"workflow" entries

The importance of orchestration in transforming legacy IT
How orchestration differs from automation in the enterprise cloud.

Buy The Enterprise Cloud.
The orchestration of workflow processes is an essential part of cloud computing. Without orchestration, many of the benefits and characteristics of cloud computing cannot be achieved at the price point that cloud services should be offered. Failure to automate as many processes as possible results in higher personnel labor costs, slower time to deliver the new service to customers, and ultimately higher cost with less reliability.
What is meant by automation? Automation is technique used in traditional data centers —and critical in a cloud environment — to install software or initiate other activities. Traditional IT administrators use sequential scripts to perform a series of tasks (e.g. software installation or configuration); however, this is now considered an antiquated technique in a modern cloud-based environment. Orchestration differs from automation in that it does not rely entirely on static sequential scripts but rather sophisticated workflows; multiple automated threads; query-based and if/then logic; object-oriented and topology workflows; and even the ability to back-out a series of automated commands if necessary.
Orchestration can best be explained through a typical use case example of a customer placing an order within their cloud service web-portal, and following the steps necessary to bring the service online. The actions below illustrate a very high level scenario where the cloud management software performs the orchestration:

How to build up to good CSS
Avoid problems associated with a quick fix by creating a stable workflow.

A long time ago (circa 1999) a creative director tried very hard to convince me how great working in print design was compared to web design. One afternoon before a big event for a Fortune 100 company, she showed me an invitation her team had been working on for the past 2 weeks. It had folds, panels, and colors that would wow anyone. It had just come back from the printing press and she was excited to show me how amazing it was. She began reading me the big invitation title first — to her horror she found that there was a spelling mistake on the cover. The entire set of 10,000 invites would have to be thrown in the trash and at the cost of $15,000 — that would be hard mistake to swallow. She was speechless.
My response to what had just happened was this…”That’s why I like designing for the web. I would have been able to change that spelling mistake in 5 minutes…”
At that point in the web’s history anyone with a web connection, an FTP program and a text editor could edit HTML code on the fly. It really was the wild wild west of web development — this was the web’s best and worst attribute. For many young developers and designers it gave us a chance to create, edit, and publish web pages as fast as we could code them.

Streamlining feature engineering
Researchers and startups are building tools that enable feature discovery.
Why do data scientists spend so much time on data wrangling and data preparation? In many cases it’s because they want access to the best variables with which to build their models. These variables are known as features in machine-learning parlance. For many0 data applications, feature engineering and feature selection are just as (if not more important) than choice of algorithm:
Good features allow a simple model to beat a complex model.
(to paraphrase Alon Halevy, Peter Norvig, and Fernando Pereira)
The terminology can be a bit confusing, but to put things in context one can simplify the data science pipeline to highlight the importance of features:
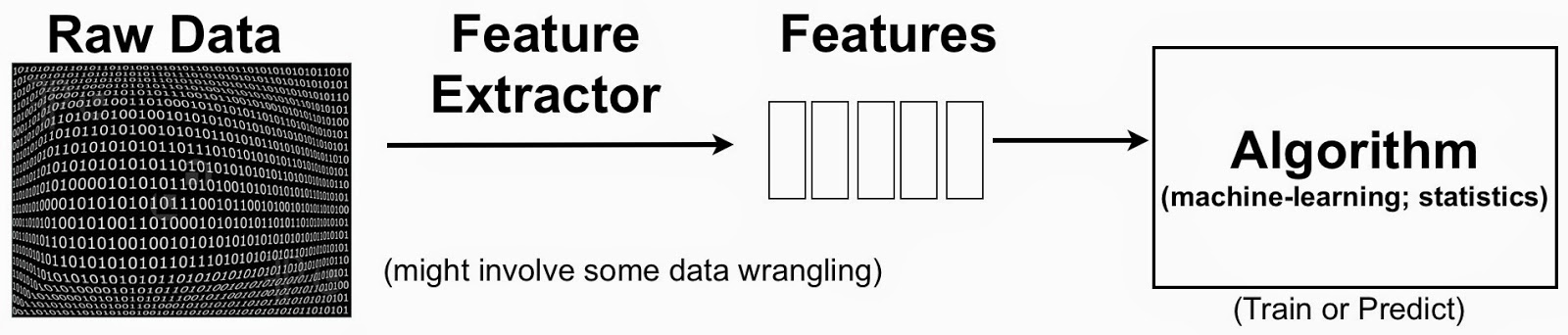
Feature Engineering or the Creation of New Features
A simple example to keep in mind is text mining. One starts with raw text (documents) and extracted features could be individual words or phrases. In this setting, a feature could indicate the frequency of a specific word or phrase. Features1 are then used to classify and cluster documents, or extract topics associated with the raw text. The process usually involves the creation2 of new features (feature engineering) and identifying the most essential ones (feature selection).
Instrumenting collaboration tools used in data projects
Built-in audit trails can be useful for reproducing and debugging complex data analysis projects
As I noted in a previous post, model building is just one component of the analytic lifecycle. Many analytic projects result in models that get deployed in production environments. Moreover, companies are beginning to treat analytics as mission-critical software and have real-time dashboards to track model performance.
Once a model is deemed to be underperforming or misbehaving, diagnostic tools are needed to help determine appropriate fixes. It could well be models need to be revisited and updated, but there are instances when underlying data sources1 and data pipelines are what need to be fixed. Beyond the formal systems put in place specifically for monitoring analytic products, tools for reproducing data science workflows could come in handy.
Interface Languages and Feature Discovery
It's easier to "discover" features with tools that have broad coverage of the data science workflow
Here are a few more observations based on conversations I had during the just concluded Strata Santa Clara conference.
Interface languages: Python, R, SQL (and Scala)
This is a great time to be a data scientist or data engineer who relies on Python or R. For starters there are developer tools that simplify setup, package installation, and provide user interfaces designed to boost productivity (RStudio, Continuum, Enthought, Sense).
Increasingly, Python and R users can write the same code and run it against many different execution1 engines. Over time the interface languages will remain constant but the execution engines will evolve or even get replaced. Specifically there are now many tools that target Python and R users interested in implementations of algorithms that scale to large data sets (e.g., GraphLab, wise.io, Adatao, H20, Skytree, Revolution R). Interfaces for popular engines like Hadoop and Apache Spark are also available – PySpark users can access algorithms in MLlib, SparkR users can use existing R packages.
In addition many of these new frameworks go out of their way to ease the transition for Python and R users. wise.io “… bindings follow the Scikit-Learn conventions”, and as I noted in a recent post, with SFrames and Notebooks GraphLab, Inc. built components2 that are easy for Python users to learn.
IPython: A unified environment for interactive data analysis
It has roots in academic scientific computing, but has features that appeal to many data scientists
As I noted in a recent post on reproducing data projects, notebooks have become popular tools for maintaining, sharing, and replicating long data science workflows. Much of that is due to the popularity of IPython1. In development since 2001, IPython grew out of the scientific computing community and has slowly added features that appeal to data scientists.
Roots in academic scientific computing
As IPython creator Fernando Perez noted in his “historical retrospective”, exploratory analysis in a scientific setting requires a solid interactive environment. After years of development IPython has become a great tool for interacting with data. IPython also addresses other important pain points for scientists – reproducibility and collaboration – issues that are equally important to data scientists working in industry.
IPython is more than just Python
With an interactive widget architecture that’s 100% language-agnostic, these days IPython is used by many other programming language communities2, including Julia, Haskell, F#, Ruby, Go, and Scala. If you’re a data scientist who likes to mix-and-match languages, you can create, maintain, and share multi-language data projects in IPython:
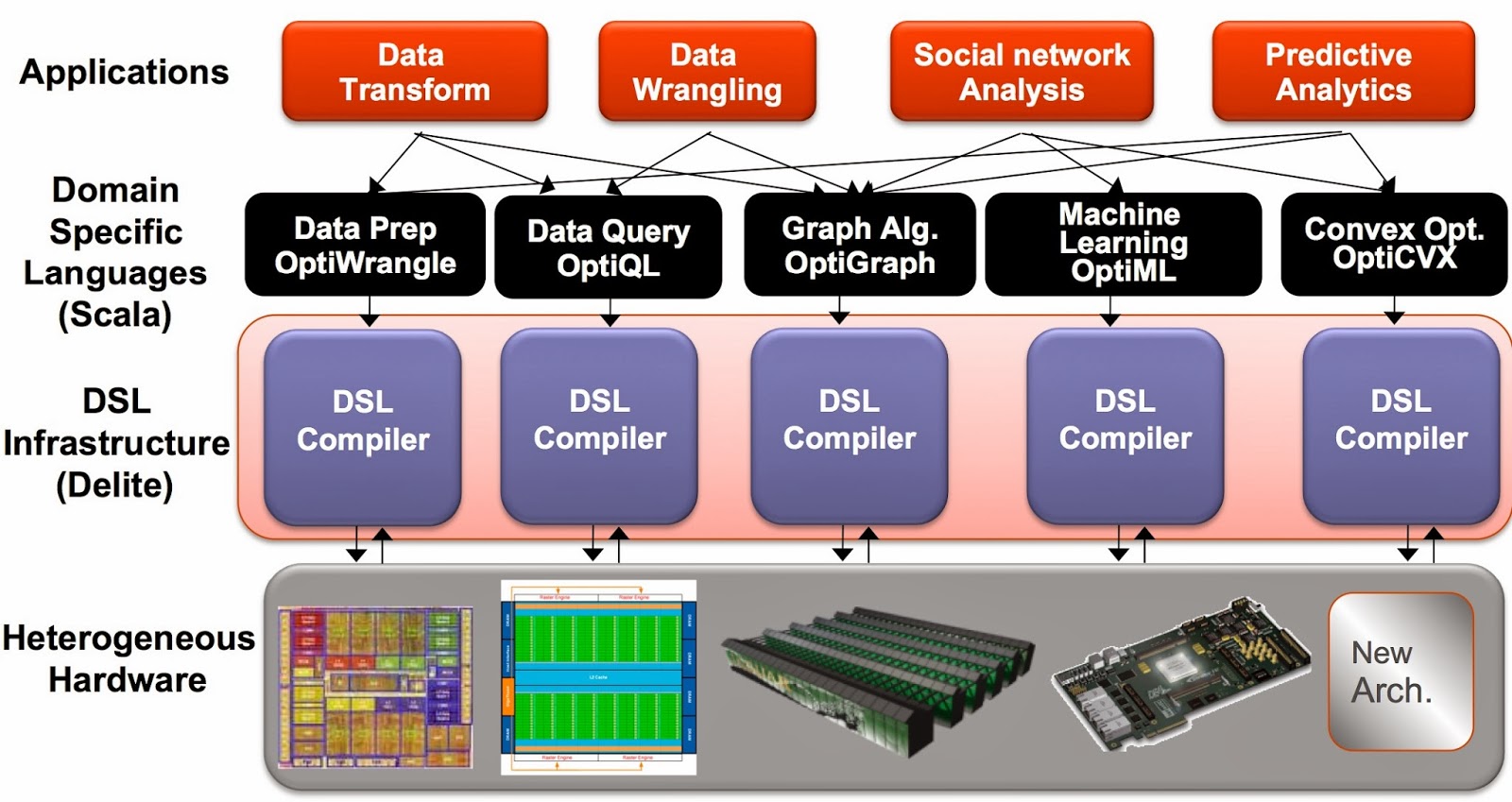
A compelling family of DSLs for Data Science
The Delite framework has produced high-performance languages that target data scientists
An important reason why pydata tools and Spark appeal to data scientists is that they both cover many data science tasks and workloads (Spark users can move seamlessly between batch and streaming). Being able to use the same programming style and syntax for workflows that span a variety of tasks is a huge productivity boost. In the case of Spark (and Hadoop), the emergence of a variety of scalable analytic engines have made distributed computing applications much easier to build.
Delite: a framework for embedded, parallel, and high-performance DSLs
Another way to boost productivity is to use a family of high-performance languages that cover many data science tasks. Ideally you want languages that allow programmers to focus on applications (not on low-level details of parallel programming) and that can run efficiently on different machines and architectures1 (CPU, GPU). And just like pydata and Spark, syntax and context-switching shouldn’t get in the way of tackling complex data science workflows.
The Delite framework from Stanford’s Pervasive Parallelism Lab (PPL) has been used to produce a family of high-performance domain specific languages (DSLs) that target different data analysis tasks. DSLs are programming languages2 with restricted expressiveness (for a particular domain) and tend to be high-level in nature (they are often declarative and deterministic). Delite is a compiler and runtime infrastructure that allows language designers to use aggressive, domain-specific optimizations to deliver high-performance DSLs. Using Delite, the team at Stanford produced DSLs embedded in a functional language (Scala) with performance results comparable to hand-optimized implementations (e.g. MATLAB, LINQ) across different domains.
Reproducing Data Projects
Popular approaches for reproducing, managing, and deploying complex data projects
As I talk to people and companies building the next generation of tools for data scientists, collaboration and reproducibility keep popping up. Collaboration is baked into many of the newer tools I’ve seen (including ones that have yet to be released). Reproducibility is a different story. Many data science projects involve a series of interdependent steps, making auditing or reproducing1 them a challenge. How data scientists and engineers reproduce long data workflows depends on the mix of tools they use.
Scripts
The default approach is to create a set of well-documented programs and scripts. Documentation is particularly important if several tools and programming languages are involved in a data science project. It’s worth pointing out that the generation of scripts need not be limited to programmers: some tools that rely on users executing tasks through a GUI also generate scripts for recreating data analysis and processing steps. A recent example is the DataWrangler project, but this goes back to Excel users recording VBA macros.
Data Wrangling gets a fresh look
We are in the early days of productivity technology in data science
Data analysts have long lamented the amount of time they spend on data wrangling. Rightfully so, as some estimates suggest they spend a majority of their time on it. The problem is compounded by the fact that these days, data scientists are encouraged to cast their nets wide, and investigate alternative (unstructured) data sources. The general perception is that data wrangling is the province of programmers and data scientists. Spend time around Excel users and you’ll learn that they do quite a bit of data wrangling too!
In my work I tend to write scripts and small programs to do data wrangling. That usually means some combination1 of SQL, Python, and Spark2. I’ve played with Google Refine (now called OpenRefine) in the past, but I found the UI hard to get used to. Part of the problem may have been that I didn’t use the tool often3 enough to become comfortable.
For most users data wrangling still tends to mean a series of steps that usually involves different tools (e.g., you often need to draw charts to spot outliers and anomalies). As I’ve pointed out in previous posts, workflows that involve many different tools require a lot of context-switching, which in turn affects productivity and impedes reproducability.
We are washing our data at the side of the river on stones. We are really in the early, early ages of productivity technology in data science.
Joe Hellerstein (Strata-NYC 2012), co-founder and CEO of Trifacta
Running batch and long-running, highly available service jobs on the same cluster
Moving different workloads and frameworks onto the same collection of machines increases efficiency and ROI
As organizations increasingly rely on large computing clusters, tools for leveraging and efficiently managing compute resources become critical. Specifically, tools that allow multiple services and frameworks run on the same cluster can significantly increase utilization and efficiency. Schedulers1 take into account policies and workloads to match jobs with appropriate resources (e.g., memory, storage, processing power) in a large compute cluster. With the help of schedulers, end users begin thinking of a large cluster as a single resource (like “a laptop”) that can be used to run different frameworks (e.g., Spark, Storm, Ruby on Rails, etc.).
Multi-tenancy and efficient utilization translates into improved ROI. Google’s scheduler, Borg, has been in production for many years and has led to substantial savings2. The company’s clusters handle a variety of workloads that can be roughly grouped into batch (compute something, then finish) and services (web or infrastructure services like BigTable). Researchers recently examined traces from several Google clusters and observed that while “batch jobs” accounted for 80% of all jobs, “long service jobs” utilize 55-60% of resources.
There are other benefits of multi-tenancy. Being able to run analytics (batch, streaming) and long running services (e.g., web applications) on the same cluster significantly lowers latency3, opening up the possibility for real-time, analytic applications. Bake-offs can be done more effectively as competing tools, versions, and frameworks can be deployed on the same cluster. Data scientists and production engineers leverage the same compute resources, making it easier for teams to work together across the analytic lifecycle. An additional benefit is that data science teams learn to build products and services that factor in efficient utilization and availability.
Mesos, Chronos, and Marathon
Apache Mesos is a popular open source scheduler that originated from UC Berkeley’s AMPlab. Mesos is based on features in modern kernels for resource isolation (cgroups in Linux). It has been in production for a few years at Twitter4, airbnb5, and many other companies – AMPlab simulations showed Mesos comfortably handling clusters with 30K servers.