- The Transformation of the Workplace Through Robotics, Artificial Intelligence, and Automation — fascinating legal questions about the rise of the automated workforce. . Is an employer required to bargain if it wishes to acquire robots to do work previously performed by unionized employees working under a collective bargaining agreement? does the collective bargaining agreement control the use of robots to perform this work? A unionized employer seeking to add robots to its business process must consider these questions. (via Robotenomics)
- The Invasive Valley of Personalization (Maria Anderson) — there is a fine line between useful personalization and creepy personalization. It reminded me of the “uncanny valley” in human robotics. So I plotted the same kind of curves on two axes: Access to Data as the horizontal axis, and Perceived Helpfulness on the vertical axis. For technology to get vast access to data AND make it past the invasive valley, it would have to be perceived as very high on the perceived helpfulness scale.
- Coffee and Feature Creep — fantastic story of how a chat system became a bank. (via BoingBoing)
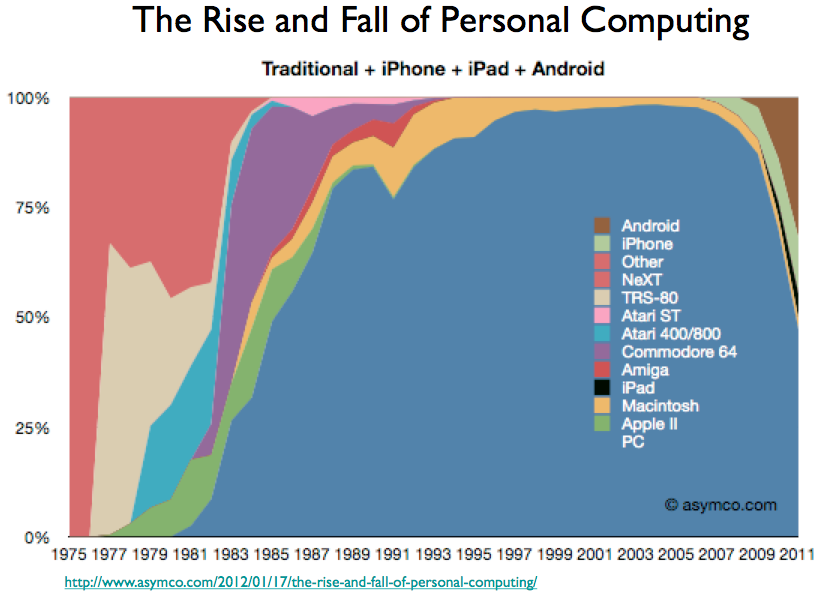
- The Rise and Fall of PCs — use this slide of market share over time by device whenever you need to talk about the “post-PC age”. (via dataisugly subreddit)
"personalization" entries

What happens when fashion meets data: The O’Reilly Radar Podcast
Liza Kindred on the evolving role of data in fashion and the growing relationship between tech and fashion companies.
Editor’s note: you can subscribe to the O’Reilly Radar Podcast through iTunes, SoundCloud, or directly through our podcast’s RSS feed.
In this podcast episode, I talk with Liza Kindred, founder of Third Wave Fashion and author of the new free report “Fashioning Data: How fashion industry leaders innovate with data and what you can learn from what they know.” Kindred addresses the evolving role data and analytics are playing in the fashion industry, and the emerging connections between technology and fashion companies. “One of the things that fashion is doing better than maybe any other industry,” Kindred says, “is facilitating conversations with users.”
Gathering and analyzing user data creates opportunities for the fashion and tech industries alike. One example of this is the trend toward customization. Read more…

Four short links: 19 March 2014
Legal Automata, Invasive Valley, Feature Creep, and Device Market Share
{kind=link}

Data is the real business model for social
IBM's Marie Wallace on the unrealized potential of social data.
As social media websites gather ever-growing data stores, they might be better served by finding ways to make profitable use of that data instead serving ads as their chief means of raising revenue. While the data might give them the information they need to serve more targeted ads — although in my experience they still have a ways to go with that — the real value in the site could be the data itself.
Of course, if social sites start selling data to the highest bidder that leaves open questions of data ownership and privacy and finding ways to strip personal identifiers.
Marie Wallace (@marie_wallace) is social analytics strategist for the IBM Collaboration Solutions division. She has spent more than a decade at IBM working on content analytics, and her experience uniquely positions her to address questions regarding big data, social media and analytics. Our interview follows.
Social media’s real value might not be in selling ads, but in the data they are collecting. Why do you think that is?
 Marie Wallace: The reason ad targeting has worked so well for search is because it’s aligned and supportive to that particular activity; when I am searching for information about products or services I am happy to get ads that may help direct my search. Ads are somewhat analogous to a value-added service and social search makes the ads more personalized and relevant, which is why Google has invested so heavily in Google+.
Marie Wallace: The reason ad targeting has worked so well for search is because it’s aligned and supportive to that particular activity; when I am searching for information about products or services I am happy to get ads that may help direct my search. Ads are somewhat analogous to a value-added service and social search makes the ads more personalized and relevant, which is why Google has invested so heavily in Google+.
The key is that in most cases ads only work in a search-like context, however with most social media sites people are not going there to search. They are going to converse with friends and family, which makes ads interruptive and frequently invasive. This is further exacerbated by mobile, where limited real estate makes ads even more offensive as they are distracting and clutter the screen. Social search is one example of a service that sits on top of social data, but there are a whole plethora of other services that social data can drive — from market research to consumer/brand engagement, social recommenders, information filtering, or expertise location. Read more…

Big data is our generation’s civil rights issue, and we don’t know it
What the data is must be linked to how it can be used.
Data doesn’t invade people’s lives. Lack of control over how it’s used does.
What’s really driving so-called big data isn’t the volume of information. It turns out big data doesn’t have to be all that big. Rather, it’s about a reconsideration of the fundamental economics of analyzing data.
For decades, there’s been a fundamental tension between three attributes of databases. You can have the data fast; you can have it big; or you can have it varied. The catch is, you can’t have all three at once.

I’d first heard this as the “three V’s of data”: Volume, Variety, and Velocity. Traditionally, getting two was easy but getting three was very, very, very expensive.
The advent of clouds, platforms like Hadoop, and the inexorable march of Moore’s Law means that now, analyzing data is trivially inexpensive. And when things become so cheap that they’re practically free, big changes happen — just look at the advent of steam power, or the copying of digital music, or the rise of home printing. Abundance replaces scarcity, and we invent new business models.
In the old, data-is-scarce model, companies had to decide what to collect first, and then collect it. A traditional enterprise data warehouse might have tracked sales of widgets by color, region, and size. This act of deciding what to store and how to store it is called designing the schema, and in many ways, it’s the moment where someone decides what the data is about. It’s the instant of context.
That needs repeating:
You decide what data is about the moment you define its schema.

Dominant form of journalism foretold by Reynolds Journalism Institute
Why a new proposal for making the news business sustainable deserves attention.
A new paper from the Reynolds Journalism Institute deserves a look from anyone interested in publishing, social networking, or democratic discourse.

Search Notes: The high cost of search market share
Why being a default search provider matters, personalized Google News, Bin Laden and search spikes
In the latest Search Notes: Bing is going all out to claim more market share, Google News' personalization features could create an echo chamber, and Osama Bin Laden's death creates a search frenzy.
Search Notes: The future is mobile. And self-driving cars
Foursquare 3.0 and local search, Google's mobile search dominance, and awesome autonomous cars.
In the latest edition of Search Notes: How Foursquare 3.0 could shape personalization and local search, and a look at Google's mobile search dominance. Plus: self-driving cars, just because they're amazing.

Penguin 2.0 Mashes Up Essays and Short Texts
Penguin's new project — dubbed "Penguin 2.0" — incorporates elements of customization and remixing found in Web content. Jeff Gomez, Penguin's senior director of online consumer sales and marketing, discusses the program with the New York Observer: … in 2009 the company will introduce a program that allows customers to choose from a variety of short stories, essays, and…