- Is Parallel Programming Hard? And, If So, What Can You Do About It? — book by Paul E. McKenney, on single-machine multi-CPU parallel programming.
- Malignant Computation — The bitcoin mining network would work just as well if it had far less computation devoted to it. Bitcoins would be mined at exactly the same rate if 1/2 or 1/4 of the computational resources were devoted. This means that bitcoin has incentivized a tremendous amount of computational busy work.
- GDS Becomes Political (Computer Weekly) — She [Opposition MP] said that digital should not be about imposing a way of working on the public sector – Labour is not fond of the “digital by default” mantra – but about supporting public service delivery. […] “When this government decided upon the digitalisation of this [online job search] service they apparently did not take into account those with poor literacy skills, mental health issues or learning difficulties – who, as most people would have predicted, make up a higher-than-average proportion of the unemployed.”
- streamtools (Github) — a graphical toolkit for dealing with streams of data. Streamtools makes it easy to explore, analyse, modify and learn from streams of data. (via OpenNews)
"streams" entries

4 things to make your Java 8 code more dynamic
Anytime is a good time to refactor your code.

Java 8 has a few new features which should help you write more dynamic code. Of course one of the big features was the addition of a lambda syntax. But what about some of the other features that were added? Here are a couple of things that I tell people to do in order to make their code more dynamic and more functional.

Java 8 streams API and parallelism
Leveraging intermediate and terminal operators to process large collections.
In the last post in this series, we learned about functional interfaces and lambdas. In particular, we looked at the ITrade functional interface, and filtered a collection of trades to generate a specific value. Prior to the feature updates made available in Java 8, running bulky operations on collections at the same time was ineffective and often cumbersome. They were restricted from performing efficient parallel processing due to the inherent explicit iteration that was being used. There was no easy way of splitting a collection to apply a piece of functionality on individual elements that then ran on multi-core machine architectures — that is, until the addition of Java 8’s Streams API.

Four short links: 13 March 2014
Parallel Programming, Malignant Computation, Politicised GDS, and Data Stream Toolkit

Expanding options for mining streaming data
New tools make it easier for companies to process and mine streaming data sources
Stream processing was in the minds of a few people that I ran into over the past week. A combination of new systems, deployment tools, and enhancements to existing frameworks, are behind the recent chatter. Through a combination of simpler deployment tools, programming interfaces, and libraries, recently released tools make it easier for companies to process and mine streaming data sources.
Of the distributed stream processing systems that are part of the Hadoop ecosystem0, Storm is by far the most widely used (more on Storm below). I’ve written about Samza, a new framework from the team that developed Kafka (an extremely popular messaging system). Many companies who use Spark express interest in using Spark Streaming (many have already done so). Spark Streaming is distributed, fault-tolerant, stateful, and boosts programmer productivity (the same code used for batch processing can, with minor tweaks, be used for realtime computations). But it targets applications that are in the “second-scale latencies”. Both Spark Streaming and Samza have their share of adherents and I expect that they’ll both start gaining deployments in 2014.
Four short links: 30 October 2013
Offline Javascript, Android Coding, Stats Fails, and Stream Data
- Offline.js — Javascript library so web app developers can gracefully deal with users going offline.
- Android Guides — lots of info on coding for Android.
- Statistics Done Wrong — learn from these failure modes. Not medians or means. Modes.
- Streaming, Sketching, and Sufficient Statistics (YouTube) — how to process huge data sets as they stream past your CPU (e.g., those produced by sensors). (via Ben Lorica)
Stream Mining essentials
At the most basic level, stream mining is about generating summaries that can be used to answer fundamental questions
A series of open source, distributed stream processing frameworks have become essential components in many big data technology stacks. Apache Storm remains the most popular, but promising new tools like Spark Streaming and Apache Samza are going to have their share of users. These tools excel at data processing and are also used for data mining – in many cases users have to write a bit of code1 to do stream mining. The good news is that easy-to-use stream mining libraries will likely emerge in the near future.
High volume data streams (data that arrive continuously) arise in many settings, including IT operations, sensors, and social media. What can one learn by looking at data one piece (or a few pieces) at a time? Can techniques that look at smaller representations of data streams be used to unlock their value? In this post, I’ll briefly summarize a recent overview given by stream mining pioneer Graham Cormode.
Generate Summaries
Massive amounts of data arriving at high velocity pose a challenge to data miners. At the most basic level, stream mining is about generating summaries that can be used to answer fundamental questions:
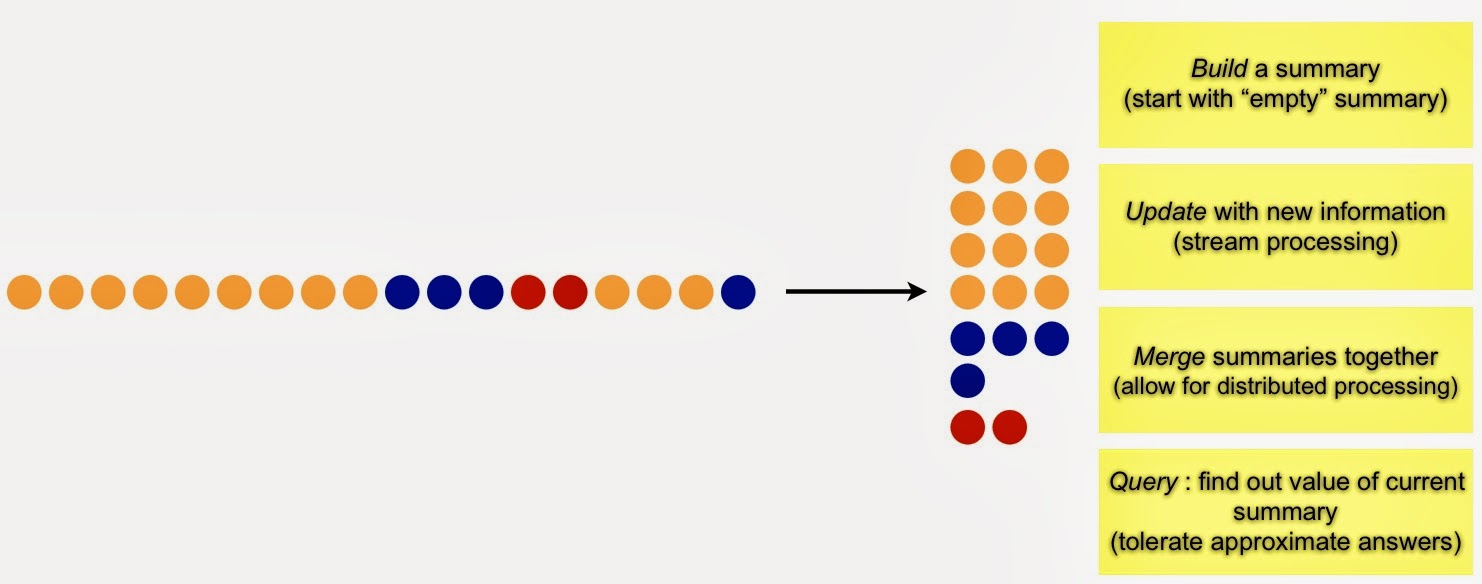
Properly constructed summaries are useful for highlighting emerging patterns, trends, and anomalies. Common summaries (frequency moments in stream mining parlance) include a list of distinct items, recently trending items, heavy hitters (items that have appeared frequently), and the top k (most popular) items.
Stream Processing and Mining just got more interesting
A general purpose stream processing framework from the team behind Kafka and new techniques for computing approximate quantiles
Largely unknown outside data engineering circles, Apache Kafka is one of the more popular open source, distributed computing projects. Many data engineers I speak with either already use it or are planning to do so. It is a distributed message broker used to store1 and send data streams. Kafka was developed by Linkedin were it remains a vital component of their Big Data ecosystem: many critical online and offline data flows rely on feeds supplied by Kafka servers.
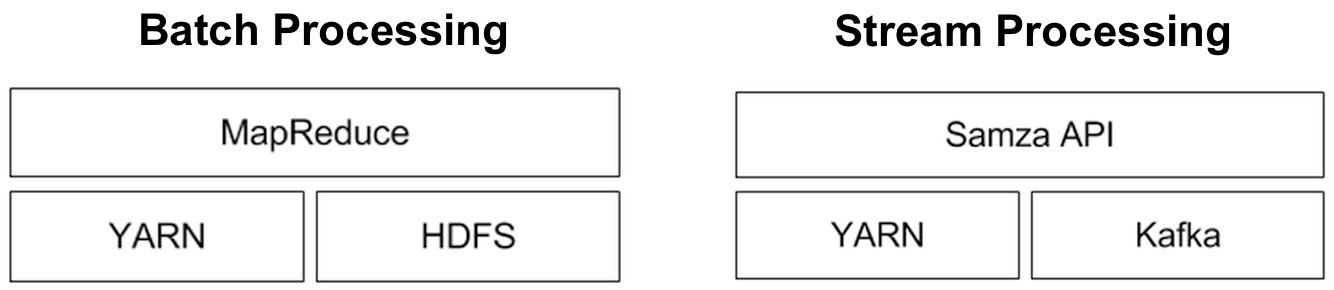
Apache Samza: a distributed stream processing framework
Behind Kafka’s success as an open source project is a team of savvy engineers who have spent2 the last three years making it a rock solid system. The developers behind Kafka realized early on that it was best to place the bulk of data processing (i.e., stream processing) in another system. Armed with specific use cases, work on Samza proceeded in earnest about a year ago. So while they examined existing streaming frameworks (such as Storm, S4, Spark Streaming), Linkedin engineers wanted a system that better fit their needs3 and requirements:
Near realtime, streaming, and perpetual analytics
Hadoop moves from batch to near realtime: next up, placing streaming data in context
Simple example of a near realtime app built with Hadoop and HBase
Over the past year Hadoop emerged from its batch processing roots and began to take on interactive and near realtime applications. There are numerous examples that fall under these categories, but one that caught my eye recently is a system jointly developed by China Mobile Guangdong (CMG) and Intel1. It’s an online system that lets CMG’s over 100 million subscribers2 access and pay their bills, and examine their CDR’s (call detail records) in near realtime.
A service for providing detailed billing information is an important customer touch point. Repeated/extended downtimes and data errors could seriously tarnish CMG’s image. CMG needed a system that could scale to their current (and future) data volumes, while providing the low-latency responses consumers have come to expect from online services. Scalability, price and open source3 were important criteria in persuading the company to choose a Hadoop-based solution over4 MPP data warehouses.
In the system it co-developed with Intel, CMG stores detailed subscriber billing records in HBase. This amounts to roughly 30 TB/month, but since the service lets users browse up to six months of billing data it provides near realtime query results on much larger amounts of data. There are other near realtime applications built from Hadoop components (notably the continuous compute system at Yahoo!), that handle much larger data sets. But what I like about the CMG example is that it’s an application that most people understand right away (a detailed billing lookup system), and it illustrates that the Hadoop ecosystem has grown beyond batch processing.
Besides powering their online billing lookup service, CMG uses its Hadoop platform for analytics. Data from multiple sources (including phone device preferences, usage patterns, and cell tower performance) are used to compute customer segments and targeted promotions. Over time, Hadoop’s ability to handle large amounts of unstructured data opens up other data sources that can potentially improve CMG’s current analytic models.
Contextualize: Streaming and Perpetual Analytics
This leads me to something “realtime” systems are beginning to do: placing streaming data in context. Streaming analytics operates over fixed time windows and is used to identify “top k” trending items, heavy-hitters, and distinct items. Perpetual analytics takes what you’re observing now and places it in the context of what you already know. As much as companies appreciate metrics produced by streaming engines, they also want to understand how “realtime observations” affect their existing knowledge base.
Pattern-detection and Twitter’s Streaming API
In some key use cases a random sample of tweets can capture important patterns and trends
Researchers and companies who need social media data frequently turn to Twitter’s API to access a random sample of tweets. Those who can afford to pay (or have been granted access) use the more comprehensive feed (the firehose) available through a group of certified data resellers. Does the random sample of tweets allow you to capture important patterns and trends? I recently came across two papers that shed light on this question.
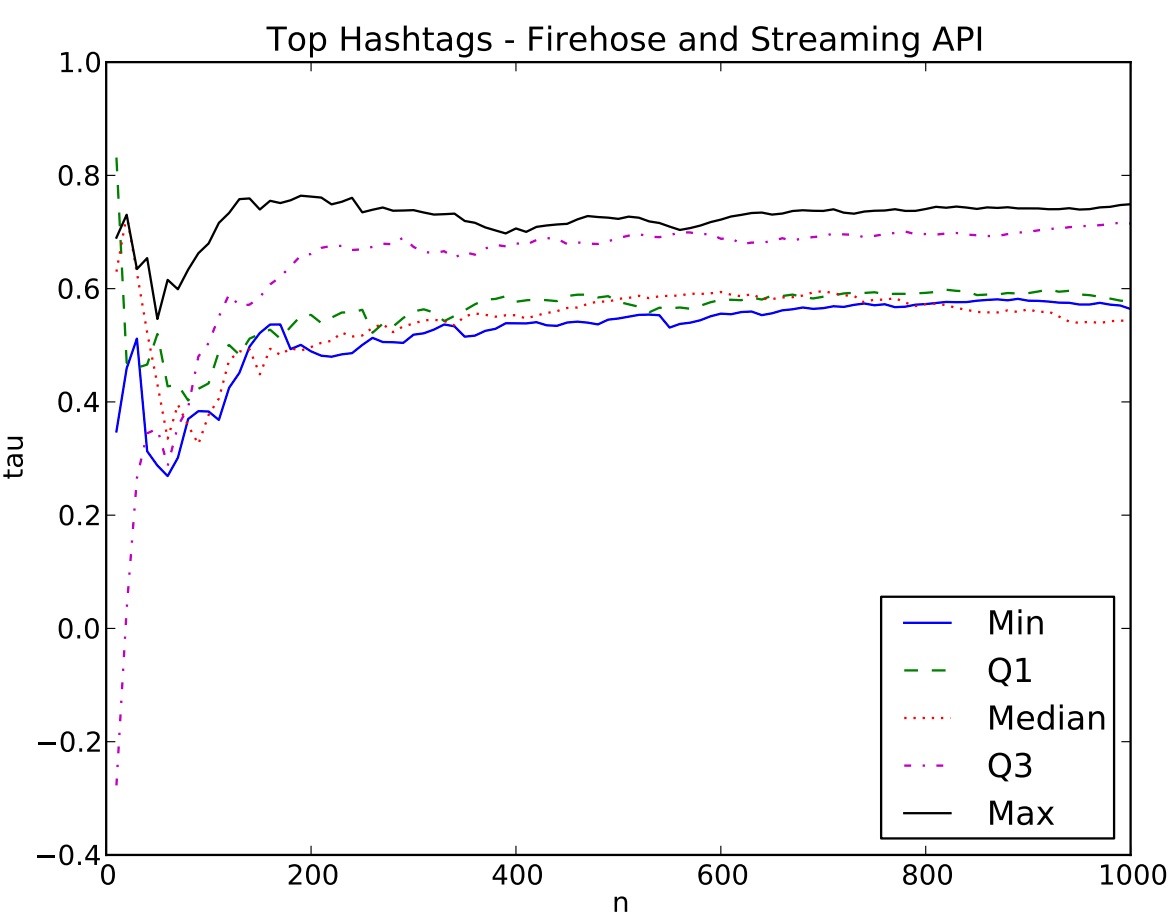
Systematic comparison of the Streaming API and the Firehose
A recent paper from ASU and CMU compared data from the streaming API and the firehose, and found mixed results. Let me highlight two cases addressed in the paper: identifying popular hashtags and influential users.
Of interest to many users is the list of top hashtags. Can one identify the “top n” hastags using data made available throughthe streaming API? The graph below is a comparison of the streaming API to the firehose: n (as in “top n” hashtags) vs. correlation (Kendall’s Tau). The researchers found that the streaming API provides a good list of hashtags when n is large, but is misleading for small n.
Scalable streaming analytics using a single-server
The simplest and quickest way to mine your data is to deploy efficient algorithms designed to answer key questions at scale.
For many organizations real-time1 analytics entails complex event processing systems (CEP) or newer distributed stream processing frameworks like Storm, S4, or Spark Streaming. The latter have become more popular because they are able to process massive amounts of data, and fit nicely with Hadoop and other cluster computing tools. For these distributed frameworks peak volume is function of network topology/bandwidth and the throughput of the individual nodes.
Scaling up machine-learning: Find efficient algorithms
Faced with having to crunch through a massive data set, the first thing a machine-learning expert will try to do is devise a more efficient algorithm. Some popular approaches involve sampling, online learning, and caching. Parallelizing an algorithm tends to be lower on the list of things to try. The key reason is that while there are algorithms that are embarrassingly parallel (e.g., naive bayes), many others are harder to decouple. But as I highlighted in a recent post, efficient tools that run on single servers can tackle large data sets. In the machine-learning context recent examples2 of efficient algorithms that scale to large data sets, can be found in the products of startup SkyTree.