Ben Lorica

Ben Lorica is the Chief Data Scientist of O'Reilly Media, Inc. and Program Director of Strata+Hadoop World. He has applied Business Intelligence, Data Mining, Machine Learning and Statistical Analysis in a variety of settings including Direct Marketing, Consumer and Market Research, Targeted Advertising, Text Mining, and Financial Engineering. His background includes stints with an investment management company, internet startups, and financial services.
Apache Spark’s journey from academia to industry
In this O'Reilly Data Show Podcast: Ion Stoica talks about the rise of Apache Spark and Apache Mesos.
Three projects from UC Berkeley’s AMPLab have been keenly adopted by industry: Apache Mesos, Apache Spark, and Tachyon. As an early user, it’s been fun to watch Spark go from an academic lab to the most active open source project in big data. In my recent travels, I’ve met Spark users from companies of all sizes and and from many industries. I’ve also spoken with companies that came of age before Spark was available or mature enough, and many are replacing homegrown tools with Spark (Full disclosure: I’m an advisor to Databricks, a start-up commercializing Apache Spark..)
Subscribe to the O’Reilly Data Show Podcast
A few months ago, I spoke with UC Berkeley Professor and Databricks CEO Ion Stoica about the early days of Spark and the Berkeley Data Analytics Stack. Ion noted that by the time his students began work on Spark and Mesos, his experience at his other start-up Conviva had already informed some of the design choices:
“Actually, this story started back in 2009, and it started with a different project, Mesos. So, this was a class project in a class I taught in the spring of 2009. And that was to build a cluster management system, to be able to support multiple cluster computing frameworks like Hadoop, at that time, MPI and others. To share the same cluster as the data in the cluster. Pretty soon after that, we thought about what to build on top of Mesos, and that was Spark. Initially, we wanted to demonstrate that it was actually easier to build a new framework from scratch on top of Mesos, and of course we wanted it to be also special. So, we targeted workloads for which Hadoop at that time was not good enough. Hadoop was targeting batch computation. So, we targeted interactive queries and iterative computation, like machine learning. Read more…
Clustering bitcoin accounts using heuristics
In this O'Reilly Data Show Podcast: Sarah Meiklejohn on analytic applications for blockchain and cryptocurrency technology.
Editor’s note: we’ll explore present and future applications of cryptocurrency and blockchain technologies at our upcoming Radar Summit: Bitcoin & the Blockchain on Jan. 27, 2015, in San Francisco.
A few data scientists are starting to play around with cryptocurrency data, and as bitcoin and related technologies start gaining traction, I expect more to wade in. As the space matures, there will be many interesting applications based on analytics over the transaction data produced by these technologies. The blockchain — the distributed ledger that contains all bitcoin transactions — is publicly available, and the underlying data set is of modest size. Data scientists can work with this data once it’s loaded into familiar data structures, but producing insights requires some domain knowledge and expertise.
Subscribe to the O’Reilly Data Show Podcast
I recently spoke with Sarah Meiklejohn, a lecturer at UCL, and an expert on computer security and cryptocurrencies. She was part of an academic research team that studied pseudo-anonymity (“pseudonymity”) in bitcoin. In particular, they used transaction data to compare “potential” anonymity to the “actual” anonymity achieved by users. A bitcoin user can use many different public keys, but careful research led to a few heuristics that allowed them to cluster addresses belonging to the same user:
“In theory, a user can go by many different pseudonyms. If that user is careful and keeps the activity of those different pseudonyms separate, completely distinct from one another, then they can really maintain a level of, maybe not anonymity, but again, cryptographically it’s called pseudo-anonymity. So, if they are a legitimate businessman on the one hand, they can use a certain set of pseudonyms for that activity, and then if they are dealing drugs on Silk Road, they might use a completely different set of pseudonyms for that, and you wouldn’t be able to tell that that’s the same user.
Regulation and decentralization: Defending the blockchain
Andreas Antonopoulos urges the Canadian Senate to resist the temptation to centralize bitcoin.
Editor’s note: our O’Reilly Radar Summit: Bitcoin & the Blockchain will take place on January 27, 2015, at Fort Mason in San Francisco. Andreas Antonopoulos, Vitalik Buterin, Naval Ravikant, and Bill Janeway are but a few of the confirmed speakers for the event. Learn more about the event and reserve your ticket here.
We recently announced a Radar summit on present and future applications of cryptocurrencies and blockchain technologies. In a webcast presentation one of our program chairs, Kieren James-Lubin, observed that we’re very much in the early days of these technologies. He also noted that the technologies are complex enough that most users will rely on service providers (like wallets) to securely store, transfer, and receive cryptocurrencies.
As some of these service providers reach a certain scale, they will start coming under the scrutiny of regulators. Certain tenets are likely to remain: currencies require continuous liquidity and large financial institutions need access to the lender of last resort.
There are also cultural norms that take time to change. Take the example of notaries, whose services seem amenable to being replaced by blockchain technologies. Such a wholesale change would entail adjusting rules and norms across localities, which means going up against the lobbying efforts of established incumbents.
One way to sway regulators and skeptics is to point out that the decentralized nature of the (bitcoin) blockchain can unlock innovation in financial services and other industries. Mastering Bitcoin author Andreas Antonopoulos did a masterful job highlighting this in his recent testimony before the Canadian Senate:
“Traditional models for financial payment networks and banking rely on centralized control in order to provide security. The architecture of a traditional financial network is built around a central authority, such as a clearinghouse. As a result, security and authority have to be vested in that central actor. The resulting security model looks like a series of concentric circles with very limited access to the center and increasing access as we move farther away from the center. However, even the most outermost circle cannot afford open access.
Building Apache Kafka from scratch
In this episode of the O'Reilly Data Show Podcast, Jay Kreps talks about data integration, event data, and the Internet of Things.
At the heart of big data platforms are robust data flows that connect diverse data sources. Over the past few years, a new set of (mostly open source) software components have become critical to tackling data integration problems at scale. By now, many people have heard of tools like Hadoop, Spark, and NoSQL databases, but there are a number of lesser-known components that are “hidden” beneath the surface.
In my conversations with data engineers tasked with building data platforms, one tool stands out: Apache Kafka, a distributed messaging system that originated from LinkedIn. It’s used to synchronize data between systems and has emerged as an important component in real-time analytics.
In my travels over the past year, I’ve met engineers across many industries who use Apache Kafka in production. A few months ago, I sat down with O’Reilly author and Radar contributor Jay Kreps, a highly regarded data engineer and former technical lead for Online Data Infrastructure at LinkedIn, and most recently CEO/co-founder of Confluent. Read more…
Decoding bitcoin and the blockchain
Introducing Bitcoin & the Blockchain: An O’Reilly Radar Summit

When the creators of bitcoin solved the “double spend” problem in a decentralized manner, they introduced techniques that have implications far beyond digital currency. Our newly announced one-day event — Bitcoin & the Blockchain: An O’Reilly Radar Summit — is in line with our tradition of highlighting applications of developments in computer science. Financial services have long relied on centralized solutions, so in many ways, products from this sector have become canonical examples of the developments we plan to cover over the next few months. But many problems that require an intermediary are being reexamined with techniques developed for bitcoin.
How do you get multiple parties in a transaction to trust each other without an intermediary? In the case of a digital currency like bitcoin, decentralization means reaching consensus over an insecure network. As Mastering Bitcoin author Andreas Antonopoulos noted in an earlier post, several innovations lie at the heart of what makes bitcoin disruptive:
“Bitcoin is a combination of several innovations, arranged in a novel way: a peer-to-peer network, a proof-of-work algorithm, a distributed timestamped accounting ledger, and an elliptic-curve cryptography and key infrastructure. Each of these parts is novel on its own, but the combination and specific arrangement was revolutionary for its time and is beginning to show up in more innovations outside bitcoin itself.”
The science of moving dots: the O’Reilly Data Show Podcast
Rajiv Maheswaran talks about the tools and techniques required to analyze new kinds of sports data.
Many data scientists are comfortable working with structured operational data and unstructured text. Newer techniques like deep learning have opened up data types like images, video, and audio.
Other common data sources are garnering attention. With the rise of mobile phones equipped with GPS, I’m meeting many more data scientists at start-ups and large companies who specialize in spatio-temporal pattern recognition. Analyzing “moving dots” requires specialized tools and techniques.
Subscribe to the O’Reilly Data Show Podcast
A few months ago, I sat down with Rajiv Maheswaran founder and CEO of Second Spectrum, a company that applies analytics to sports tracking data. Maheswaran talked about this new kind of data and the challenge of finding patterns:
“It’s interesting because it’s a new type of data problem. Everybody knows that big data machine learning has done a lot of stuff in structured data, in photos, in translation for language, but moving dots is a very new kind of data where you haven’t figured out the right feature set to be able to find patterns from. There’s no language of moving dots, at least not that computers understand. People understand it very well, but there’s no computational language of moving dots that are interacting. We wanted to build that up, mostly because data about moving dots is very, very new. It’s only in the last five years, between phones and GPS and new tracking technologies, that moving data has actually emerged.”
Big data’s big ideas
From cognitive augmentation to artificial intelligence, here's a look at the major forces shaping the data world.
Looking back at the evolution of our Strata events, and the data space in general, we marvel at the impressive data applications and tools now being employed by companies in many industries. Data is having an impact on business models and profitability. It’s hard to find a non-trivial application that doesn’t use data in a significant manner. Companies who use data and analytics to drive decision-making continue to outperform their peers.
Up until recently, access to big data tools and techniques required significant expertise. But tools have improved and communities have formed to share best practices. We’re particularly excited about solutions that target new data sets and data types. In an era when the requisite data skill sets cut across traditional disciplines, companies have also started to emphasize the importance of processes, culture, and people. Read more…
Announcing Spark Certification
A new partnership between O’Reilly and Databricks offers certification and training in Apache Spark.
Editor’s note: full disclosure — Ben is an advisor to Databricks.
![]() I am pleased to announce a joint program between O’Reilly and Databricks to certify Spark developers. O’Reilly has long been interested in certification, and with this inaugural program, we believe we have the right combination — an ascendant framework and a partnership with the team behind the technology. The founding team of Databricks comprises members of the UC Berkeley AMPLab team that created Spark.
I am pleased to announce a joint program between O’Reilly and Databricks to certify Spark developers. O’Reilly has long been interested in certification, and with this inaugural program, we believe we have the right combination — an ascendant framework and a partnership with the team behind the technology. The founding team of Databricks comprises members of the UC Berkeley AMPLab team that created Spark.
The certification exam will be offered at Strata events, through Databricks’ Spark Summits, and at training workshops run by Databricks and its partner companies. A variety of O’Reilly resources will accompany the certification program, including books, training days, and videos targeted at developers and companies interested in the Apache Spark ecosystem. Read more…
Scaling up data frames
New frameworks for interactive business analysis and advanced analytics fuel the rise in tabular data objects.

Long before the advent of “big data,” analysts were building models using tools like R (and its forerunners S/S-PLUS). Productivity hinged on tools that made data wrangling, data inspection, and data modeling convenient. Among R users, this meant proficiency with data frames — objects used to store data matrices that can hold both numeric and categorical data. A data.frame is the data structure consumed by most R analytic libraries.
But not all data scientists use R, nor is R suitable for all data problems. I’ve been watching with interest the growing number of alternative data structures for business analysis and advanced analytics. These new tools are designed to handle much larger data sets and are frequently optimized for specific problems. And they all use idioms that are familiar to data scientists — either SQL-like expressions, or syntax similar to those used for R data.frame or pandas.DataFrame.
There are many use cases for graph databases and analytics
Business users are becoming more comfortable with graph analytics.
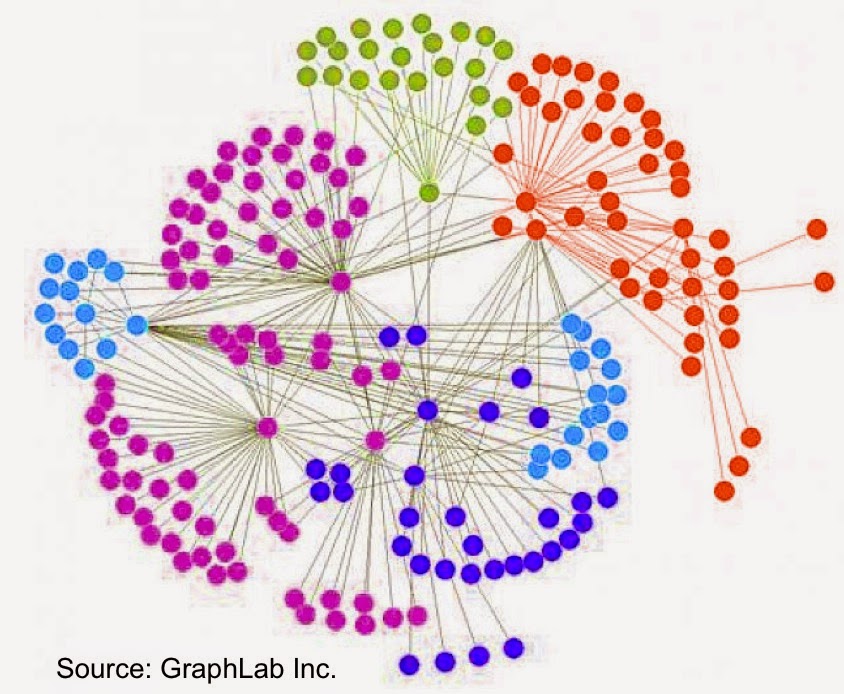 The rise of sensors and connected devices will lead to applications that draw from network/graph data management and analytics. As the number of devices surpasses the number of people — Cisco estimates 50 billion connected devices by 2020 — one can imagine applications that depend on data stored in graphs with many more nodes and edges than the ones currently maintained by social media companies.
The rise of sensors and connected devices will lead to applications that draw from network/graph data management and analytics. As the number of devices surpasses the number of people — Cisco estimates 50 billion connected devices by 2020 — one can imagine applications that depend on data stored in graphs with many more nodes and edges than the ones currently maintained by social media companies.
This means that researchers and companies will need to produce real-time tools and techniques that scale to much larger graphs (measured in terms of nodes & edges). I previously listed tools for tapping into graph data, and I continue to track improvements in accessibility, scalability, and performance. For example, at the just-concluded Spark Summit, it was apparent that GraphX remains a high-priority project within the Spark1 ecosystem.