"spark" entries

Patrick Wendell on Spark’s roadmap, Spark R API, and deep learning on the horizon
The O'Reilly Radar Podcast: A special holiday cross-over of the O'Reilly Data Show Podcast.
Subscribe to the O’Reilly Radar Podcast to track the technologies and people that will shape our world in the years to come.

In this special holiday episode of the Radar Podcast, we’re featuring a cross-over of the O’Reilly Data Show Podcast, which you can find on iTunes, Stitcher, TuneIn, or SoundCloud. O’Reilly’s Ben Lorica hosts that podcast, and in this episode, he chats with Apache Spark release manager and Databricks co-founder Patrick Wendell about the roadmap of Spark and where it’s headed, and interesting applications he’s seeing in the growing Spark ecosystem.
Here are some highlights from their chat:
We were really trying to solve research problems, so we were trying to work with the early users of Spark, getting feedback on what issues it had and what types of problems they were trying to solve with Spark, and then use that to influence the roadmap. It was definitely a more informal process, but from the very beginning, we were expressly user driven in the way we thought about building Spark, which is quite different than a lot of other open source projects. … From the beginning, we were focused on empowering other people and building platforms for other developers.
One of the early users was Conviva, a company that does analytics for real-time video distribution. They were a very early user of Spark, they continue to use it today, and a lot of their feedback was incorporated into our roadmap, especially around the types of APIs they wanted to have that would make data processing really simple for them, and of course, performance was a big issue for them very early on because in the business of optimizing real-time video streams, you want to be able to react really quickly when conditions change. … Early on, things like latency and performance were pretty important.

On the evolution of machine learning
From linear models to neural networks: an interview with Reza Zadeh.
Get notified when our free report, “Future of Machine Intelligence: Perspectives from Leading Practitioners,” is available for download. The following interview is one of many that will be included in the report.
As part of our ongoing series of interviews surveying the frontiers of machine intelligence, I recently interviewed Reza Zadeh. Reza is a Consulting Professor in the Institute for Computational and Mathematical Engineering at Stanford University and a Technical Advisor to Databricks. His work focuses on Machine Learning Theory and Applications, Distributed Computing, and Discrete Applied Mathematics.
Key Takeaways
- Neural networks have made a comeback and are playing a growing role in new approaches to machine learning.
- The greatest successes are being achieved via a supervised approach leveraging established algorithms.
- Spark is an especially well-suited environment for distributed machine learning.
David Beyer: Tell us a bit about your work at Stanford
Reza Zadeh: At Stanford, I designed and teach distributed algorithms and optimization (CME 323) as well as a course called discrete mathematics and algorithms (CME 305). In the discrete mathematics course, I teach algorithms from a completely theoretical perspective, meaning that it is not tied to any programming language or framework, and we fill up whiteboards with many theorems and their proofs. Read more…

Investigating Spark’s performance
A deep dive into performance bottlenecks with Spark PMC member Kay Ousterhout.
 For many who use and deploy Apache Spark, knowing how to find critical bottlenecks is extremely important. In a recent O’Reilly webcast, Making Sense of Spark Performance, Spark committer and PMC member Kay Ousterhout gave a brief overview of how Spark works, and dove into how she measured performance bottlenecks using new metrics, including block-time analysis. Ousterhout walked through high-level takeaways from her in-depth analysis of several workloads, and offered a live demo of a new performance analysis tool and explained how you can use it to improve your Spark performance.
For many who use and deploy Apache Spark, knowing how to find critical bottlenecks is extremely important. In a recent O’Reilly webcast, Making Sense of Spark Performance, Spark committer and PMC member Kay Ousterhout gave a brief overview of how Spark works, and dove into how she measured performance bottlenecks using new metrics, including block-time analysis. Ousterhout walked through high-level takeaways from her in-depth analysis of several workloads, and offered a live demo of a new performance analysis tool and explained how you can use it to improve your Spark performance.
Her research uncovered surprising insights into Spark’s performance on two benchmarks (TPC-DS and the Big Data Benchmark), and one production workload. As part of our overall series of webcasts on big data, data science, and engineering, this webcast debunked commonly held ideas surrounding network performance, showing that CPU — not I/O — is often a critical bottleneck, and demonstrated how to identify and fix stragglers.
Network performance is almost irrelevant
While there’s been a lot of research work on performance — mainly surrounding the issues of whether to cache input data in-memory or on machine, scheduling, straggler tasks, and network performance — there haven’t been comprehensive studies into what’s most important to performance overall. This is where Ousterhout’s research comes in — taking on what she refers to as “community dogma,” beginning with the idea that network and disk I/O are major bottlenecks. Read more…

Small brains, big data
How neuroscience is benefiting from distributed computing — and how computing might learn from neuroscience.
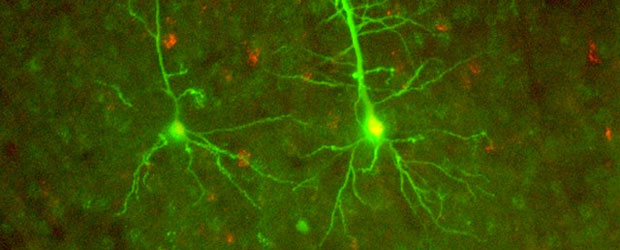
When we think about big data, we usually think about the web: the billions of users of social media, the sensors on millions of mobile phones, the thousands of contributions to Wikipedia, and so forth. Due to recent innovations, web-scale data can now also come from a camera pointed at a small, but extremely complex object: the brain. New progress in distributed computing is changing how neuroscientists work with the resulting data — and may, in the process, change how we think about computation. Read more…

Scaling up data frames
New frameworks for interactive business analysis and advanced analytics fuel the rise in tabular data objects.

Long before the advent of “big data,” analysts were building models using tools like R (and its forerunners S/S-PLUS). Productivity hinged on tools that made data wrangling, data inspection, and data modeling convenient. Among R users, this meant proficiency with data frames — objects used to store data matrices that can hold both numeric and categorical data. A data.frame is the data structure consumed by most R analytic libraries.
But not all data scientists use R, nor is R suitable for all data problems. I’ve been watching with interest the growing number of alternative data structures for business analysis and advanced analytics. These new tools are designed to handle much larger data sets and are frequently optimized for specific problems. And they all use idioms that are familiar to data scientists — either SQL-like expressions, or syntax similar to those used for R data.frame or pandas.DataFrame.
A growing number of applications are being built with Spark
Many more companies want to highlight how they're using Apache Spark in production.
One of the trends we’re following closely at Strata is the emergence of vertical applications. As components for creating large-scale data infrastructures enter their early stages of maturation, companies are focusing on solving data problems in specific industries rather than building tools from scratch. Virtually all of these components are open source and have contributors across many companies. Organizations are also sharing best practices for building big data applications, through blog posts, white papers, and presentations at conferences like Strata.
These trends are particularly apparent in a set of technologies that originated from UC Berkeley’s AMPLab: the number of companies that are using (or plan to use) Spark in production1 has exploded over the last year. The surge in popularity of the Apache Spark ecosystem stems from the maturation of its individual open source components and the growing community of users. The tight integration of high-performance tools that address different problems and workloads, coupled with a simple programming interface (in Python, Java, Scala), make Spark one of the most popular projects in big data. The charts below show the amount of active development in Spark:

For the second year in a row, I’ve had the privilege of serving on the program committee for the Spark Summit. I’d like to highlight a few areas where Apache Spark is making inroads. I’ll focus on proposals2 from companies building applications on top of Spark.
Interface Languages and Feature Discovery
It's easier to "discover" features with tools that have broad coverage of the data science workflow
Here are a few more observations based on conversations I had during the just concluded Strata Santa Clara conference.
Interface languages: Python, R, SQL (and Scala)
This is a great time to be a data scientist or data engineer who relies on Python or R. For starters there are developer tools that simplify setup, package installation, and provide user interfaces designed to boost productivity (RStudio, Continuum, Enthought, Sense).
Increasingly, Python and R users can write the same code and run it against many different execution1 engines. Over time the interface languages will remain constant but the execution engines will evolve or even get replaced. Specifically there are now many tools that target Python and R users interested in implementations of algorithms that scale to large data sets (e.g., GraphLab, wise.io, Adatao, H20, Skytree, Revolution R). Interfaces for popular engines like Hadoop and Apache Spark are also available – PySpark users can access algorithms in MLlib, SparkR users can use existing R packages.
In addition many of these new frameworks go out of their way to ease the transition for Python and R users. wise.io “… bindings follow the Scikit-Learn conventions”, and as I noted in a recent post, with SFrames and Notebooks GraphLab, Inc. built components2 that are easy for Python users to learn.
Big Data systems are making a difference in the fight against cancer
Open source, distributed computing tools speedup an important processing pipeline for genomics data
As open source, big data tools enter the early stages of maturation, data engineers and data scientists will have many opportunities to use them to “work on stuff that matters”. Along those lines, computational biology and medicine are areas where skilled data professionals are already beginning to make an impact. I recently came across a compelling open source project from UC Berkeley’s AMPLab: ADAM is a processing engine and set of formats for genomics data.
Second-generation sequencing machines produce more detailed and thus much larger files for analysis (250+ GB file for each person). Existing data formats and tools are optimized for single-server processing and do not easily scale out. ADAM uses distributed computing tools and techniques to speedup key stages of the variant processing pipeline (including sorting and deduping):
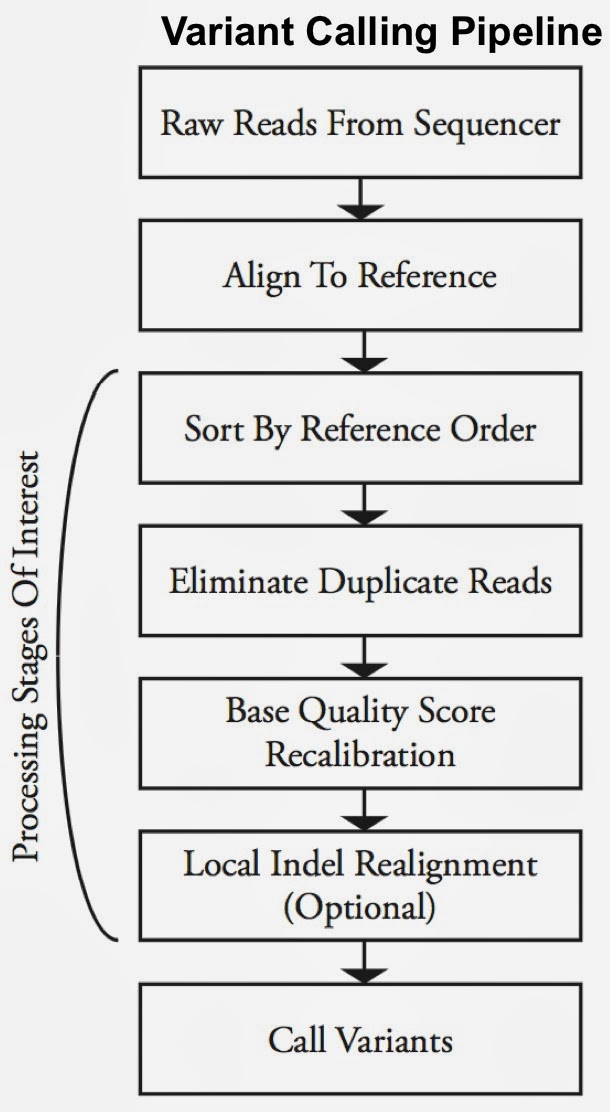
Very early on the designers of ADAM realized that a well-designed data schema (that specifies the representation of data when it is accessed) was key to having a system that could leverage existing big data tools. The ADAM format uses the Apache Avro data serialization system and comes with a human-readable schema that can be accessed using many programming languages (including C/C++/C#, Java/Scala, php, Python, Ruby). ADAM also includes a data format/access API implemented on top of Apache Avro and Parquet, and a data transformation API implemented on top of Apache Spark. Because it’s built with widely adopted tools, ADAM users can leverage components of the Hadoop (Impala, Hive, MapReduce) and BDAS (Shark, Spark, GraphX, MLbase) stacks for interactive and advanced analytics.
A compelling family of DSLs for Data Science
The Delite framework has produced high-performance languages that target data scientists
An important reason why pydata tools and Spark appeal to data scientists is that they both cover many data science tasks and workloads (Spark users can move seamlessly between batch and streaming). Being able to use the same programming style and syntax for workflows that span a variety of tasks is a huge productivity boost. In the case of Spark (and Hadoop), the emergence of a variety of scalable analytic engines have made distributed computing applications much easier to build.
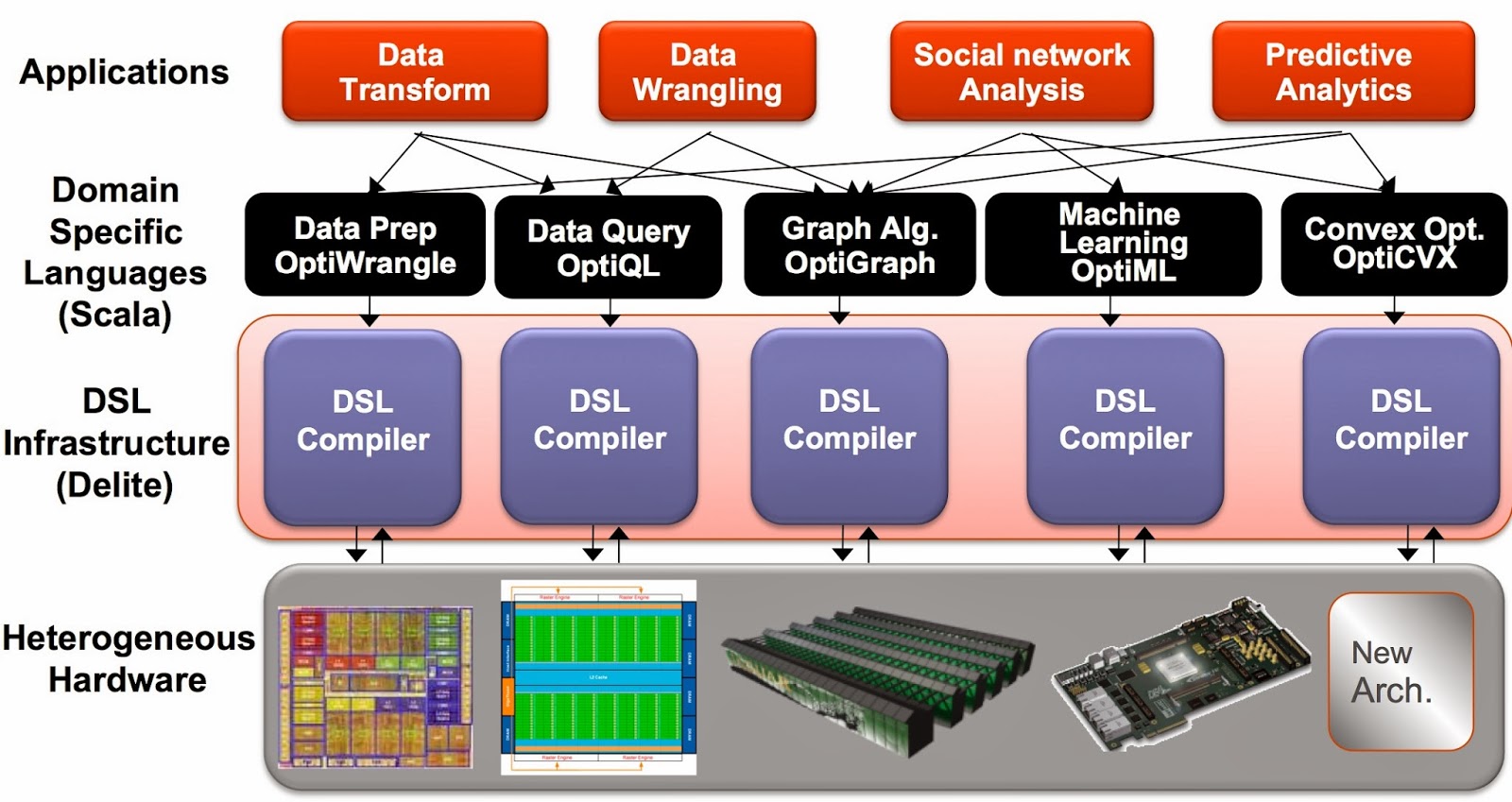
Delite: a framework for embedded, parallel, and high-performance DSLs
Another way to boost productivity is to use a family of high-performance languages that cover many data science tasks. Ideally you want languages that allow programmers to focus on applications (not on low-level details of parallel programming) and that can run efficiently on different machines and architectures1 (CPU, GPU). And just like pydata and Spark, syntax and context-switching shouldn’t get in the way of tackling complex data science workflows.
The Delite framework from Stanford’s Pervasive Parallelism Lab (PPL) has been used to produce a family of high-performance domain specific languages (DSLs) that target different data analysis tasks. DSLs are programming languages2 with restricted expressiveness (for a particular domain) and tend to be high-level in nature (they are often declarative and deterministic). Delite is a compiler and runtime infrastructure that allows language designers to use aggressive, domain-specific optimizations to deliver high-performance DSLs. Using Delite, the team at Stanford produced DSLs embedded in a functional language (Scala) with performance results comparable to hand-optimized implementations (e.g. MATLAB, LINQ) across different domains.
Expanding options for mining streaming data
New tools make it easier for companies to process and mine streaming data sources
Stream processing was in the minds of a few people that I ran into over the past week. A combination of new systems, deployment tools, and enhancements to existing frameworks, are behind the recent chatter. Through a combination of simpler deployment tools, programming interfaces, and libraries, recently released tools make it easier for companies to process and mine streaming data sources.
Of the distributed stream processing systems that are part of the Hadoop ecosystem0, Storm is by far the most widely used (more on Storm below). I’ve written about Samza, a new framework from the team that developed Kafka (an extremely popular messaging system). Many companies who use Spark express interest in using Spark Streaming (many have already done so). Spark Streaming is distributed, fault-tolerant, stateful, and boosts programmer productivity (the same code used for batch processing can, with minor tweaks, be used for realtime computations). But it targets applications that are in the “second-scale latencies”. Both Spark Streaming and Samza have their share of adherents and I expect that they’ll both start gaining deployments in 2014.