"stratablog" entries

IPython: A unified environment for interactive data analysis
It has roots in academic scientific computing, but has features that appeal to many data scientists
As I noted in a recent post on reproducing data projects, notebooks have become popular tools for maintaining, sharing, and replicating long data science workflows. Much of that is due to the popularity of IPython1. In development since 2001, IPython grew out of the scientific computing community and has slowly added features that appeal to data scientists.
Roots in academic scientific computing
As IPython creator Fernando Perez noted in his “historical retrospective”, exploratory analysis in a scientific setting requires a solid interactive environment. After years of development IPython has become a great tool for interacting with data. IPython also addresses other important pain points for scientists – reproducibility and collaboration – issues that are equally important to data scientists working in industry.
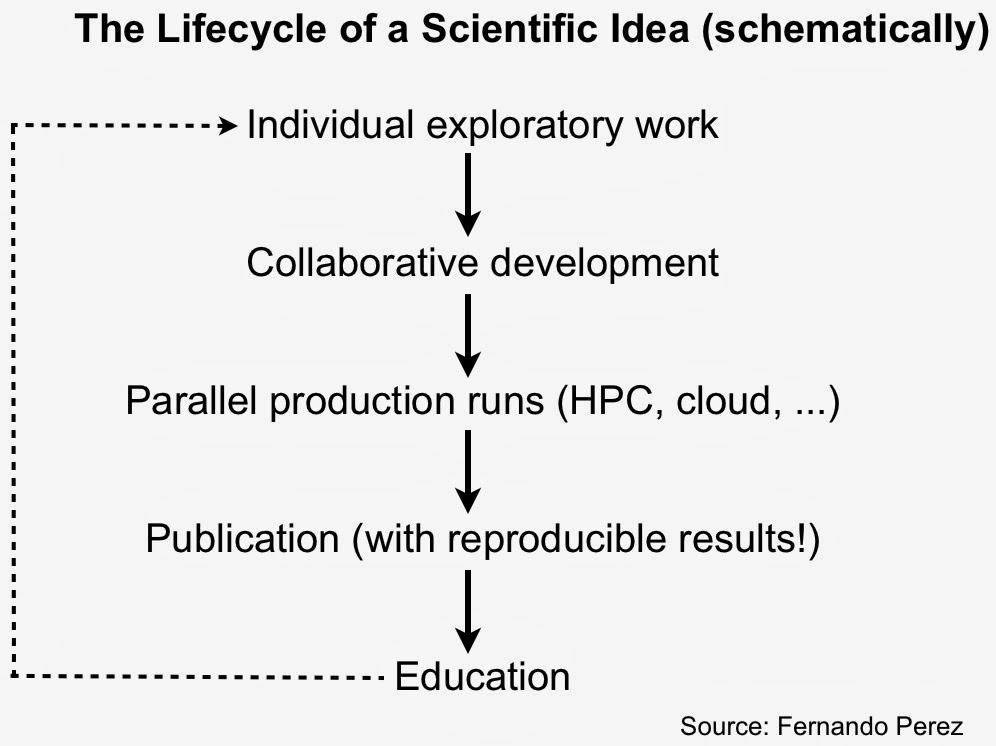
IPython is more than just Python
With an interactive widget architecture that’s 100% language-agnostic, these days IPython is used by many other programming language communities2, including Julia, Haskell, F#, Ruby, Go, and Scala. If you’re a data scientist who likes to mix-and-match languages, you can create, maintain, and share multi-language data projects in IPython:

Knight news winners, a journalist-summoning app, and an analysis of Forbes and new media.
Knight news announced the seven newest winners of their news challenge grants this week. For this round, the challenge focused on health data. The projects include a personal monitor which will allow people to do their own chemical analysis of their environments, and an online portal where people can volunteer their personal health information to aid in medical research.
German journalists at the online news outlet Mittendrin, in partnership with Open Data City, have developed an app that allows members of the public to alert a journalist when they witness a newsworthy event, like a police action or spontaneous demonstration. The ‘Call A Journalist’ app will contact a journalist and deliver your GPS information along with your report. The best part is that after your information is relayed, the app will let you know that a journalist is on the way. Now, why didn’t I think of that?

Why is building custom recommender systems hard? Does it have to be?

Photo Courtesy of Carlos Guestrin
Today, it’s shocking (and honestly exciting) how much of my daily experience is determined by a recommender system. These systems drive amazing experiences everywhere, telling me where to eat, what to listen to, what to watch, what to read, and even who I should be friends with. Furthermore, information overload is making recommender systems indispensable, since I can’t find what I want on the web simply using keyword search tools. Recommenders are behind the success of industry leaders like Netflix, Google, Pandora, eHarmony, Facebook, and Amazon. It’s no surprise companies want to integrate recommender systems with their own online experiences. However, as I talk to team after team of smart industry engineers, it has become clear that building and managing these systems is usually a bit out of reach, especially given all the other demands on the team’s time.

Learning Apache Mesos
In the summer of 2012, Accel Partners hosted an invitation-only Big Data conference at Stanford. Ping Li stood near the exit with a checkbook, ready to invest $1MM in pitches for real-time analytics on clusters. However, real-time means many different things. For MetaScale working on the Sears turnaround, real-time means shrinking a 6 hour window on a mainframe to 6 minutes on Hadoop. For a hedge fund, real-time means compiling Python to run on GPUs where milliseconds matter, or running on FPGA hardware for microsecond response.
With much emphasis on Hadoop circa 2012, one might think that no other clusters existed. Nothing could be further from the truth: Memcached, Ruby on Rails, Cassandra, Anaconda, Redis, Node.js, etc. – all in large-scale production use for mission critical apps, much closer to revenue than the batch jobs. Google emphasizes a related point in their Omega paper: scheduling batch jobs is not difficult, while scheduling services on a cluster is a hard problem, and that translates to lots of money.
2013 Data Science Salary Survey
Tools, Trends, What Pays (and What Doesn't) for Data Professionals
 There is no shortage of news about the importance of data or the career opportunities within data. Yet a discussion of modern data tools can help us understand what the current data evolution is all about, and it can also be used as a guide for those considering stepping into the data space or progressing within it.
There is no shortage of news about the importance of data or the career opportunities within data. Yet a discussion of modern data tools can help us understand what the current data evolution is all about, and it can also be used as a guide for those considering stepping into the data space or progressing within it.
In our report, 2013 Data Science Salary Survey, we make our own data-driven contribution to the conversation. We collected a survey from attendees of the Strata Conference in New York and Santa Clara, California, about tool usage and salary.
Strata attendees span a wide spectrum within the data world: Hadoop experts and business leaders, software developers and analysts. By no means does everyone use data on a “Big” scale, but almost all attendees have some technical aspect to their role. Strata attendees may not represent a random sample of all professionals working with data, but they do represent a broad slice of the population. If there is a bias, it is likely toward the forefront of the data space, with attendees using the newest tools (or being very interested in learning about them).

The democratization of medical science
An interview with Ash Damle of Lumiata on the role of data in healthcare.
Vinod Khosla has stirred up some controversy in the healthcare community over the last several years by suggesting that computers might be able to provide better care than doctors. This includes remarks he made at Strata Rx in 2012, including that, “We need to move from the practice of medicine to the science of medicine. And the science of medicine is way too complex for human beings to do.”
So when I saw the news that Khosla Ventures has just invested $4M in Series A funding into Lumiata (formerly MEDgle), a company that specializes in healthcare data analytics, I was very curious to hear more about that company’s vision. Ash Damle is the CEO at Lumiata. We recently spoke by phone to discuss how data can improve access to care and help level the playing field of care quality.
Tell me a little about Lumiata: what it is and what it does.

A Lumiata network graph of diagnosis interrelation.
Ash Damle: We’re bringing together the best of medical science and graph analytics to provide the best prescriptive analysis to those providing care. We data-mine all the publicly available data sources, such as journals, de-identified records, etc. We analyze the data to make sure we’re learning the right things and, most importantly, what the relationships are among the data. We have fundamentally delved into looking at that whole graph, the way Google does to provide you with relevant search results. We curate those relationships to make sure they’re sensible, and take into account behavioral and social factors.
Big Data systems are making a difference in the fight against cancer
Open source, distributed computing tools speedup an important processing pipeline for genomics data
As open source, big data tools enter the early stages of maturation, data engineers and data scientists will have many opportunities to use them to “work on stuff that matters”. Along those lines, computational biology and medicine are areas where skilled data professionals are already beginning to make an impact. I recently came across a compelling open source project from UC Berkeley’s AMPLab: ADAM is a processing engine and set of formats for genomics data.
Second-generation sequencing machines produce more detailed and thus much larger files for analysis (250+ GB file for each person). Existing data formats and tools are optimized for single-server processing and do not easily scale out. ADAM uses distributed computing tools and techniques to speedup key stages of the variant processing pipeline (including sorting and deduping):
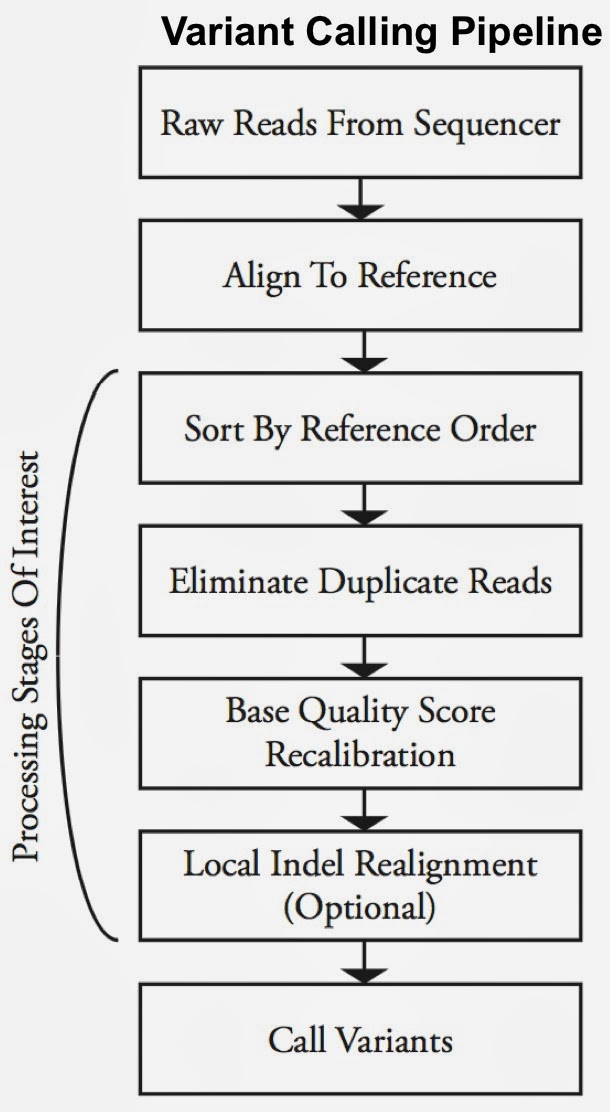
Very early on the designers of ADAM realized that a well-designed data schema (that specifies the representation of data when it is accessed) was key to having a system that could leverage existing big data tools. The ADAM format uses the Apache Avro data serialization system and comes with a human-readable schema that can be accessed using many programming languages (including C/C++/C#, Java/Scala, php, Python, Ruby). ADAM also includes a data format/access API implemented on top of Apache Avro and Parquet, and a data transformation API implemented on top of Apache Spark. Because it’s built with widely adopted tools, ADAM users can leverage components of the Hadoop (Impala, Hive, MapReduce) and BDAS (Shark, Spark, GraphX, MLbase) stacks for interactive and advanced analytics.
Apache Mesos: Open Source Datacenter Computing
Mesos offers reliability, efficiency and faster developer productivity.
Virtual machines (VMs) have enjoyed a long history, from IBM’s CP–40 in the late 1960s on through the rise of VMware in the late 1990s. Widespread VM use nearly became synonymous with “cloud computing” by the late 2000s: public clouds, private clouds, hybrid clouds, etc. One firm, however, bucked the trend: Google.
Google’s datacenter computing leverages isolation in lieu of VMs. Public disclosure is limited, but the Omega paper from EuroSys 2013 provides a good overview. See also two YouTube videos: John Wilkes in 2011 GAFS Omega and Jeff Dean in Taming Latency Variability… For the business case, see an earlier Data blog post, that discusses how multi-tenancy and efficient utilization translates into improved ROI.
One takeaway is Google’s analysis of cluster traces from large Internet firms: while ~80% of the jobs are batch, ~80% of the resources get used for services. Another takeaway is Google’s categorization of cluster scheduling technology: monolithic versus two-level versus shared state. The first category characterizes Borg, which Google has used for several years. The third characterizes their R&D goals, a newer system called Omega.
A compelling family of DSLs for Data Science
The Delite framework has produced high-performance languages that target data scientists
An important reason why pydata tools and Spark appeal to data scientists is that they both cover many data science tasks and workloads (Spark users can move seamlessly between batch and streaming). Being able to use the same programming style and syntax for workflows that span a variety of tasks is a huge productivity boost. In the case of Spark (and Hadoop), the emergence of a variety of scalable analytic engines have made distributed computing applications much easier to build.
Delite: a framework for embedded, parallel, and high-performance DSLs
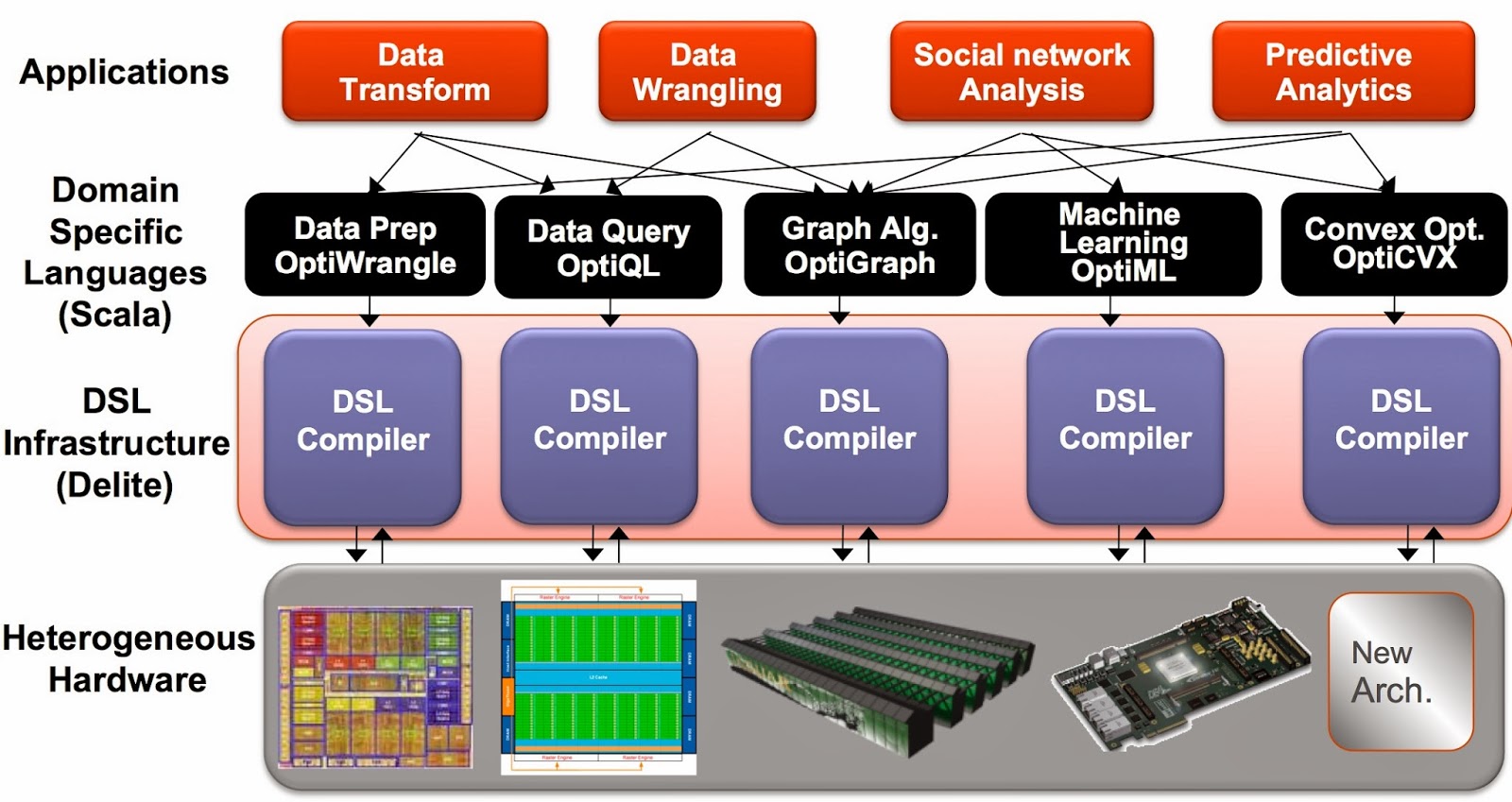
Another way to boost productivity is to use a family of high-performance languages that cover many data science tasks. Ideally you want languages that allow programmers to focus on applications (not on low-level details of parallel programming) and that can run efficiently on different machines and architectures1 (CPU, GPU). And just like pydata and Spark, syntax and context-switching shouldn’t get in the way of tackling complex data science workflows.
The Delite framework from Stanford’s Pervasive Parallelism Lab (PPL) has been used to produce a family of high-performance domain specific languages (DSLs) that target different data analysis tasks. DSLs are programming languages2 with restricted expressiveness (for a particular domain) and tend to be high-level in nature (they are often declarative and deterministic). Delite is a compiler and runtime infrastructure that allows language designers to use aggressive, domain-specific optimizations to deliver high-performance DSLs. Using Delite, the team at Stanford produced DSLs embedded in a functional language (Scala) with performance results comparable to hand-optimized implementations (e.g. MATLAB, LINQ) across different domains.
An Introduction to Hadoop 2.0: Understanding the New Data Operating System
Sneak peek at an upcoming tutorial at Strata Santa Clara 2014
Apache Hadoop 2.0 represents a generational shift in the architecture of Apache Hadoop. With YARN, Apache Hadoop is recast as a significantly more powerful platform – one that takes Hadoop beyond merely batch applications to taking its position as a ‘data operating system’ where HDFS is the file system and YARN is the operating system.
YARN is a re-architecture of Hadoop that allows multiple applications to run on the same platform. With YARN, applications run “in” Hadoop, instead of “on” Hadoop:
