"Big Data Tools and Pipelines" entries

Building and deploying large-scale machine learning pipelines
We need primitives; pipeline synthesis tools; and most importantly, error analysis and verification.
Register for Hardcore Data Science Day at Strata + Hadoop World NYC 2015, which takes place September 29 to October 1.
There are many algorithms with implementations that scale to large data sets (this list includes matrix factorization, SVM, logistic regression, LASSO, and many others). In fact, machine learning experts are fond of pointing out: if you can pose your problem as a simple optimization problem then you’re almost done.
Of course, in practice, most machine learning projects can’t be reduced to simple optimization problems. Data scientists have to manage and maintain complex data projects, and the analytic problems they need to tackle usually involve specialized machine learning pipelines. Decisions at one stage affect things that happen downstream, so interactions between parts of a pipeline are an area of active research.
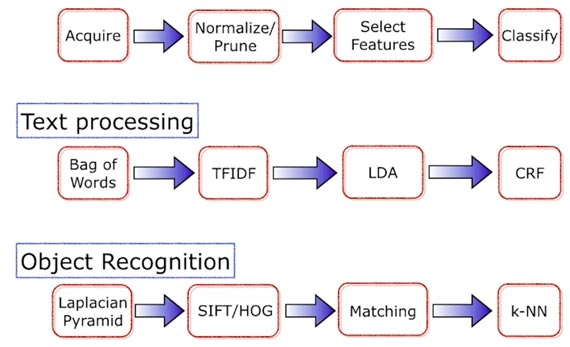
Some common machine learning pipelines. Source: Ben Recht, used with permission.
In his 2014 Strata + Hadoop World New York presentation, UC Berkeley professor Ben Recht described new UC Berkeley AMPLab projects for building and managing large-scale machine learning pipelines. Given AMPLab’s ties to the Spark community, some of the ideas from their projects are starting to appear in Apache Spark. Read more…
Lessons from next-generation data wrangling tools
Drawing inspiration from recent advances in data preparation.

One of the trends we’re following is the rise of applications that combine big data, algorithms, and efficient user interfaces. As I noted in an earlier post, our interest stems from both consumer apps as well as tools that democratize data analysis. It’s no surprise that one of the areas where “cognitive augmentation” is playing out is in data preparation and curation. Data scientists continue to spend a lot of their time on data wrangling, and the increasing number of (public and internal) data sources paves the way for tools that can increase productivity in this critical area.
At Strata + Hadoop World New York, NY, two presentations from academic spinoff start-ups — Mike Stonebraker of Tamr and Joe Hellerstein and Sean Kandel of Trifacta — focused on data preparation and curation. While data wrangling is just one component of a data science pipeline, and granted we’re still in the early days of productivity tools in data science, some of the lessons these companies have learned extend beyond data preparation.
Scalability ~ data variety and size
Not only are enterprises faced with many data stores and spreadsheets, data scientists have many more (public and internal) data sources they want to incorporate. The absence of a global data model means integrating data silos, and data sources requires tools for consolidating schemas.
Random samples are great for working through the initial phases, particularly while you’re still familiarizing yourself with a new data set. Trifacta lets users work with samples while they’re developing data wrangling “scripts” that can be used on full data sets.
Read more…
Apache Spark’s journey from academia to industry
In this O'Reilly Data Show Podcast: Ion Stoica talks about the rise of Apache Spark and Apache Mesos.
Three projects from UC Berkeley’s AMPLab have been keenly adopted by industry: Apache Mesos, Apache Spark, and Tachyon. As an early user, it’s been fun to watch Spark go from an academic lab to the most active open source project in big data. In my recent travels, I’ve met Spark users from companies of all sizes and and from many industries. I’ve also spoken with companies that came of age before Spark was available or mature enough, and many are replacing homegrown tools with Spark (Full disclosure: I’m an advisor to Databricks, a start-up commercializing Apache Spark..)
Subscribe to the O’Reilly Data Show Podcast
A few months ago, I spoke with UC Berkeley Professor and Databricks CEO Ion Stoica about the early days of Spark and the Berkeley Data Analytics Stack. Ion noted that by the time his students began work on Spark and Mesos, his experience at his other start-up Conviva had already informed some of the design choices:
“Actually, this story started back in 2009, and it started with a different project, Mesos. So, this was a class project in a class I taught in the spring of 2009. And that was to build a cluster management system, to be able to support multiple cluster computing frameworks like Hadoop, at that time, MPI and others. To share the same cluster as the data in the cluster. Pretty soon after that, we thought about what to build on top of Mesos, and that was Spark. Initially, we wanted to demonstrate that it was actually easier to build a new framework from scratch on top of Mesos, and of course we wanted it to be also special. So, we targeted workloads for which Hadoop at that time was not good enough. Hadoop was targeting batch computation. So, we targeted interactive queries and iterative computation, like machine learning. Read more…

New opportunities in the maturing marketplace of big data components
The evolving marketplace is making new data applications and interactions possible.
Editor’s note: this is an excerpt from our new report Data: Emerging Trends and Technologies, by Alistair Croll. Download the free report here.
Here’s a look at some options in the evolving, maturing marketplace of big data components that are making the new applications and interactions we’ve been looking at possible.
Graph theory
First used in social network analysis, graph theory is finding more and more homes in research and business. Machine learning systems can scale up fast with tools like Parameter Server, and the TitanDB project means developers have a robust set of tools to use.
Are graphs poised to take their place alongside relational database management systems (RDBMS), object storage, and other fundamental data building blocks? What are the new applications for such tools?
Inside the black box of algorithms: whither regulation?
It’s possible for a machine to create an algorithm no human can understand. Evolutionary approaches to algorithmic optimization can result in inscrutable, yet demonstrably better, computational solutions.
If you’re a regulated bank, you need to share your algorithms with regulators. But if you’re a private trader, you’re under no such constraints. And having to explain your algorithms limits how you can generate them.
As more and more of our lives are governed by code that decides what’s best for us, replacing laws, actuarial tables, personal trainers, and personal shoppers, oversight means opening up the black box of algorithms so they can be regulated.
Years ago, Orbitz was shown to be charging web visitors who owned Apple devices more money than those visiting via other platforms, such as the PC. Only that’s not the whole story: Orbitz’s machine learning algorithms, which optimized revenue per customer, learned that the visitor’s browser was a predictor of their willingness to pay more. Read more…
Cheap sensors, fast networks, and distributed computing
The history of computing has been a constant pendulum — that pendulum is now swinging back toward distribution.
Editor’s note: this is an excerpt from our new report Data: Emerging Trends and Technologies, by Alistair Croll. You can download the free report here.
The trifecta of cheap sensors, fast networks, and distributing computing are changing how we work with data. But making sense of all that data takes help, which is arriving in the form of machine learning. Here’s one view of how that might play out.
Clouds, edges, fog, and the pendulum of distributed computing
The history of computing has been a constant pendulum, swinging between centralization and distribution.The first computers filled rooms, and operators were physically within them, switching toggles and turning wheels. Then came mainframes, which were centralized, with dumb terminals.
As the cost of computing dropped and the applications became more democratized, user interfaces mattered more. The smarter clients at the edge became the first personal computers; many broke free of the network entirely. The client got the glory; the server merely handled queries.
Once the web arrived, we centralized again. LAMP (Linux, Apache, MySQL, PHP) buried deep inside data centers, with the computer at the other end of the connection relegated to little more than a smart terminal rendering HTML. Load-balancers sprayed traffic across thousands of cheap machines. Eventually, the web turned from static sites to complex software as a service (SaaS) applications.
Then the pendulum swung back to the edge, and the clients got smart again. First with AJAX, Java, and Flash; then in the form of mobile apps, where the smartphone or tablet did most of the hard work and the back end was a communications channel for reporting the results of local action. Read more…

Wouldn’t it be fun to build your own Google?
Exploring open web crawl data — what if you had your own copy of the entire web, and you could do with it whatever you want?

For the last few millennia, libraries have been the custodians of human knowledge. By collecting books, and making them findable and accessible, they have done an incredible service to humanity. Our modern society, culture, science, and technology are all founded upon ideas that were transmitted through books and libraries.
Then the web came along, and allowed us to also publish all the stuff that wasn’t good enough to put in books, and do it all much faster and cheaper. Although the average quality of material you find on the web is quite poor, there are some pockets of excellence, and in aggregate, the sum of all web content is probably even more amazing than all libraries put together.
Google (and a few brave contenders like Bing, Baidu, DuckDuckGo and Blekko) have kindly indexed it all for us, acting as the web’s librarians. Without search engines, it would be terribly difficult to actually find anything, so hats off to them. However, what comes next, after search engines? It seems unlikely that search engines are the last thing we’re going to do with the web. Read more…
Big data’s big ideas
From cognitive augmentation to artificial intelligence, here's a look at the major forces shaping the data world.
Looking back at the evolution of our Strata events, and the data space in general, we marvel at the impressive data applications and tools now being employed by companies in many industries. Data is having an impact on business models and profitability. It’s hard to find a non-trivial application that doesn’t use data in a significant manner. Companies who use data and analytics to drive decision-making continue to outperform their peers.
Up until recently, access to big data tools and techniques required significant expertise. But tools have improved and communities have formed to share best practices. We’re particularly excited about solutions that target new data sets and data types. In an era when the requisite data skill sets cut across traditional disciplines, companies have also started to emphasize the importance of processes, culture, and people. Read more…