattered in the past year” — try The Economist’s account of the world in 2012 or The Atlantic’s 2012 in review or Popular Science’s “year in ideas” if you’re hungry for that perspective — but I hope you’ll find something new to think about as 2013 draws near. Read more…
Making dollars and sense of the open data economy
Is the push to free up government data resulting in economic activity and startup creation?
 Over the past several years, I’ve been writing about how government data is moving into the marketplaces, underpinning ideas, products and services. Open government data and application programming interfaces to distribute it, more commonly known as APIs, increasingly look like fundamental public infrastructure for digital government in the 21st century.
Over the past several years, I’ve been writing about how government data is moving into the marketplaces, underpinning ideas, products and services. Open government data and application programming interfaces to distribute it, more commonly known as APIs, increasingly look like fundamental public infrastructure for digital government in the 21st century.
What I’m looking for now is more examples of startups and businesses that have been created using open data or that would not be able to continue operations without it. If big data is a strategic resource, it’s important to understand how and where organizations are using it for public good, civic utility and economic benefit.
Sometimes government data has been proactively released, like the federal government’s work to revolutionize the health care industry by making health data as useful as weather data or New York City’s approach to becoming a data platform.
In other cases, startups like Panjiva or BrightScope have liberated government data through Freedom of Information Act requests and automated means. By doing so, they’ve helped the American people and global customers understand the supply chain, the fees associated with 401(k) plans and the history of financial advisors.
I’ve hypothesized that open data will have an overall effect on the economy akin to that of open source and small business. Gartner’s research has posited that open data creates value in the public and private sector. If government acts as a platform to enable people inside and outside government to innovate on top of it, what are the outcomes? Read more…
Panjiva uses government data to build a global search engine for commerce
Successful startups look to solve a problem first, then look for the datasets they need.
“If you go back to how we got started,” mused Josh Green, “government data really is at the heart of that story.” Green, who co-founded Panjiva with Jim Psota in 2006, was demonstrating the newest version of Panjiva.com to me over the web, thinking back to the startup’s origins in Cambridge, Mass.
 At first blush, the search engine for products, suppliers and shipping services didn’t have a clear connection to the open data movement I’d been chronicling over the past several years. His account of the back story of the startup is a case study that aspiring civic entrepreneurs, Congress and the White House should take to heart.
At first blush, the search engine for products, suppliers and shipping services didn’t have a clear connection to the open data movement I’d been chronicling over the past several years. His account of the back story of the startup is a case study that aspiring civic entrepreneurs, Congress and the White House should take to heart.
“I think there are a lot of entrepreneurs who start with datasets,” said Green, “but it’s hard to start with datasets and build business. You’re better off starting with a problem that needs to be solved and then going hunting for the data that will solve it. That’s the experience I had.”
The problem that the founders of Panjiva wanted to help address was one that many other entrepreneurs face: how do you connect with companies in far away places? Green came to the realization that a better solution was needed in the same way that many people who come up with an innovative idea do: he had a frustrating experience and wanted to scratch his own itch. When he was working at an electronics company earlier in his career, his boss asked him to find a supplier they could do business with in China.
“I thought I could do that, but I was stunned by the lack of reliable information,” said Green. “At that moment, I realized we were talking about a problem that should be solvable. At a time when people are interested in doing business globally, there should be reliable sources of information. So, let’s build that.”
Today, Panjiva has created a higher tech way to find overseas suppliers. The way they built it, however, deserves more attention.
The United States (Code) is on Github
Open government coders collaborate to liberate legislative data from Congress.
When Congress launched Congress.gov in beta, they didn’t open the data. This fall, a trio of open government developers took it upon themselves to do what custodians of the U.S. Code and laws in the Library of Congress could have done years ago: published data and scrapers for legislation in Congress from THOMAS.gov in the public domain. The data at github.com/unitedstates is published using an “unlicense” and updated nightly. Credit for releasing this data to the public goes to Sunlight Foundation developer Eric Mill, GovTrack.us founder Josh Tauberer and New York Times developer Derek Willis.
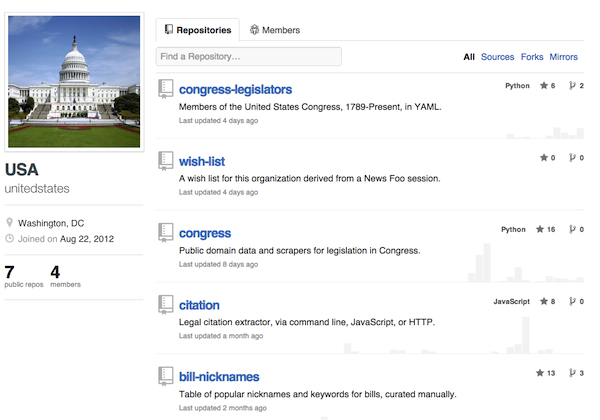
“It would be fantastic if the relevant bodies published this data themselves and made these datasets and scrapers unnecessary,” said Mill, in an email interview. “It would increase the information’s accuracy and timeliness, and probably its breadth. It would certainly save us a lot of work! Until that time, I hope that our approach to this data, based on the joint experience of developers who have each worked with it for years, can model to government what developers who aim to serve the public are actually looking for online.”
If the People’s House is going to become a platform for the people, it will need to release its data to the people. If Congressional leaders want THOMAS.gov to be a platform for members of Congress, legislative staff, civic developers and media, the Library of Congress will need to release structured legislative data. THOMAS is also not updated in real-time, which means that there will continue to be a lag between a bill’s introduction and the nation’s ability to read the bill before a vote. Read more…
Investigating data journalism
Scraping together the best tools, techniques and tactics of the data journalism trade.
Great journalism has always been based on adding context, clarity and compelling storytelling to facts. While the tools have improved, the art is the same: explaining the who, what, where, when and why behind the story. The explosion of data, however, provides new opportunities to think about reporting, analysis and publishing stories.
As you may know, there’s already a Data Journalism Handbook to help journalists get started. (I contributed some commentary to it). Over the next month, I’m going to be investigating the best data journalism tools currently in use and the data-driven business models that are working for news startups. We’ll then publish a report that shares those insights and combines them with our profiles of data journalists.
Why dig deeper? Getting to the heart of what’s hype and what’s actually new and noteworthy is worth doing. I’d like to know, for instance, whether tutorials specifically designed for journalists can be useful, as Joe Brockmeier suggested at ReadWrite. On a broader scale, how many data journalists are working today? How many will be needed? What are the primary tools they rely upon now? What will they need in 2013? Who are the leaders or primary drivers in the area? What are the most notable projects? What organizations are embracing data journalism, and why?
This isn’t a new interest for me, but it’s one I’d like to found in more research. When I was offered an opportunity to give a talk at the second International Open Government Data Conference at the World Bank this July, I chose to talk about open data journalism and invited practitioners on stage to share what they do. If you watch the talk and the ensuing discussion in the video below, you’ll pick up great insight from the work of the Sunlight Foundation, the experience of Homicide Watch and why the World Bank is focused on open data journalism in developing countries.
Four short links: 5 November 2012
Psychology in a Nutshell, IRS Data, Fulltime Drone CEO, and SQL Injection
- The Psychology of Everything (YouTube) — illustrating some of the most fundamental elements of human nature through case studies about compassion, racism, and sex. (via Mind Hacks)
- Reports of Exempt Organizations (Public Resource) — This service provides bulk access to 6,461,326 filings of exempt organizations to the Internal Revenue Service. Each month, we process DVDs from the IRS for Private Foundations (Type PF), Exempt Organizations (Type EO), and filings by both of those kinds of organizations detailing unrelated business income (Type T). The IRS should be making this publicly available on the Internet, but instead it has fallen to Carl Malamud to make it happen. (via BoingBoing)
- Chris Anderson Leaves for Drone Co (Venturebeat) — Editor-in-chief of Wired leaves to run his UAV/robotics company 3D Robotics.
- pysqli (GitHub) — Python SQL injection framework; it provides dedicated bricks that can be used to build advanced exploits or easily extended/improved to fit the case.